Table des matières
Installer avec Pip
pip install Spire.PDF
Liens connexes
Les fichiers PDF sont un choix populaire pour le partage et la distribution de documents, mais il peut s'avérer assez difficile d'extraire et de réutiliser le contenu PDF. Heureusement, convertir des fichiers PDF en HTML avec Python offre une excellente solution pour la récupération et la réutilisation d'informations PDF, qui améliore l'accessibilité, la capacité de recherche et l'adaptabilité. De plus, le format HTML permet aux moteurs de recherche d'indexer le contenu, ce qui le rend plus susceptible d'être découvert sur le Web. De plus, grâce à la flexibilité et à la facilité d'utilisation de Python, les développeurs débutants et expérimentés peuvent utiliser Python pour convertir un PDF en HTML facilement et efficacement.

Cet article se concentre sur la façon de convertir un PDF en HTML dans les programmes Python. Il comprend principalement les thèmes suivants :
- Présentation de la conversion de PDF en HTML avec Python
- Convertir un PDF en un seul fichier HTML avec du code Python
- Convertir un PDF en HTML avec des images séparées à l'aide de Python
- Convertir un PDF en plusieurs fichiers HTML avec Python
- Licence gratuite et support technique
Présentation de la conversion de PDF en HTML avec Python
Les API étendues de Python facilitent diverses opérations de traitement de documents PDF. Spire.PDF for Python est l'une des API puissantes capables d'effectuer diverses opérations sur les documents PDF, notamment la conversion, l'édition et fusionner des documents PDF. Et la conversion de PDF en HTML avec Python peut être mise en œuvre sans effort avec cette API.
Dans Spire.PDF for Python, la classe PdfDocument représente un document PDF. Nous pouvons charger un fichier PDF à l'aide de la méthode LoadFromFile() sous cette classe et enregistrer le document dans d'autres formats, comme HTML, pour réaliser une conversion simple de PDF en HTML.
De plus, cette API fournit également la méthode SetConvertHtmlOptions() sous la propriété PdfDocument.ConversionOptions pour définir les options d'intégration d'image lors de la conversion. Vous trouverez ci-dessous les paramètres qui peuvent être transmis à cette méthode pour définir le numéro de page maximum, l'option d'intégration SVG, l'option d'intégration d'image et l'option de qualité SVG :
- useEmbeddedSvg (bool): lorsqu'il est défini sur True, il permet d'intégrer SVG dans le fichier HTML converti. Le fichier HTML résultant inclura tous les éléments du document PDF, y compris les images, dans un seul fichier HTML.
- useEmbeddedImg (bool): lorsqu'il est défini sur True, il permet d'incorporer des images dans le fichier HTML converti. Ce paramètre ne fonctionne que si useEmbeddedSvg est défini sur False.
- maxPageOneFile (int): définit le nombre maximum de pages à inclure dans un seul fichier HTML. Si le PDF comporte plus de pages que le nombre spécifié, plusieurs fichiers HTML seront générés, chacun contenant un sous-ensemble de pages.
- useHighQualityEmbeddedSvg (bool): lorsqu'il est défini sur True, garantit l'utilisation de versions de haute qualité des images SVG intégrées dans le processus de conversion HTML.
Flux de travail typique de conversion de PDF en HTML en Python à l'aide de Spire.PDF for Python:
- Créez un objet de la classe PdfDocument et chargez un document PDF à l'aide de la méthode PdfDocument.LoadFromFile(string fileName).
- Définissez les options de conversion à l'aide de la méthode PdfDocument.ConversionOptions.SetConvertHtmlOptions().
- Convertissez le document au format HTML et enregistrez-le à l'aide de la méthode PdfDocument.SaveToFile(string fileName, FileFormat.HTML).
Les utilisateurs peuvent téléchargez Spire.PDF for Python et importez-le dans leurs projets, ou installez-le avec PyPI :
pip install Spire.PDF
Convertir un PDF en un seul fichier HTML avec du code Python
Cet exemple de code montre comment convertir directement un PDF en HTML avec Python sans définir d'options de conversion. Dans ce cas, il suffit de charger un fichier PDF avec la méthode LoadFromFile et de l'enregistrer sous forme de fichier HTML avec la méthode SaveToFile. Le fichier HTML converti sera un seul fichier HTML contenant des images et d’autres éléments intégrés.
Exemple de code :
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("G:/Documents/ARCHITECTURE.pdf")
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTML.html", FileFormat.HTML)
doc.Close()
Résultat de la conversion :
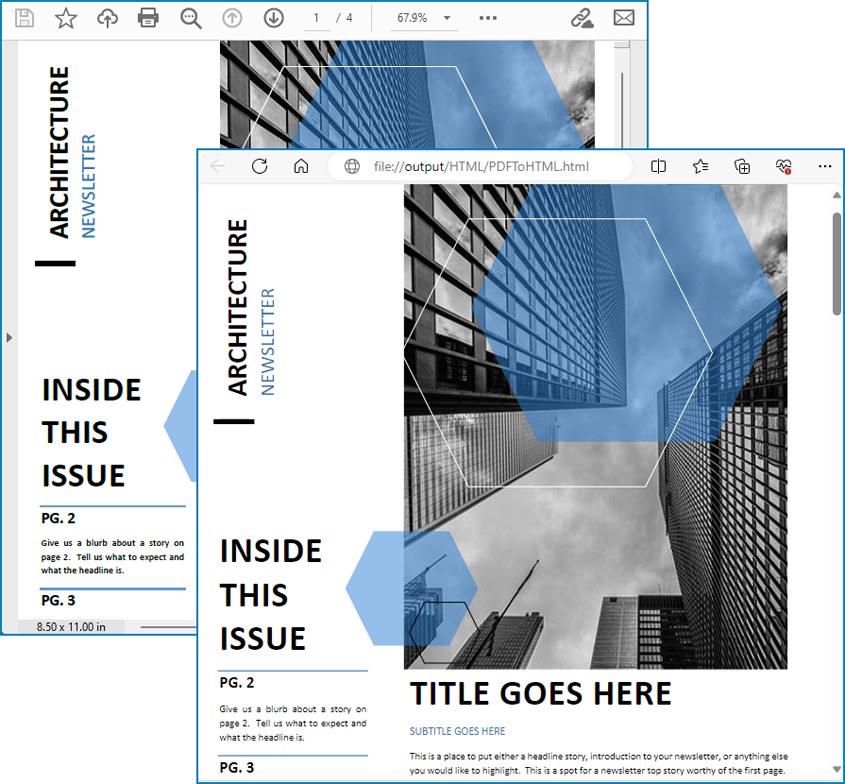
Convertir un PDF en HTML avec des images séparées à l'aide de Python
En définissant le paramètre useEmbeddedSvg sur False, nous pouvons convertir le document PDF en un fichier HTML avec des images et des fichiers CSS séparés et stockés dans un dossier. Cela facilite la modification ultérieure du fichier HTML converti et l'exécution d'opérations supplémentaires sur les images.
Exemple de code :
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLWithoutEmbeddingSVG.html", FileFormat.HTML)
doc.Close()
Résultat de la conversion :
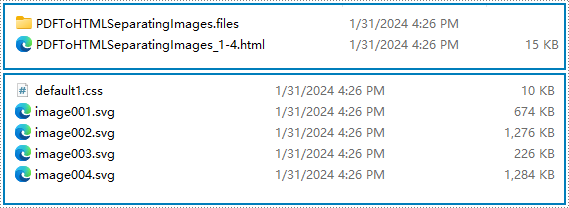
Convertir un PDF en plusieurs fichiers HTML avec Python
Avec la condition préalable selon laquelle useEmbeddedSvg est défini sur False, la méthode SetPdfToHtmlOptions permet d'utiliser le paramètre maxPageOneFile (int) pour déterminer le nombre maximum de pages incluses dans chaque fichier HTML converti. Cette fonctionnalité permet Fractionnement de documents PDF dans le processus de conversion. Par exemple, définir le paramètre sur 1 entraînera la conversion de chaque page en un fichier HTML distinct.
Exemple de code :
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False, False, 1, False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLLimitingPage.html", FileFormat.HTML)
doc.Close()
Résultat de la conversion :
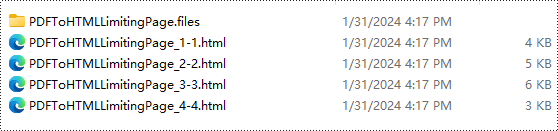
Licence gratuite et support technique
Spire.PDF for Python offre aux utilisateurs une licence d'essai gratuite pour tous les utilisateurs, y compris les utilisateurs professionnels et individuels. Demander une licence temporaire d'utiliser cette API Python pour convertir des documents PDF en fichiers HTML, en supprimant toute restriction d'utilisation ou filigrane.
Pour tout problème rencontré lors de la conversion PDF en HTML à l'aide de cette API, les utilisateurs peuvent demander une assistance technique sur le forum Spire.PDF.
Conclusion
Cet article montre comment convertir un PDF en HTML à l'aide de Python et propose diverses options de conversion, telles que la conversion en un seul fichier HTML, la séparation des fichiers HTML des images et le fractionnement du document PDF lors de la conversion. Avec Spire.PDF for Python, les utilisateurs ont accès à une méthode simple et efficace pour la conversion Python de PDF en HTML, prenant en charge des options de personnalisation flexibles.
