Na era digital de hoje, extrair texto de imagens ou PDFs digitalizados é um requisito comum para diversas aplicações. O reconhecimento óptico de caracteres (OCR) é uma tecnologia que permite aos computadores reconhecer e extrair texto de tais documentos. Com ele, podemos converter facilmente imagens e PDFs digitalizados em formatos editáveis e pesquisáveis, facilitando o processamento e a análise do conteúdo textual. Neste blog, exploraremos como extraia texto de imagens e PDFs digitalizados com OCR em C#.
- Extraia texto de imagens em C#
- Extraia texto de imagens com coordenadas em C#
- Extraia texto de PDFs digitalizados em C#
Bibliotecas C# para extrair texto de imagens e PDFs digitalizados
Para extrair texto de imagens, utilizaremos o Spire.OCR for .NET biblioteca. Spire.OCR for .NET é uma biblioteca poderosa projetada especificamente para extrair texto de imagens em aplicativos .NET. Suporta vários formatos de imagem, como BMP, JPG, PNG, TIFF e GIF.
Aqui estão as etapas para instalar o Spire.OCR for .NET:
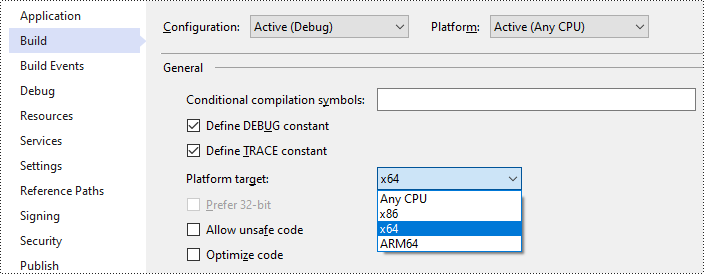
- Altere o destino da plataforma da sua solução para x64.
- Instale o Spire.OCR do NuGet executando o seguinte comando no Console do Gerenciador de Pacotes NuGet:
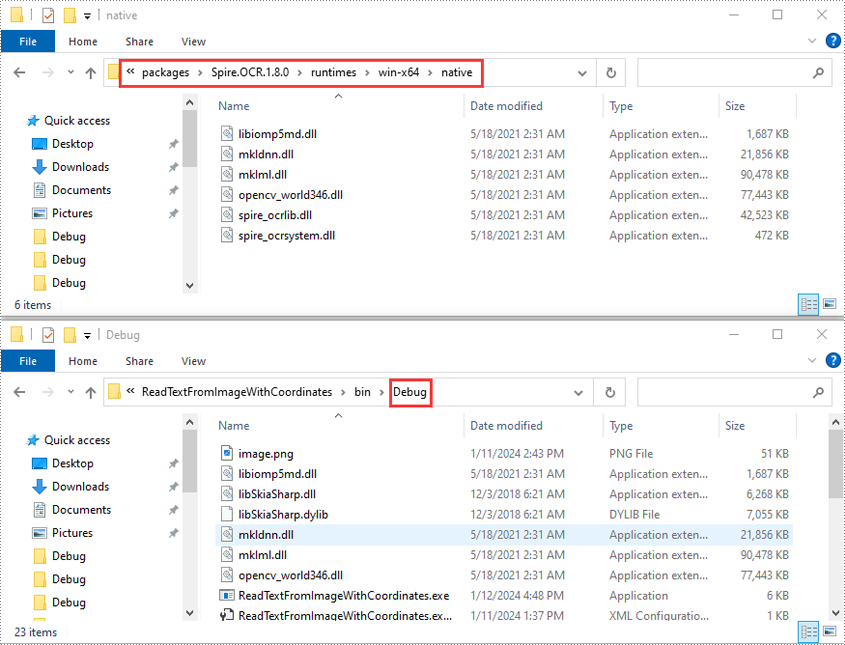
- Abra a pasta da solução e navegue até o diretório "packages\Spire.OCR.1.8.0\runtimes\win-x64\native". Copie os arquivos DLL deste diretório e cole-os na pasta “Debug” da sua solução.
Install-Package Spire.OCR
Para extrair texto de PDFs digitalizados, primeiro precisamos converter o documento PDF em imagens. Para esta tarefa, empregaremos a biblioteca Spire.PDF for .NET. Assim que a conversão for concluída, podemos utilizar Spire.OCR para extrair texto das imagens resultantes.
Você pode instalar o Spire.PDF for .NET do NuGet executando o seguinte comando no Console do Gerenciador de Pacotes NuGet:
Install-Package Spire.PDF
Extraia texto de imagens em C#
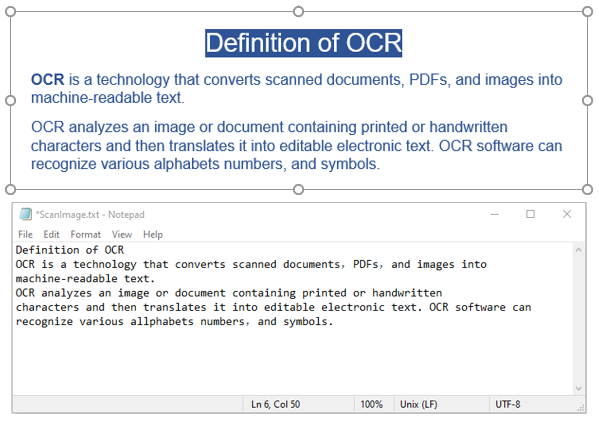
Spire.OCR fornece o método OcrScanner.Scan() para reconhecer texto de uma imagem. Após o reconhecimento, você pode obter o texto reconhecido usando a propriedade OcrScanner.Text.
Aqui estão as principais etapas para reconhecer texto de uma imagem usando Spire.OCR:
- Crie uma instância da classe OcrScanner.
- Reconheça o texto de uma imagem usando o método OcrScanner.Scan().
- Obtenha o texto reconhecido do objeto OcrScanner usando a propriedade OcrScanner.Text.
- Salve o texto em um arquivo de texto.
Aqui está um exemplo de código que mostra como reconhecer o texto de uma imagem e salvar o resultado em um arquivo de texto:
- C#
using Spire.OCR;
using System.IO;
namespace ReadTextFromImage
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imageFilePath = "Image.png";
//Specify the path of the output text file
string outputFilePath = "ScanImage.txt";
//Call the ScanTextFromImage method to scan text from an image
string scannedText = ScanTextFromImage(imageFilePath);
//Write the text to the specified file
File.WriteAllText(outputFilePath, scannedText);
}
public static string ScanTextFromImage(string imageFilePath)
{
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the recognized text from the OcrScanner object
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Extraia texto de imagens com coordenadas em C#
A extração de coordenadas é útil quando você precisa identificar a localização exata de elementos de texto específicos em sua imagem. Com o Spire.OCR, você pode recuperar o texto reconhecido em blocos ou linhas. Para cada bloco, você pode obter informações detalhadas de localização, incluindo as coordenadas xey, bem como sua largura e altura.
Aqui estão as etapas principais para extrair texto junto com suas informações de localização de uma imagem usando Spire.OCR:
- Crie uma instância da classe OcrScanner.
- Reconheça o texto de uma imagem usando o método OcrScanner.Scan().
- Obtenha o texto reconhecido do objeto OcrScanner usando a propriedade OcrScanner.Text.
- Itere pelos blocos de texto do texto reconhecido.
- Para cada bloco, obtenha suas informações de texto e localização usando as propriedades IOCRTextBlock.Text e IOCRTextBlock.Box e anexe o resultado a uma lista de strings.
- Salve o conteúdo da lista em um arquivo de texto.
Aqui está um exemplo de código que mostra como reconhecer texto junto com suas informações de localização de uma imagem e salvar o resultado em um arquivo de texto:
- C#
using Spire.OCR;
using System.Collections.Generic;
using System.IO;
namespace ReadTextFromImageWithCoordinates
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imagePath = "Image.png";
//Specify the path of the output text file
string outputFile = "ScanImageWithCoordinates.txt";
//Call the ScanTextFromImageWithCoordinates method to extract text and its area information from the image
List<string> extractedText = ScanTextFromImageWithCoordinates(imagePath);
//Write the result to the specified file
File.WriteAllLines(outputFile, extractedText);
}
//Retrieve the text blocks along with their location information (x, y, width, height) from an image
public static List<string> ScanTextFromImageWithCoordinates(string imageFilePath)
{
//Create a list
List<string> extractedText = new List<string>();
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the scanned text
IOCRText text = ocrScanner.Text;
//Iterate through each text block
foreach (IOCRTextBlock block in text.Blocks)
{
//Append the text of each block and its location information to the list
extractedText.Add($"Text: {block.Text}\nRectangular Area: {block.Box}");
}
}
return extractedText;
}
}
}
Extraia texto de PDFs digitalizados em C#
Para extrair texto de PDFs digitalizados, precisamos seguir um processo de duas etapas. Primeiro, usamos o Spire.PDF para converter os PDFs digitalizados em imagens. Em seguida, utilizamos Spire.OCR para extrair o texto dessas imagens.
Aqui estão as principais etapas para reconhecer texto de um PDF digitalizado usando Spire.PDF e Spire.OCR:
- Crie uma instância da classe PdfDocument.
- Carregue um documento PDF usando o método PdfDocument.LoadFromFile().
- Itere pelas páginas do documento PDF.
- Converta cada página em um objeto Image usando o método PdfDocument.SaveAsImage().
- Salve o objeto Image em um stream usando o método Image.Save().
- Crie uma instância da classe OcrScanner.
- Reconheça o texto do fluxo usando o método OcrScanner.Scan().
- Obtenha o texto reconhecido usando a propriedade IOCRText.Text e anexe-o a uma lista de strings.
- Salve o conteúdo da lista em um arquivo de texto.
Aqui está um exemplo de código que mostra como reconhecer texto de um PDF digitalizado e salvar o resultado em um arquivo de texto:
- C#
using Spire.OCR;
using Spire.Pdf;
using System.Collections.Generic;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
namespace ReadTextFromScannedPDF
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the scanned PDF file
string pdfFilePath = "Sample.pdf";
//Specify the path of the output text file
string outputFilePath = "ScanPDF.txt";
//Extract text from the scanned PDF
List<string> extractedText = ExtractTextFromScannedPDF(pdfFilePath);
//Write the text to the specified file
File.WriteAllLines(outputFilePath, extractedText);
}
//Extract text from a scanned PDF
public static List<string> ExtractTextFromScannedPDF(string pdfFilePath)
{
//Create a list to store the extracted text
List<string> extractedText = new List<string>();
//Create an instance of the PdfDocument class
using (PdfDocument document = new PdfDocument())
{
//Load the PDF document
document.LoadFromFile(pdfFilePath);
//Iterate through each page of the document
for (int pageIndex = 0; pageIndex < document.Pages.Count; pageIndex++)
{
//Convert the page to an image
using (Image image = document.SaveAsImage(pageIndex, 300, 300))
{
//Create a memory stream to hold the image data
using (MemoryStream stream = new MemoryStream())
{
//Save the image to the memory stream in PNG format
image.Save(stream, ImageFormat.Png);
stream.Position = 0;
//Scan the text from the image and add it to the list
string text = ScanTextFromImageStream(stream);
extractedText.Add(text);
}
}
}
}
//Return the list
return extractedText;
}
//Scan text from an image stream
public static string ScanTextFromImageStream(Stream stream)
{
//Create an instance of the OcrScanner class
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan the text from the image stream in PNG format
ocrScanner.Scan(stream, OCRImageFormat.Png);
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Obtenha uma licença gratuita
Para experimentar totalmente os recursos do Spire.OCR for .NET ou Spire.PDF for .NET sem quaisquer limitações de avaliação, você pode solicitar uma licença de teste gratuita de 30 dias.
Conclusão
Esta postagem do blog demonstrou como extrair texto de imagens e documentos PDF digitalizados em C#. Se você tiver alguma dúvida, sinta-se à vontade para publicá-la em nosso fórum ou enviá-la para nossa equipe de suporte por e-mail.
