Índice
Instalado via NuGet
PM> Install-Package Spire.PDF
Links Relacionados
Os documentos PDF têm layout fixo e não permitem que os usuários façam modificações neles. Para tornar o conteúdo PDF editável novamente, você pode converter PDF para Word ou extraia texto de PDF. Neste artigo você aprenderá como extrair texto de uma página PDF específica, como extrair texto de uma área retangular específica, e como extraia texto por SimpleTextExtractionStrategy em C# e VB.NET usando Spire.PDF for .NET.
- Extraia texto de uma página específica
- Extrair texto de um retângulo
- Extraia texto usando SimpleTextExtractionStrategy
Instale o Spire.PDF for .NET
Para começar, você precisa adicionar os arquivos DLL incluídos no pacote Spire.PDF for.NET como referências em seu projeto .NET. Os arquivos DLL podem ser baixados deste link ou instalados via NuGet.
PM> Install-Package Spire.PDF
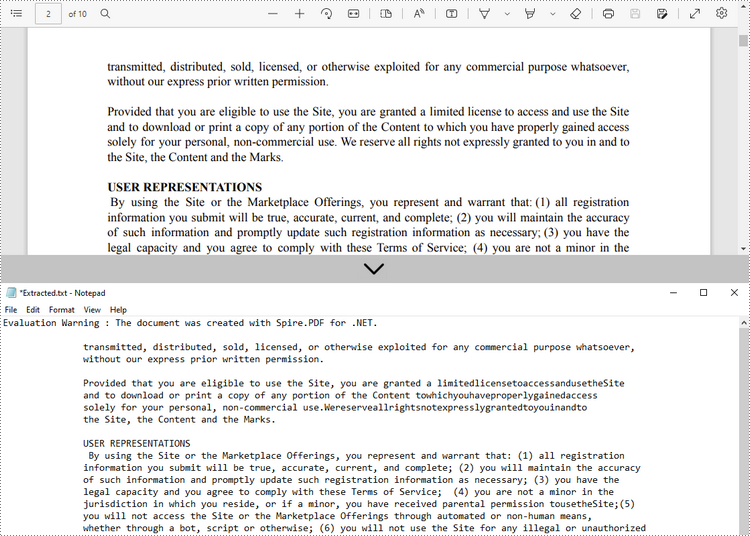
Extraia texto de uma página específica
A seguir estão as etapas para extrair texto de uma determinada página de um documento PDF usando Spire.PDF for .NET.
- Crie um objeto PdfDocument.
- Carregue um arquivo PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página específica por meio da propriedade PdfDocument.Pages[index].
- Crie um objeto PdfTextExtractor.
- Crie um objeto PdfTextExtractOptions e defina a propriedade IsExtractAllText como true.
- Extraia o texto da página selecionada usando o método PdfTextExtractor.ExtractText().
- Escreva o texto extraído em um arquivo TXT.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
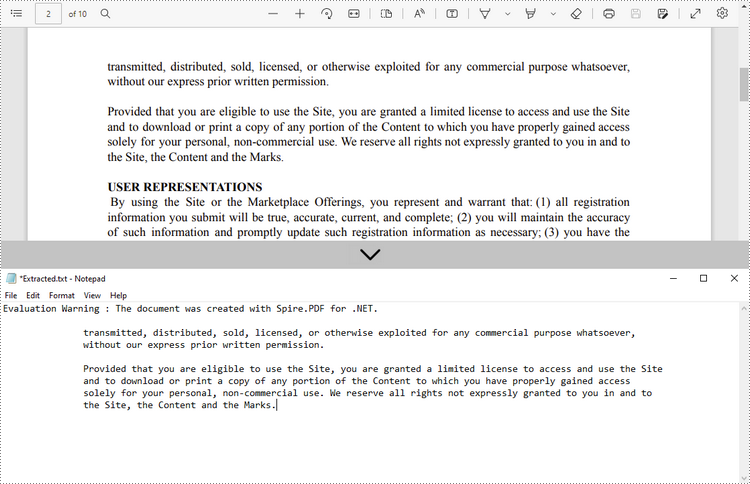
Extrair texto de um retângulo
A seguir estão as etapas para extrair texto de uma área retangular de uma página usando Spire.PDF for .NET.
- Crie um objeto PdfDocument.
- Carregue um arquivo PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página específica por meio da propriedade PdfDocument.Pages[index].
- Crie um objeto PdfTextExtractor.
- Crie um objeto PdfTextExtractOptions e especifique a área do retângulo por meio da propriedade ExtractArea dele.
- Extraia o texto do retângulo usando o método PdfTextExtractor.ExtractText().
- Escreva o texto extraído em um arquivo TXT.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
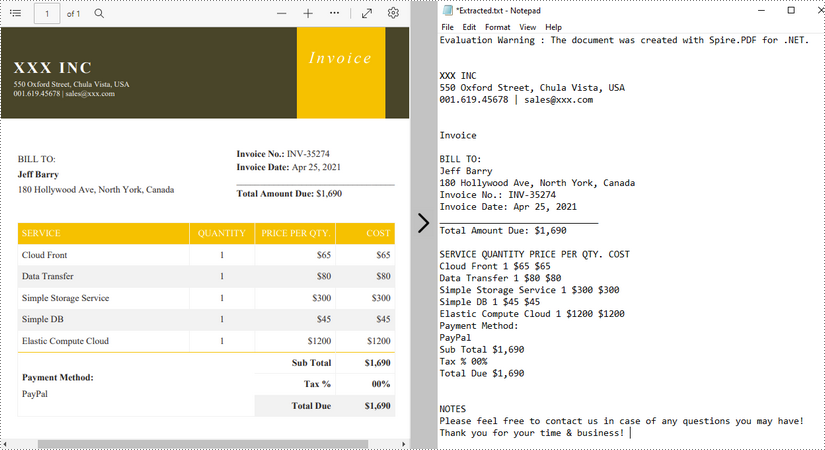
Extraia texto usando SimpleTextExtractionStrategy
Os métodos acima extraem texto linha por linha. Ao extrair texto usando SimpleTextExtractionStrategy, ele rastreia a posição Y atual de cada string e insere uma quebra de linha na saída se a posição Y tiver mudado. A seguir estão as etapas detalhadas.
- Crie um objeto PdfDocument.
- Carregue um arquivo PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página específica por meio da propriedade PdfDocument.Pages[index].
- Crie um objeto PdfTextExtractor.
- Crie um objeto PdfTextExtractOptions e defina a propriedade IsSimpleExtraction como true.
- Extraia o texto da página selecionada usando o método PdfTextExtractor.ExtractText().
- Escreva o texto extraído em um arquivo TXT.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Solicite uma licença temporária
Se desejar remover a mensagem de avaliação dos documentos gerados ou se livrar das limitações de função, por favor solicite uma licença de teste de 30 dias para você mesmo.
