Tabla de contenido
Instalar con Pip
pip install Spire.PDF
enlaces relacionados
Los archivos PDF son una opción popular para compartir y distribuir documentos, pero puede resultar bastante complicado extraer y reutilizar el contenido PDF. Afortunadamente, convertir archivos PDF a HTML con Python ofrece una excelente solución para la recuperación y reutilización de información PDF, que mejora la accesibilidad, la capacidad de búsqueda y la adaptabilidad. Además, el formato HTML permite a los motores de búsqueda indexar el contenido, lo que aumenta las probabilidades de que lo descubran en la web. Es más, con la flexibilidad y facilidad de uso de Python, tanto los principiantes como los desarrolladores experimentados pueden utilizarlo. Python para convertir PDF a HTML fácil y eficientemente.

Este artículo se centra en cómo convertir PDF a HTML en programas Python. Incluye principalmente los siguientes temas:
- Descripción general de la conversión de PDF a HTML con Python
- Convierta PDF a un único archivo HTML con código Python
- Convierta PDF a HTML con imágenes separadas usando Python
- Convierta PDF a varios archivos HTML con Python
- Licencia gratuita y soporte técnico
Descripción general de la conversión de PDF a HTML con Python
Las amplias API de Python brindan comodidad para diversas operaciones de procesamiento de documentos PDF. Spire.PDF for Python es una de las API potentes que puede realizar diversas operaciones en documentos PDF, incluida la conversión, edición y fusionar documentos PDF. Y la conversión de PDF a HTML con Python se puede implementar sin esfuerzo con esta API.
En Spire.PDF for Python, la clase PdfDocument representa un documento PDF. Podemos cargar un archivo PDF usando el método LoadFromFile() en esta clase y guardar el documento en otros formatos, como HTML, para lograr una conversión simple de PDF a HTML.
Además, esta API también proporciona el método SetConvertHtmlOptions() en la propiedad PdfDocument.ConversionOptions para configurar las opciones de incrustación de imágenes durante la conversión. A continuación se detallan los parámetros que se pueden pasar a este método para establecer el número máximo de páginas, la opción de incrustación de SVG, la opción de incrustación de imágenes y la opción de calidad de SVG:
- useEmbeddedSvg (bool): cuando se establece en True, permite incrustar SVG en el archivo HTML convertido. El archivo HTML resultante incluirá todos los elementos del documento PDF, incluidas las imágenes, en un único archivo HTML.
- useEmbeddedImg (bool): cuando se establece en True, permite incrustar imágenes en el archivo HTML convertido. Este parámetro solo funciona si useEmbeddedSvg está configurado en False.
- maxPageOneFile (int): establece el número máximo de páginas que se incluirán en un único archivo HTML. Si el PDF tiene más páginas que el número especificado, se generarán varios archivos HTML, cada uno de los cuales contendrá un subconjunto de páginas.
- useHighQualityEmbeddedSvg (bool): cuando se establece en True, garantiza el uso de versiones de alta calidad de imágenes SVG incrustadas en el proceso de conversión HTML.
Flujo de trabajo típico de conversión de PDF a HTML en Python usando Spire.PDF for Python:
- Cree un objeto de la clase PdfDocument y cargue un documento PDF utilizando el método PdfDocument.LoadFromFile(string fileName).
- Configure las opciones de conversión utilizando el método PdfDocument.ConversionOptions.SetConvertHtmlOptions().
- Convierta el documento a formato HTML y guárdelo utilizando el método PdfDocument.SaveToFile(string fileName, FileFormat.HTML).
Los usuarios pueden descargar Spire.PDF for Python e importarlo a sus proyectos, o instalarlo con PyPI:
pip install Spire.PDF
Convierta PDF a un único archivo HTML con código Python
Este ejemplo de código muestra cómo convertir PDF a HTML con Python directamente sin configurar ninguna opción de conversión. En este caso, sólo necesitamos cargar un archivo PDF con el método LoadFromFile y guardarlo como un archivo HTML con el método SaveToFile. El archivo HTML convertido será un único archivo HTML con imágenes y otros elementos incrustados en él.
Ejemplo de código:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("G:/Documents/ARCHITECTURE.pdf")
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTML.html", FileFormat.HTML)
doc.Close()
Resultado de la conversión:
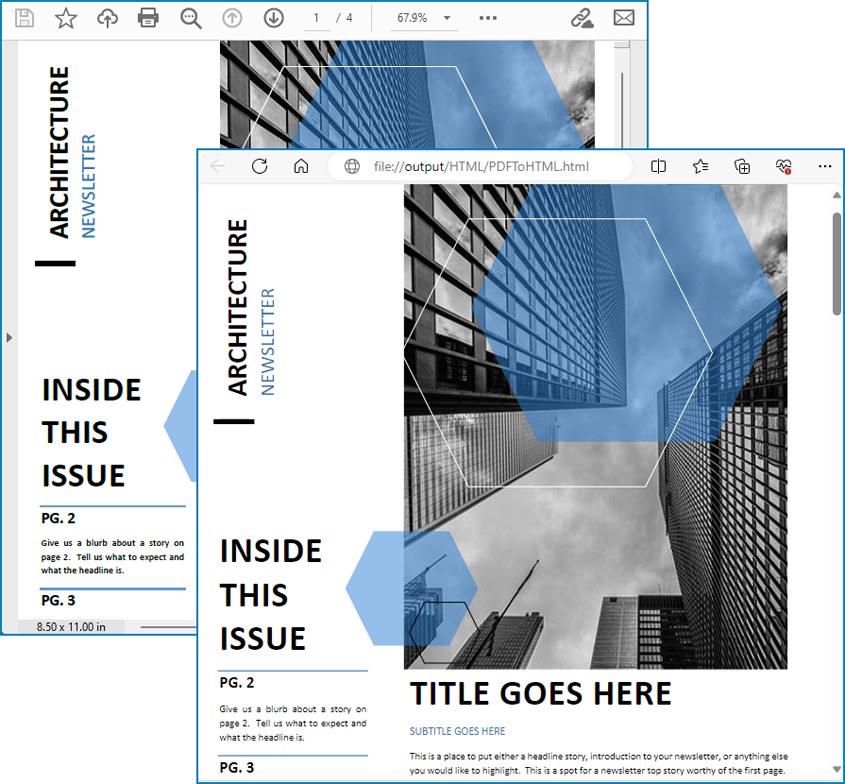
Convierta PDF a HTML con imágenes separadas usando Python
Al establecer el parámetro useEmbeddedSvg en False, podemos convertir el documento PDF en un archivo HTML con imágenes y archivos CSS separados y almacenados en una carpeta. Esto hace que sea conveniente editar aún más el archivo HTML convertido y realizar operaciones adicionales en las imágenes.
Ejemplo de código:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLWithoutEmbeddingSVG.html", FileFormat.HTML)
doc.Close()
Resultado de la conversión:
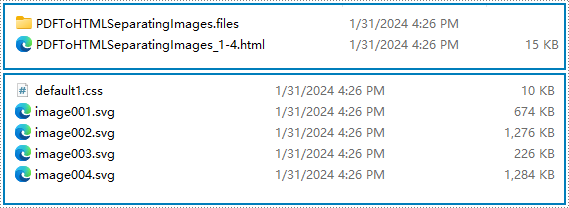
Convierta PDF a varios archivos HTML con Python
Con la condición previa de que useEmbeddedSvg esté establecido en False, el método SetPdfToHtmlOptions permite el uso del parámetro maxPageOneFile (int) para determinar el número máximo de páginas incluidas en cada archivo HTML convertido. Esta característica permite División de documentos PDF en el proceso de conversión. Por ejemplo, establecer el parámetro en 1 dará como resultado que cada página se convierta en un archivo HTML independiente.
Ejemplo de código:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False, False, 1, False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLLimitingPage.html", FileFormat.HTML)
doc.Close()
Resultado de la conversión:
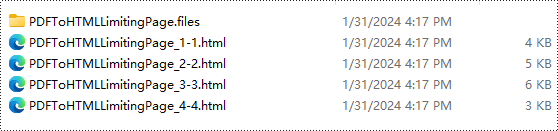
Licencia gratuita y soporte técnico
Spire.PDF for Python ofrece a los usuarios una licencia de prueba gratuita para todos los usuarios, incluidos usuarios empresariales e individuales. Solicitar una licencia temporal utilizar esta API de Python para convertir documentos PDF a archivos HTML, eliminando cualquier restricción de uso o marca de agua.
Para cualquier problema encontrado durante la conversión de PDF a HTML utilizando esta API, los usuarios pueden buscar soporte técnico en el foro Spire.PDF.
Conclusión
Este artículo demuestra cómo convertir PDF a HTML usando Python y proporciona varias opciones de conversión, como convertir a un solo archivo HTML, separar archivos HTML de imágenes y dividir el documento PDF durante la conversión. Con Spire.PDF for Python, los usuarios tienen acceso a un método sencillo y eficiente para la conversión de Python en PDF a HTML, que admite opciones de personalización flexibles.
