Instalado via NuGet
PM> Install-Package Spire.PDF
Links Relacionados
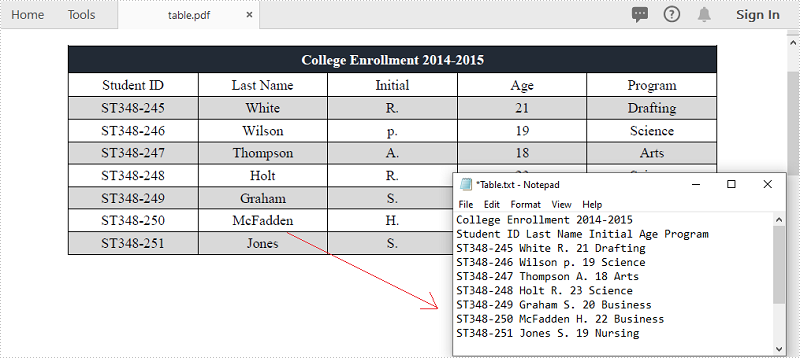
O PDF é um dos formatos de documento mais populares para compartilhar e gravar dados. Você pode encontrar a situação em que precisa extrair dados de documentos PDF, especialmente os dados em tabelas. Por exemplo, há informações úteis armazenadas nas tabelas de suas faturas em PDF e você deseja extrair os dados para análise ou cálculo posterior. Este artigo demonstra como extrair dados de tabelas PDF e salve-o em um arquivo TXT usando Spire.PDF for .NET.
Instalar o Spire.PDF for .NET
Para começar, você precisa adicionar os arquivos DLL incluídos no pacote Spire.PDF for.NET como referências em seu projeto .NET. Os arquivos DLLs podem ser baixados deste link ou instalados via NuGet.
- Package Manager
PM> Install-Package Spire.PDF
Extrair dados de tabelas PDF
A seguir estão as principais etapas para extrair tabelas de um documento PDF.
- Crie uma instância da classe PdfDocument.
- Carregue o documento PDF de amostra usando o método PdfDocument.LoadFromFile().
- Extraia tabelas de uma página específica usando o método PdfTableExtractor.ExtractTable(int pageIndex).
- Obtenha o texto de uma determinada célula da tabela usando o método PdfTable.GetText(int rowIndex, int columnIndex).
- Salve os dados extraídos em um arquivo .txt.
- C#
- VB.NET
using System.IO;
using System.Text;
using Spire.Pdf;
using Spire.Pdf.Utilities;
namespace ExtractPdfTable
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load the sample PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\table.pdf");
//Create a StringBuilder object
StringBuilder builder = new StringBuilder();
//Initialize an instance of PdfTableExtractor class
PdfTableExtractor extractor = new PdfTableExtractor(doc);
//Declare a PdfTable array
PdfTable[] tableList = null;
//Loop through the pages
for (int pageIndex = 0; pageIndex < doc.Pages.Count; pageIndex++)
{
//Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex);
//Determine if the table list is null
if (tableList != null && tableList.Length > 0)
{
//Loop through the table in the list
foreach (PdfTable table in tableList)
{
//Get row number and column number of a certain table
int row = table.GetRowCount();
int column = table.GetColumnCount();
//Loop though the row and colunm
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
//Get text from the specific cell
string text = table.GetText(i, j);
//Add text to the string builder
builder.Append(text + " ");
}
builder.Append("\r\n");
}
}
}
}
//Write to a .txt file
File.WriteAllText("Table.txt", builder.ToString());
}
}
}
Imports System.IO
Imports System.Text
Imports Spire.Pdf
Imports Spire.Pdf.Utilities
Namespace ExtractPdfTable
Class Program
Shared Sub Main(ByVal args() As String)
'Create a PdfDocument object
Dim doc As PdfDocument = New PdfDocument()
'Load the sample PDF file
doc.LoadFromFile("C:\Users\Administrator\Desktop\table.pdf")
'Create a StringBuilder object
Dim builder As StringBuilder = New StringBuilder()
'Initialize an instance of PdfTableExtractor class
Dim extractor As PdfTableExtractor = New PdfTableExtractor(doc)
'Declare a PdfTable array
Dim tableList() As PdfTable = Nothing
'Loop through the pages
Dim pageIndex As Integer
For pageIndex = 0 To doc.Pages.Count- 1 Step pageIndex + 1
'Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex)
'Determine if the table list is null
If tableList <> Nothing And tableList.Length > 0 Then
'Loop through the table in the list
Dim table As PdfTable
For Each table In tableList
'Get row number and column number of a certain table
Dim row As Integer = table.GetRowCount()
Dim column As Integer = table.GetColumnCount()
'Loop though the row and colunm
Dim i As Integer
For i = 0 To row- 1 Step i + 1
Dim j As Integer
For j = 0 To column- 1 Step j + 1
'Get text from the specific cell
Dim text As String = table.GetText(i,j)
'Add text to the string builder
builder.Append(text + " ")
Next
builder.Append("\r\n")
Next
Next
End If
Next
'Write to a .txt file
File.WriteAllText("Table.txt", builder.ToString())
End Sub
End Class
End Namespace
Solicitar uma licença temporária
Se você deseja remover a mensagem de avaliação dos documentos gerados ou se livrar das limitações de função, por favor solicite uma licença de teste de 30 dias para você mesmo.
