Tabla de contenido
Instalado a través de NuGet
PM> Install-Package Spire.PDF
enlaces relacionados
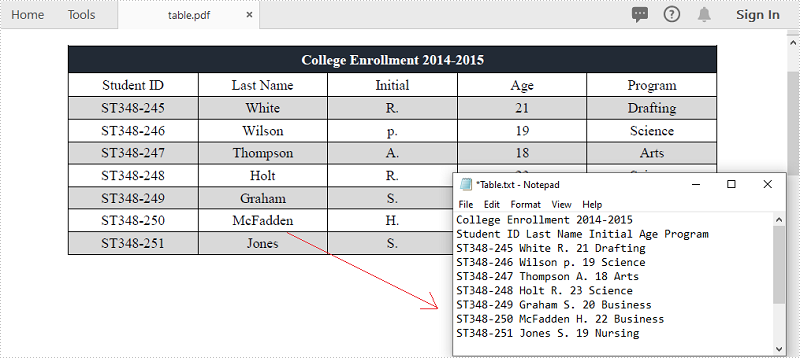
PDF es uno de los formatos de documentos más populares para compartir y escribir datos. Puede encontrarse con la situación en la que necesita extraer datos de documentos PDF, especialmente los datos en tablas. Por ejemplo, hay información útil almacenada en las tablas de sus facturas en PDF y desea extraer los datos para su posterior análisis o cálculo. Este artículo demuestra cómo extraer datos de tablas PDF y guárdelo en un archivo TXT utilizando Spire.PDF for .NET.
Instalar Spire.PDF for .NET
Para empezar, debe agregar los archivos DLL incluidos en el paquete Spire.PDF for .NET como referencias en su proyecto .NET. Los archivos DLL se pueden descargar desde este enlace o instalar a través de NuGet.
- Package Manager
PM> Install-Package Spire.PDF
Extraer datos de tablas PDF
Los siguientes son los pasos principales para extraer tablas de un documento PDF.
- Cree una instancia de la clase PdfDocument.
- Cargue el documento PDF de muestra utilizando el método PdfDocument.LoadFromFile().
- Extraiga tablas de una página específica utilizando el método PdfTableExtractor.ExtractTable(int pageIndex).
- Obtenga el texto de una determinada celda de tabla usando el método PdfTable.GetText(int rowIndex, int columnIndex).
- Guarde los datos extraídos en un archivo .txt.
- C#
- VB.NET
using System.IO;
using System.Text;
using Spire.Pdf;
using Spire.Pdf.Utilities;
namespace ExtractPdfTable
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load the sample PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\table.pdf");
//Create a StringBuilder object
StringBuilder builder = new StringBuilder();
//Initialize an instance of PdfTableExtractor class
PdfTableExtractor extractor = new PdfTableExtractor(doc);
//Declare a PdfTable array
PdfTable[] tableList = null;
//Loop through the pages
for (int pageIndex = 0; pageIndex < doc.Pages.Count; pageIndex++)
{
//Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex);
//Determine if the table list is null
if (tableList != null && tableList.Length > 0)
{
//Loop through the table in the list
foreach (PdfTable table in tableList)
{
//Get row number and column number of a certain table
int row = table.GetRowCount();
int column = table.GetColumnCount();
//Loop though the row and colunm
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
//Get text from the specific cell
string text = table.GetText(i, j);
//Add text to the string builder
builder.Append(text + " ");
}
builder.Append("\r\n");
}
}
}
}
//Write to a .txt file
File.WriteAllText("Table.txt", builder.ToString());
}
}
}
Imports System.IO
Imports System.Text
Imports Spire.Pdf
Imports Spire.Pdf.Utilities
Namespace ExtractPdfTable
Class Program
Shared Sub Main(ByVal args() As String)
'Create a PdfDocument object
Dim doc As PdfDocument = New PdfDocument()
'Load the sample PDF file
doc.LoadFromFile("C:\Users\Administrator\Desktop\table.pdf")
'Create a StringBuilder object
Dim builder As StringBuilder = New StringBuilder()
'Initialize an instance of PdfTableExtractor class
Dim extractor As PdfTableExtractor = New PdfTableExtractor(doc)
'Declare a PdfTable array
Dim tableList() As PdfTable = Nothing
'Loop through the pages
Dim pageIndex As Integer
For pageIndex = 0 To doc.Pages.Count- 1 Step pageIndex + 1
'Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex)
'Determine if the table list is null
If tableList <> Nothing And tableList.Length > 0 Then
'Loop through the table in the list
Dim table As PdfTable
For Each table In tableList
'Get row number and column number of a certain table
Dim row As Integer = table.GetRowCount()
Dim column As Integer = table.GetColumnCount()
'Loop though the row and colunm
Dim i As Integer
For i = 0 To row- 1 Step i + 1
Dim j As Integer
For j = 0 To column- 1 Step j + 1
'Get text from the specific cell
Dim text As String = table.GetText(i,j)
'Add text to the string builder
builder.Append(text + " ")
Next
builder.Append("\r\n")
Next
Next
End If
Next
'Write to a .txt file
File.WriteAllText("Table.txt", builder.ToString())
End Sub
End Class
End Namespace
Solicitar una Licencia Temporal
Si desea eliminar el mensaje de evaluación de los documentos generados o deshacerse de las limitaciones de la función, por favor solicitar una licencia de prueba de 30 días para ti.
