Table des matières
Liens connexes
À l'ère numérique d'aujourd'hui, l'extraction de texte à partir d'images ou de PDF numérisés est une exigence courante pour diverses applications. La reconnaissance optique de caractères (OCR) est une technologie qui permet aux ordinateurs de reconnaître et d'extraire le texte de ces documents. Grâce à lui, nous pouvons facilement convertir des images et des PDF numérisés en formats modifiables et consultables, facilitant ainsi le traitement et l'analyse du contenu textuel. Dans ce blog, nous explorerons comment extraire du texte à partir d'images et de PDF numérisés avec OCR en C#.
- Extraire le texte des images en C#
- Extraire le texte des images avec des coordonnées en C#
- Extraire le texte des PDF numérisés en C#
Bibliothèques C# pour extraire du texte à partir d'images et de PDF numérisés
Pour extraire le texte des images, nous utiliserons la bibliothèque Spire.OCR for .NET. Spire.OCR for .NET est une bibliothèque puissante conçue spécifiquement pour extraire du texte à partir d'images dans des applications .NET. Il prend en charge divers formats d'image tels que BMP, JPG, PNG, TIFF et GIF.
Voici les étapes pour installer Spire.OCR for .NET:
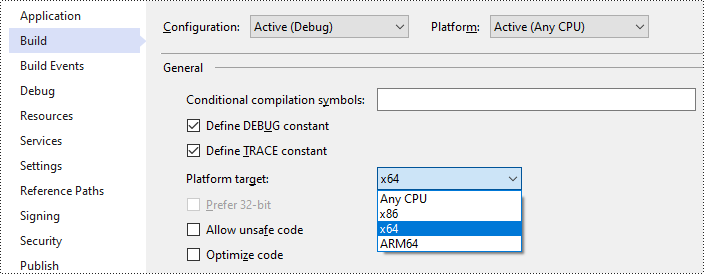
- Modifiez la cible de plate-forme de votre solution en x64.
- Installez Spire.OCR à partir de NuGet en exécutant la commande suivante dans la console NuGet Package Manager :
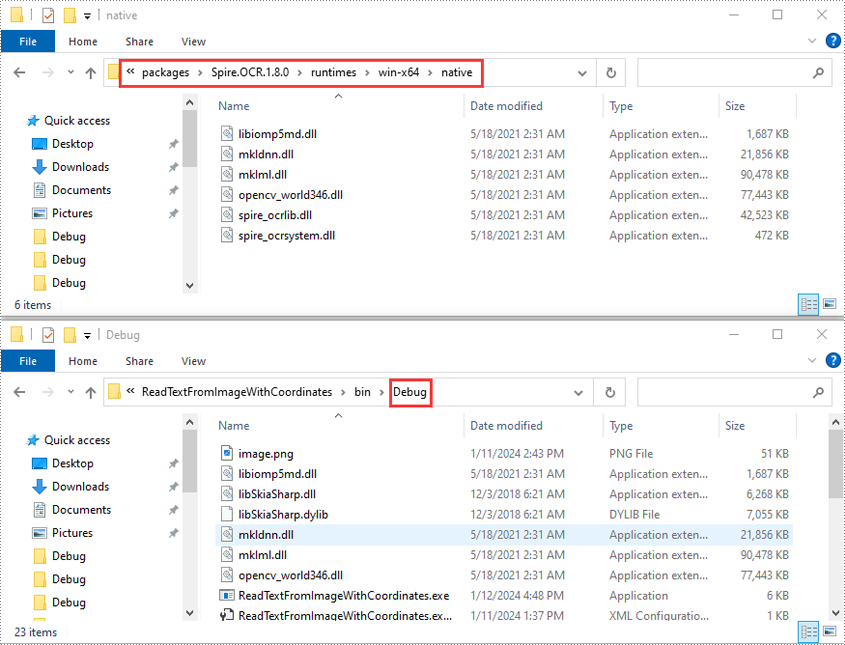
- Ouvrez votre dossier de solution et accédez au répertoire « packages\Spire.OCR.1.8.0\runtimes\win-x64\native ». Copiez les fichiers DLL de ce répertoire et collez-les dans le dossier "Debug" de votre solution.
Install-Package Spire.OCR
Pour extraire le texte d'un PDF numérisé, nous devons d'abord convertir le document PDF en images. Pour cette tâche, nous emploierons le Spire.PDF for .NET bibliothèque. Une fois la conversion terminée, nous pouvons utiliser Spire.OCR pour extraire le texte des images résultantes.
Vous pouvez installer Spire.PDF for .NET à partir de NuGet en exécutant la commande suivante dans la console NuGet Package Manager :
Install-Package Spire.PDF
Extraire le texte des images en C#
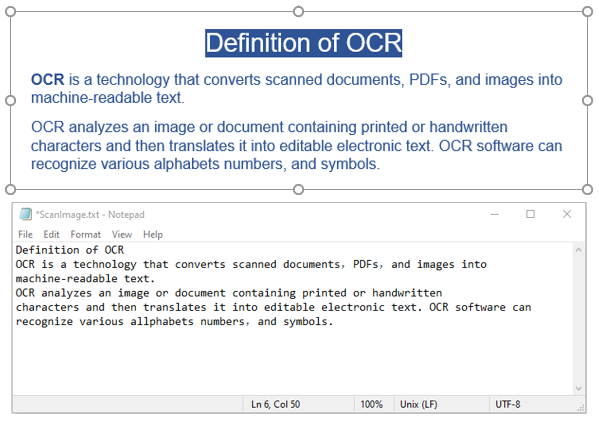
Spire.OCR fournit la méthode OcrScanner.Scan() pour reconnaître le texte d'une image. Après reconnaissance, vous pouvez obtenir le texte reconnu à l'aide de la propriété OcrScanner.Text.
Voici les principales étapes pour reconnaître le texte d'une image à l'aide de Spire.OCR :
- Créez une instance de la classe OcrScanner.
- Reconnaître le texte d'une image à l'aide de la méthode OcrScanner.Scan().
- Obtenez le texte reconnu de l'objet OcrScanner à l'aide de la propriété OcrScanner.Text.
- Enregistrez le texte dans un fichier texte.
Voici un exemple de code qui montre comment reconnaître le texte d'une image et enregistrer le résultat dans un fichier texte :
- C#
using Spire.OCR;
using System.IO;
namespace ReadTextFromImage
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imageFilePath = "Image.png";
//Specify the path of the output text file
string outputFilePath = "ScanImage.txt";
//Call the ScanTextFromImage method to scan text from an image
string scannedText = ScanTextFromImage(imageFilePath);
//Write the text to the specified file
File.WriteAllText(outputFilePath, scannedText);
}
public static string ScanTextFromImage(string imageFilePath)
{
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the recognized text from the OcrScanner object
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Extraire le texte des images avec des coordonnées en C#
L'extraction de coordonnées est utile lorsque vous devez identifier l'emplacement exact d'éléments de texte spécifiques dans votre image. Avec Spire.OCR, vous pouvez récupérer le texte reconnu sous forme de blocs ou de lignes. Pour chaque bloc, vous pouvez obtenir des informations détaillées sur son emplacement, y compris les coordonnées x et y, ainsi que sa largeur et sa hauteur.
Voici les principales étapes pour extraire du texte ainsi que ses informations de localisation à partir d'une image à l'aide de Spire.OCR :
- Créez une instance de la classe OcrScanner.
- Reconnaître le texte d'une image à l'aide de la méthode OcrScanner.Scan().
- Obtenez le texte reconnu de l'objet OcrScanner à l'aide de la propriété OcrScanner.Text.
- Parcourez les blocs de texte du texte reconnu.
- Pour chaque bloc, obtenez son texte et ses informations d'emplacement à l'aide des propriétés IOCRTextBlock.Text et IOCRTextBlock.Box, puis ajoutez le résultat à une liste de chaînes.
- Enregistrez le contenu de la liste dans un fichier texte.
Voici un exemple de code qui montre comment reconnaître le texte ainsi que ses informations de localisation à partir d'une image et enregistrer le résultat dans un fichier texte :
- C#
using Spire.OCR;
using System.Collections.Generic;
using System.IO;
namespace ReadTextFromImageWithCoordinates
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imagePath = "Image.png";
//Specify the path of the output text file
string outputFile = "ScanImageWithCoordinates.txt";
//Call the ScanTextFromImageWithCoordinates method to extract text and its area information from the image
List<string> extractedText = ScanTextFromImageWithCoordinates(imagePath);
//Write the result to the specified file
File.WriteAllLines(outputFile, extractedText);
}
//Retrieve the text blocks along with their location information (x, y, width, height) from an image
public static List<string> ScanTextFromImageWithCoordinates(string imageFilePath)
{
//Create a list
List<string> extractedText = new List<string>();
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the scanned text
IOCRText text = ocrScanner.Text;
//Iterate through each text block
foreach (IOCRTextBlock block in text.Blocks)
{
//Append the text of each block and its location information to the list
extractedText.Add($"Text: {block.Text}\nRectangular Area: {block.Box}");
}
}
return extractedText;
}
}
}
Extraire le texte des PDF numérisés en C#
Pour extraire le texte des PDF numérisés, nous devons suivre un processus en deux étapes. Tout d’abord, nous utilisons Spire.PDF pour convertir les PDF numérisés en images. Ensuite, nous utilisons Spire.OCR pour extraire le texte de ces images.
Voici les principales étapes pour reconnaître le texte d'un PDF numérisé à l'aide de Spire.PDF et Spire.OCR :
- Créez une instance de la classe PdfDocument.
- Chargez un document PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Parcourez les pages du document PDF.
- Convertissez chaque page en un objet Image à l’aide de la méthode PdfDocument.SaveAsImage().
- Enregistrez l'objet Image dans un flux à l'aide de la méthode Image.Save().
- Créez une instance de la classe OcrScanner.
- Reconnaissez le texte du flux à l’aide de la méthode OcrScanner.Scan().
- Obtenez le texte reconnu à l’aide de la propriété IOCRText.Text et ajoutez-le à une liste de chaînes.
- Enregistrez le contenu de la liste dans un fichier texte.
Voici un exemple de code qui montre comment reconnaître le texte d'un PDF numérisé et enregistrer le résultat dans un fichier texte :
- C#
using Spire.OCR;
using Spire.Pdf;
using System.Collections.Generic;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
namespace ReadTextFromScannedPDF
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the scanned PDF file
string pdfFilePath = "Sample.pdf";
//Specify the path of the output text file
string outputFilePath = "ScanPDF.txt";
//Extract text from the scanned PDF
List<string> extractedText = ExtractTextFromScannedPDF(pdfFilePath);
//Write the text to the specified file
File.WriteAllLines(outputFilePath, extractedText);
}
//Extract text from a scanned PDF
public static List<string> ExtractTextFromScannedPDF(string pdfFilePath)
{
//Create a list to store the extracted text
List<string> extractedText = new List<string>();
//Create an instance of the PdfDocument class
using (PdfDocument document = new PdfDocument())
{
//Load the PDF document
document.LoadFromFile(pdfFilePath);
//Iterate through each page of the document
for (int pageIndex = 0; pageIndex < document.Pages.Count; pageIndex++)
{
//Convert the page to an image
using (Image image = document.SaveAsImage(pageIndex, 300, 300))
{
//Create a memory stream to hold the image data
using (MemoryStream stream = new MemoryStream())
{
//Save the image to the memory stream in PNG format
image.Save(stream, ImageFormat.Png);
stream.Position = 0;
//Scan the text from the image and add it to the list
string text = ScanTextFromImageStream(stream);
extractedText.Add(text);
}
}
}
}
//Return the list
return extractedText;
}
//Scan text from an image stream
public static string ScanTextFromImageStream(Stream stream)
{
//Create an instance of the OcrScanner class
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan the text from the image stream in PNG format
ocrScanner.Scan(stream, OCRImageFormat.Png);
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Obtenez une licence gratuite
Pour profiter pleinement des capacités de Spire.OCR for .NET ou Spire.PDF for .NET sans aucune limitation d'évaluation, vous pouvez demander une licence d'essai gratuite de 30 jours.
Conclusion
Cet article de blog a montré comment extraire du texte à partir d'images et de documents PDF numérisés en C#. Si vous avez des questions, n'hésitez pas à les publier sur notre forum ou à les envoyer à notre équipe d'assistance par e-mail.
- Comment utiliser Spire.OCR dans les applications .NET Framework.
- Comment utiliser Spire.OCR for .NET dans les applications .NET Core
- C#/VB.NET : convertir des PDF en images (JPG, PNG, BMP)
- C#/VB.NET : convertir des images en PDF
- C#/VB.NET : convertir un PDF en Word
- C#/VB.NET : extraire le texte des documents PDF
