Sommario
Installa con Pip
pip install Spire.PDF
Link correlati
I file PDF sono una scelta popolare per la condivisione e la distribuzione di documenti, ma può essere piuttosto difficile estrarre e riutilizzare il contenuto PDF. Fortunatamente, convertire file PDF in HTML con Python offre un'eccellente soluzione per il recupero e il riutilizzo delle informazioni PDF, che migliora l'accessibilità, la ricercabilità e l'adattabilità. Inoltre, il formato HTML consente ai motori di ricerca di indicizzare il contenuto, aumentandone le probabilità di essere scoperto sul web. Inoltre, grazie alla flessibilità e alla facilità d'uso di Python, sia i principianti che gli sviluppatori esperti possono utilizzarlo Python per convertire PDF in HTML facilmente ed efficientemente.

Questo articolo si concentra su come convertire PDF in HTML nei programmi Python. Comprende principalmente i seguenti argomenti:
- Panoramica sulla conversione di PDF in HTML con Python
- Converti PDF in un singolo file HTML con codice Python
- Converti PDF in HTML con immagini separate utilizzando Python
- Converti PDF in più file HTML con Python
- Licenza gratuita e supporto tecnico
Panoramica sulla conversione di PDF in HTML con Python
Le estese API di Python offrono comodità per varie operazioni di elaborazione dei documenti PDF. Spire.PDF for Python è una delle potenti API in grado di eseguire varie operazioni sui documenti PDF, tra cui conversione, modifica e unire documenti PDF. Inoltre, la conversione di PDF in HTML con Python può essere implementata senza sforzo con questa API.
In Spire.PDF for Python, la classe PdfDocument rappresenta un documento PDF. Possiamo caricare un file PDF utilizzando il metodo LoadFromFile() in questa classe e salvare il documento in altri formati, come HTML, per ottenere una semplice conversione da PDF a HTML.
Inoltre, questa API fornisce anche il metodo SetConvertHtmlOptions() nella proprietà PdfDocument.ConversionOptions per impostare le opzioni di incorporamento dell'immagine durante la conversione. Di seguito sono riportati i parametri che possono essere passati a questo metodo per impostare il numero massimo di pagine, l'opzione di incorporamento SVG, l'opzione di incorporamento delle immagini e l'opzione di qualità SVG:
- useEmbeddedSvg (bool): se impostato su True, consente di incorporare SVG nel file HTML convertito. Il file HTML risultante includerà tutti gli elementi del documento PDF, comprese le immagini, in un unico file HTML.
- useEmbeddedImg (bool): se impostato su True, consente di incorporare immagini nel file HTML convertito. Questo parametro funziona solo se useEmbeddedSvg è impostato su False.
- maxPageOneFile (int): imposta il numero massimo di pagine da includere in un singolo file HTML. Se il PDF ha più pagine rispetto al numero specificato, verranno generati più file HTML, ciascuno contenente un sottoinsieme di pagine.
- useHighQualityEmbeddedSvg (bool): se impostato su True, garantisce l'utilizzo di versioni di alta qualità delle immagini SVG incorporate nel processo di conversione HTML.
Flusso di lavoro tipico della conversione di PDF in HTML in Python utilizzando Spire.PDF for Python:
- Crea un oggetto della classe PdfDocument e carica un documento PDF utilizzando il metodo PdfDocument.LoadFromFile(string fileName).
- Imposta le opzioni di conversione utilizzando il metodo PdfDocument.ConversionOptions.SetConvertHtmlOptions().
- Converti il documento in formato HTML e salvalo utilizzando il metodo PdfDocument.SaveToFile(string fileName, FileFormat.HTML).
Gli utenti possono scarica Spire.PDF for Python e importarlo nei loro progetti o installarlo con PyPI:
pip install Spire.PDF
Converti PDF in un singolo file HTML con codice Python
Questo esempio di codice mostra come convertire direttamente PDF in HTML con Python senza impostare alcuna opzione di conversione. In questo caso basterà caricare un file PDF con il metodo LoadFromFile e salvarlo come file HTML con il metodo SaveToFile. Il file HTML convertito sarà un singolo file HTML con immagini e altri elementi incorporati al suo interno.
Esempio di codice:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("G:/Documents/ARCHITECTURE.pdf")
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTML.html", FileFormat.HTML)
doc.Close()
Risultato della conversione:
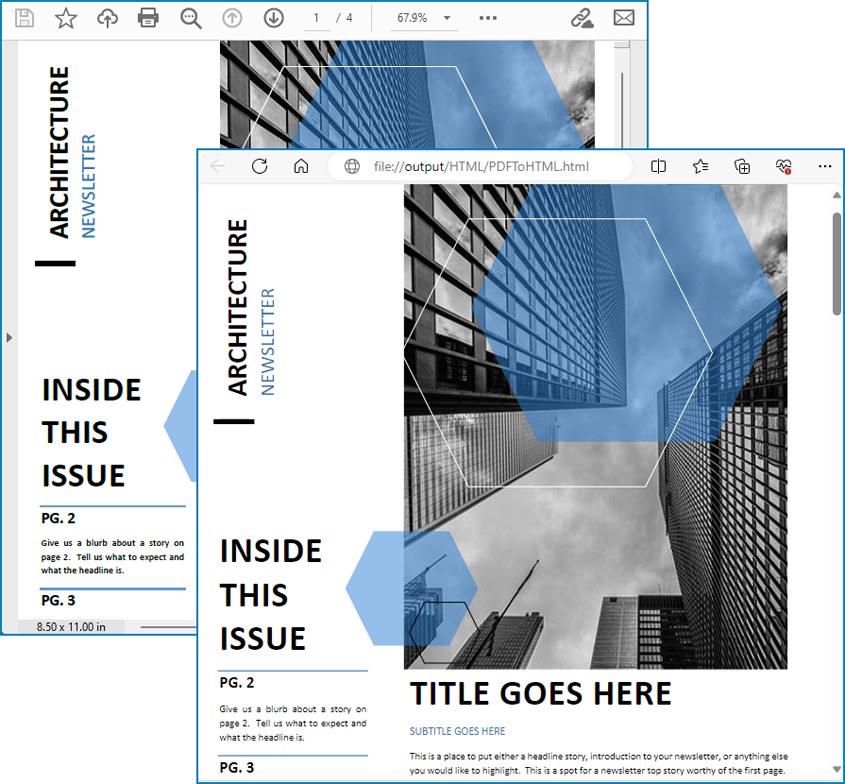
Converti PDF in HTML con immagini separate utilizzando Python
Impostando il parametro useEmbeddedSvg su False, possiamo convertire il documento PDF in un file HTML con immagini e file CSS separati da esso e archiviati in una cartella. Ciò rende conveniente modificare ulteriormente il file HTML convertito ed eseguire operazioni aggiuntive sulle immagini.
Esempio di codice:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLWithoutEmbeddingSVG.html", FileFormat.HTML)
doc.Close()
Risultato della conversione:
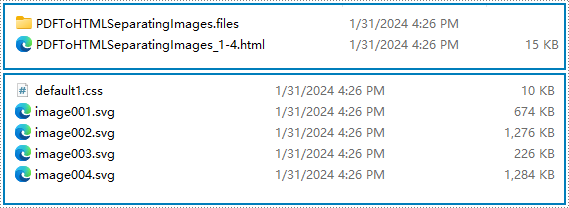
Converti PDF in più file HTML con Python
Con la precondizione che useEmbeddedSvg sia impostato su False, il metodo SetPdfToHtmlOptions consente l'utilizzo del parametro maxPageOneFile (int) per determinare il numero massimo di pagine incluse in ciascun file HTML convertito. Questa funzionalità consente Suddivisione di documenti PDF nel processo di conversione. Ad esempio, impostando il parametro su 1 ogni pagina verrà convertita in un file HTML separato.
Esempio di codice:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False, False, 1, False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLLimitingPage.html", FileFormat.HTML)
doc.Close()
Risultato della conversione:
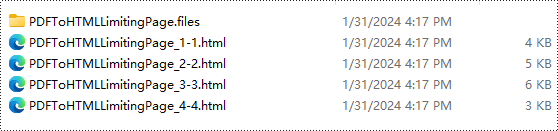
Licenza gratuita e supporto tecnico
Spire.PDF for Python offre agli utenti una licenza di prova gratuita per tutti gli utenti, inclusi sia gli utenti aziendali che quelli individuali. Richiedi una licenza temporanea per utilizzare questa API Python per convertire documenti PDF in file HTML, rimuovendo eventuali restrizioni di utilizzo o filigrane.
Per eventuali problemi riscontrati durante la conversione da PDF a HTML utilizzando questa API, gli utenti possono richiedere supporto tecnico sul forum Spire.PDF.
Conclusione
Questo articolo dimostra come convertire PDF in HTML utilizzando Python e fornisce varie opzioni di conversione, come la conversione in un singolo file HTML, la separazione dei file HTML dalle immagini e la divisione del documento PDF durante la conversione. Con Spire.PDF for Python, gli utenti hanno accesso a un metodo semplice ed efficiente per Python nella conversione da PDF a HTML, supportando opzioni di personalizzazione flessibili.
