Table des matières
Installé via NuGet
PM> Install-Package Spire.PDF
Liens connexes
Les documents PDF ont une mise en page fixe et ne permettent pas aux utilisateurs d'y apporter des modifications. Pour rendre le contenu PDF à nouveau modifiable, vous pouvez convertir un PDF en Word ou extraire du texte d'un PDF. Dans cet article, vous apprendrez comment extraire le texte d'une page PDF spécifique, comment extraire le texte d'une zone de rectangle particulière, et comment extraire le texte par SimpleTextExtractionStrategy en C# et VB.NET l'aide de Spire.PDF for .NET.
- Extraire le texte d'une page spécifiée
- Extraire le texte d'un rectangle
- Extraire du texte à l'aide de SimpleTextExtractionStrategy
Installer Spire.PDF for .NET
Pour commencer, vous devez ajouter les fichiers DLL inclus dans le package Spire.PDF for.NET comme références dans votre projet .NET. Les fichiers DLL peuvent être téléchargés à partir de ce lien ou installés via NuGet.
PM> Install-Package Spire.PDF
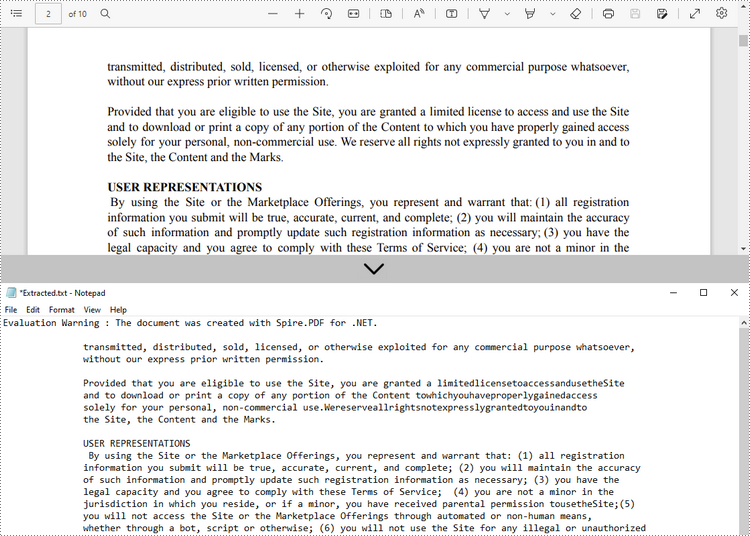
Extraire le texte d'une page spécifiée
Voici les étapes pour extraire le texte d'une certaine page d'un document PDF à l'aide de Spire.PDF for .NET.
- Créez un objet PdfDocument.
- Chargez un fichier PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Obtenez la page spécifique via la propriété PdfDocument.Pages[index].
- Créez un objet PdfTextExtractor.
- Créez un objet PdfTextExtractOptions et définissez la propriété IsExtractAllText sur true.
- Extrayez le texte de la page sélectionnée à l’aide de la méthode PdfTextExtractor.ExtractText().
- Écrivez le texte extrait dans un fichier TXT.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
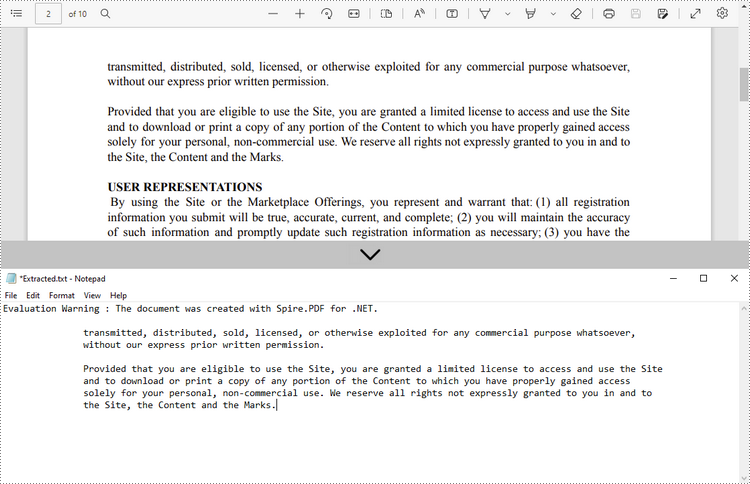
Extraire le texte d'un rectangle
Voici les étapes pour extraire le texte d’une zone rectangulaire d’une page à l’aide de Spire.PDF for .NET.
- Créez un objet PdfDocument.
- Chargez un fichier PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Obtenez la page spécifique via la propriété PdfDocument.Pages[index].
- Créez un objet PdfTextExtractor.
- Créez un objet PdfTextExtractOptions et spécifiez la zone rectangulaire via sa propriété ExtractArea.
- Extrayez le texte du rectangle à l’aide de la méthode PdfTextExtractor.ExtractText().
- Écrivez le texte extrait dans un fichier TXT.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
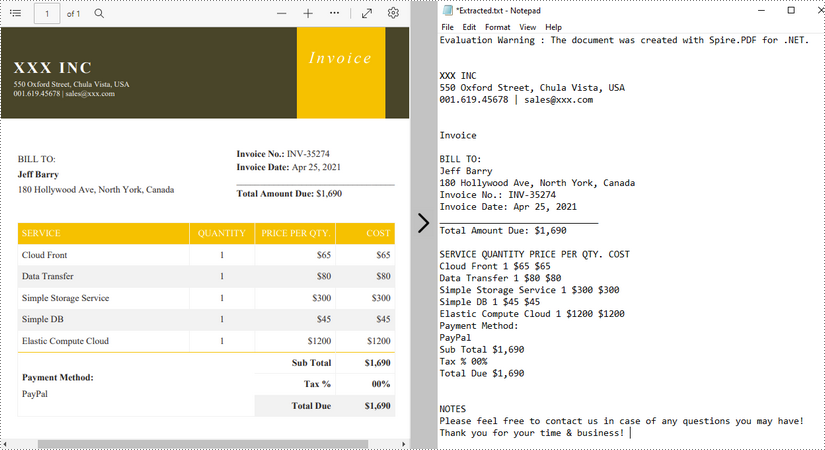
Extraire du texte à l'aide de SimpleTextExtractionStrategy
Les méthodes ci-dessus extraient le texte ligne par ligne. Lors de l'extraction de texte à l'aide de SimpleTextExtractionStrategy, il garde une trace de la position Y actuelle de chaque chaîne et insère un saut de ligne dans la sortie si la position Y a changé. Voici les étapes détaillées.
- Créez un objet PdfDocument.
- Chargez un fichier PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Obtenez la page spécifique via la propriété PdfDocument.Pages[index].
- Créez un objet PdfTextExtractor.
- Créez un objet PdfTextExtractOptions et définissez la propriété IsSimpleExtraction sur true.
- Extrayez le texte de la page sélectionnée à l’aide de la méthode PdfTextExtractor.ExtractText().
- Écrivez le texte extrait dans un fichier TXT.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Demander une licence temporaire
Si vous souhaitez supprimer le message d'évaluation des documents générés ou vous débarrasser des limitations fonctionnelles, veuillez demander une licence d'essai de 30 jours pour toi.
