Table des matières
Installé via NuGet
PM> Install-Package Spire.PDF
Liens connexes
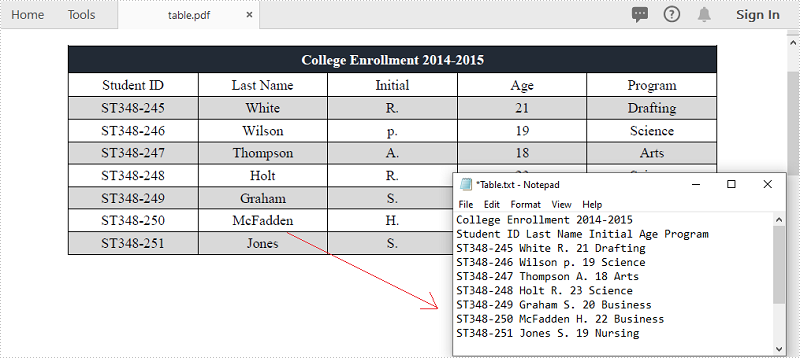
Le PDF est l'un des formats de document les plus populaires pour le partage et l'écriture de données. Vous pouvez rencontrer la situation où vous devez extraire des données à partir de documents PDF, en particulier les données des tableaux. Par exemple, des informations utiles sont stockées dans les tableaux de vos factures PDF et vous souhaitez extraire les données pour une analyse ou un calcul plus approfondi. Cet article montre comment extraire des données de tableaux PDF et enregistrez-le dans un fichier TXT en utilisant Spire.PDF for .NET.
Installer Spire.PDF for .NET
Pour commencer, vous devez ajouter les fichiers DLL inclus dans le package Spire.PDF for .NET en tant que références dans votre projet .NET. Les fichiers DLL peuvent être téléchargés à partir de ce lien ou installés via NuGet.
- Package Manager
PM> Install-Package Spire.PDF
Extraire des données de tableaux PDF
Voici les principales étapes pour extraire des tableaux d'un document PDF.
- Créez une instance de la classe PdfDocument.
- Chargez l'exemple de document PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Extrayez les tableaux d’une page spécifique à l’aide de la méthode PdfTableExtractor.ExtractTable(int pageIndex).
- Obtenez le texte d’une certaine cellule du tableau à l’aide de la méthode PdfTable.GetText(int rowIndex, int columnIndex).
- Enregistrez les données extraites dans un fichier .txt.
- C#
- VB.NET
using System.IO;
using System.Text;
using Spire.Pdf;
using Spire.Pdf.Utilities;
namespace ExtractPdfTable
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load the sample PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\table.pdf");
//Create a StringBuilder object
StringBuilder builder = new StringBuilder();
//Initialize an instance of PdfTableExtractor class
PdfTableExtractor extractor = new PdfTableExtractor(doc);
//Declare a PdfTable array
PdfTable[] tableList = null;
//Loop through the pages
for (int pageIndex = 0; pageIndex < doc.Pages.Count; pageIndex++)
{
//Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex);
//Determine if the table list is null
if (tableList != null && tableList.Length > 0)
{
//Loop through the table in the list
foreach (PdfTable table in tableList)
{
//Get row number and column number of a certain table
int row = table.GetRowCount();
int column = table.GetColumnCount();
//Loop though the row and colunm
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
//Get text from the specific cell
string text = table.GetText(i, j);
//Add text to the string builder
builder.Append(text + " ");
}
builder.Append("\r\n");
}
}
}
}
//Write to a .txt file
File.WriteAllText("Table.txt", builder.ToString());
}
}
}
Imports System.IO
Imports System.Text
Imports Spire.Pdf
Imports Spire.Pdf.Utilities
Namespace ExtractPdfTable
Class Program
Shared Sub Main(ByVal args() As String)
'Create a PdfDocument object
Dim doc As PdfDocument = New PdfDocument()
'Load the sample PDF file
doc.LoadFromFile("C:\Users\Administrator\Desktop\table.pdf")
'Create a StringBuilder object
Dim builder As StringBuilder = New StringBuilder()
'Initialize an instance of PdfTableExtractor class
Dim extractor As PdfTableExtractor = New PdfTableExtractor(doc)
'Declare a PdfTable array
Dim tableList() As PdfTable = Nothing
'Loop through the pages
Dim pageIndex As Integer
For pageIndex = 0 To doc.Pages.Count- 1 Step pageIndex + 1
'Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex)
'Determine if the table list is null
If tableList <> Nothing And tableList.Length > 0 Then
'Loop through the table in the list
Dim table As PdfTable
For Each table In tableList
'Get row number and column number of a certain table
Dim row As Integer = table.GetRowCount()
Dim column As Integer = table.GetColumnCount()
'Loop though the row and colunm
Dim i As Integer
For i = 0 To row- 1 Step i + 1
Dim j As Integer
For j = 0 To column- 1 Step j + 1
'Get text from the specific cell
Dim text As String = table.GetText(i,j)
'Add text to the string builder
builder.Append(text + " ")
Next
builder.Append("\r\n")
Next
Next
End If
Next
'Write to a .txt file
File.WriteAllText("Table.txt", builder.ToString())
End Sub
End Class
End Namespace
Demander une licence temporaire
Si vous souhaitez supprimer le message d'évaluation des documents générés ou vous débarrasser des limitations de la fonction, veuillez demander une licence d'essai de 30 jours pour toi.
