Tabla de contenido
Instalado a través de NuGet
PM> Install-Package Spire.PDF
enlaces relacionados
Los documentos PDF tienen un diseño fijo y no permiten a los usuarios realizar modificaciones en ellos. Para volver a editar el contenido del PDF, puede convertir PDF a Word o extraer texto de PDF. En este artículo, aprenderá cómo extraer texto de una página PDF específica, cómo extraer texto de un área rectangular particular, y cómo extraiga texto mediante SimpleTextExtractionStrategy en C# y VB.NET usando Spire.PDF for .NET.
- Extraer texto de una página especificada
- Extraer texto de un rectángulo
- Extraer texto usando SimpleTextExtractionStrategy
Instalar Spire.PDF for .NET
Para empezar, debe agregar los archivos DLL incluidos en el paquete Spire.PDF for .NET como referencias en su proyecto .NET. Los archivos DLL se pueden descargar desde este enlace o instalar a través de NuGet.
PM> Install-Package Spire.PDF
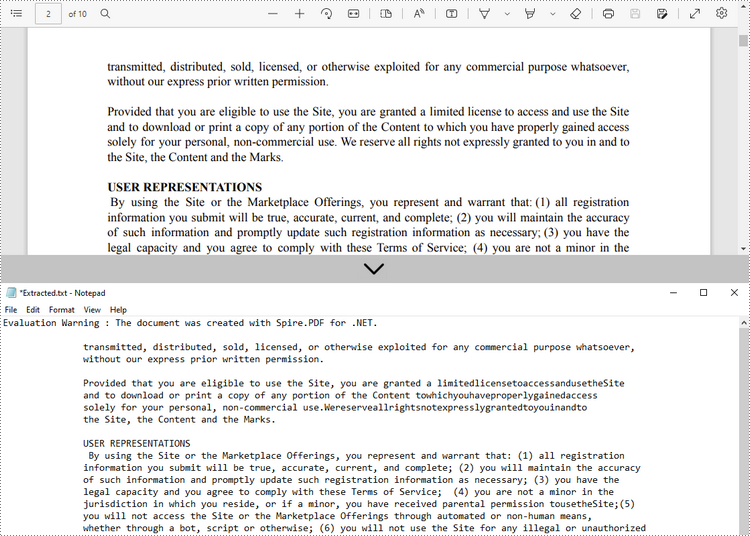
Extraer texto de una página especificada
Los siguientes son los pasos para extraer texto de una determinada página de un documento PDF usando Spire.PDF for .NET.
- Cree un objeto PdfDocument.
- Cargue un archivo PDF utilizando el método PdfDocument.LoadFromFile().
- Obtenga la página específica a través de la propiedad PdfDocument.Pages[index].
- Cree un objeto PdfTextExtractor.
- Cree un objeto PdfTextExtractOptions y establezca la propiedad IsExtractAllText en verdadero.
- Extraiga texto de la página seleccionada utilizando el método PdfTextExtractor.ExtractText().
- Escriba el texto extraído en un archivo TXT.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
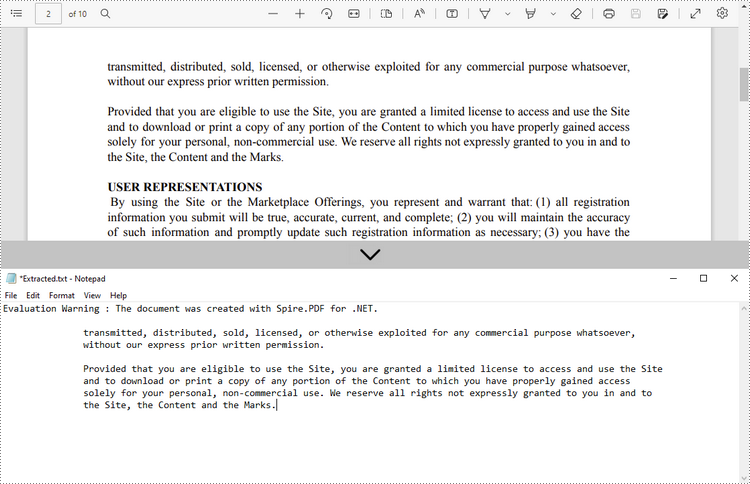
Extraer texto de un rectángulo
Los siguientes son los pasos para extraer texto de un área rectangular de una página usando Spire.PDF for .NET.
- Cree un objeto PdfDocument.
- Cargue un archivo PDF utilizando el método PdfDocument.LoadFromFile().
- Obtenga la página específica a través de la propiedad PdfDocument.Pages[index].
- Cree un objeto PdfTextExtractor.
- Cree un objeto PdfTextExtractOptions y especifique el área del rectángulo a través de la propiedad ExtractArea del mismo.
- Extraiga texto del rectángulo utilizando el método PdfTextExtractor.ExtractText().
- Escriba el texto extraído en un archivo TXT.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
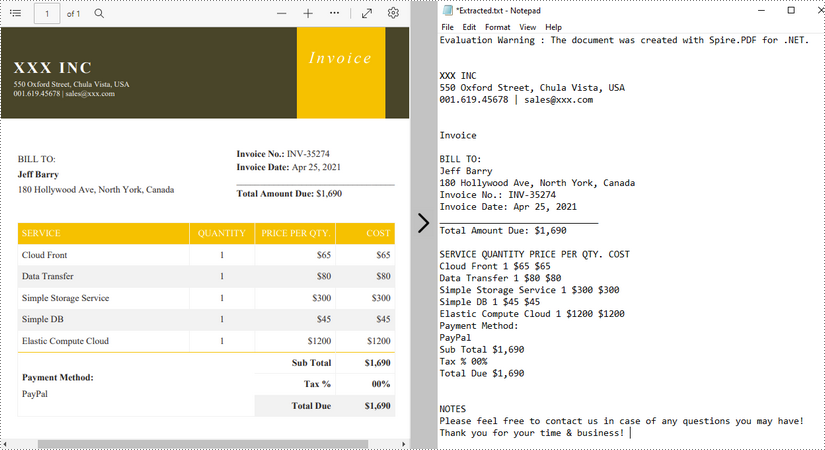
Extraer texto usando SimpleTextExtractionStrategy
Los métodos anteriores extraen texto línea por línea. Al extraer texto usando SimpleTextExtractionStrategy, realiza un seguimiento de la posición Y actual de cada cadena e inserta un salto de línea en la salida si la posición Y ha cambiado. Los siguientes son los pasos detallados.
- Cree un objeto PdfDocument.
- Cargue un archivo PDF utilizando el método PdfDocument.LoadFromFile().
- Obtenga la página específica a través de la propiedad PdfDocument.Pages[index].
- Cree un objeto PdfTextExtractor.
- Cree un objeto PdfTextExtractOptions y establezca la propiedad IsSimpleExtraction en verdadero.
- Extraiga texto de la página seleccionada utilizando el método PdfTextExtractor.ExtractText().
- Escriba el texto extraído en un archivo TXT.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Solicitar una licencia temporal
Si desea eliminar el mensaje de evaluación de los documentos generados o deshacerse de las limitaciones de la función, por favor solicitar una licencia de prueba de 30 días para ti.
