
Inhaltsverzeichnis
Über NuGet installiert
PM> Install-Package Spire.PDF
verwandte Links
Viele Finanzberichte, Forschungsarbeiten, Rechtsdokumente oder Rechnungen werden häufig im PDF-Format verteilt. Durch das Lesen von PDF-Dateien können Sie Informationen extrahieren, Inhalte analysieren und Datenverarbeitungsaufgaben wie Textextraktion, Schlüsselwortsuche, Dokumentklassifizierung und Data Mining durchführen.
Durch die Verwendung von C# zum Lesen von PDF-Dateien können Sie sich wiederholende Aufgaben automatisieren und so einen effizienten Abruf spezifischer Informationen aus einer großen Sammlung von PDF-Dateien realisieren. Dies ist nützlich für Anwendungen, die die Suche in umfangreichen Archiven, digitalen Bibliotheken oder Dokumenten-Repositories erfordern. In diesem Artikel finden Sie die folgenden Beispiele, um Ihnen die Vorgehensweise zu zeigen PDF-Datei in C# lesen.
- Lesen Sie Text von einer PDF-Seite in C#
- Lesen Sie Text aus einem PDF-Seitenbereich in C#
- PDF lesen, ohne das Textlayout in C# beizubehalten
- Extrahieren Sie Bilder und Tabellen in PDF in C#
C# PDF Reader-Bibliothek
Die Bibliothek Spire.PDF for .NET kann als PDF-Reader-Bibliothek dienen, die es Entwicklern ermöglicht, PDF-Lesefunktionen in ihre Anwendungen zu integrieren. Es bietet Funktionen und APIs zum Parsen, Rendern und Verarbeiten von PDF-Dateien in .NET-Anwendungen.
Du kannst entweder Laden Sie den C#-PDF-Reader herunter um die DLL-Dateien manuell als Referenzen in Ihr .NET-Projekt einzufügen oder sie direkt über NuGet zu installieren.
PM> Install-Package Spire.PDF
Lesen Sie Text von einer PDF-Seite in C#
Spire.PDF for .NET erleichtert das Lesen von PDF-Text in C# über die PdfTextExtractor-Klasse. Im Folgenden finden Sie die Schritte zum Lesen des gesamten Textes einer bestimmten PDF-Seite.
- Erstellen Sie ein PdfDocument-Objekt.
- Laden Sie eine PDF-Datei mit der Methode PdfDocument.LoadFromFile().
- Rufen Sie die spezifische Seite über die Eigenschaft PdfDocument.Pages[index] ab.
- Erstellen Sie ein PdfTextExtractor-Objekt.
- Erstellen Sie ein PdfTextExtractOptions-Objekt und legen Sie die IsExtractAllText-Eigenschaft auf true fest.
- Extrahieren Sie Text aus der ausgewählten Seite mit der Methode PdfTextExtractor.ExtractText().
- Schreiben Sie den extrahierten Text in eine TXT-Datei.
Das folgende Codebeispiel zeigt, wie Sie mit C# PDF-Text von einer bestimmten Seite lesen.
- C#
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDF.txt", text);
}
}
}
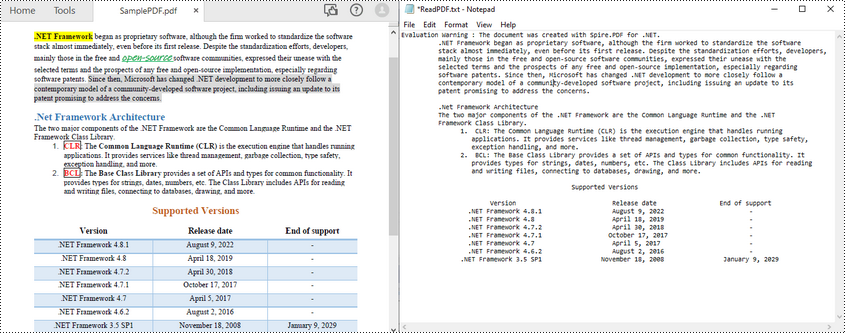
Lesen Sie Text aus einem PDF-Seitenbereich in C#
Um PDF-Text aus einem bestimmten Seitenbereich in PDF zu lesen, können Sie zunächst einen rechteckigen Bereich definieren und dann die Methode setExtractArea() der Klasse PdfTextExtractOptions aufrufen, um Text daraus zu extrahieren. Im Folgenden finden Sie die Schritte zum Extrahieren von PDF-Text aus einem rechteckigen Bereich einer Seite.
- Erstellen Sie ein PdfDocument-Objekt.
- Laden Sie eine PDF-Datei mit der Methode PdfDocument.LoadFromFile().
- Rufen Sie die spezifische Seite über die Eigenschaft PdfDocument.Pages[index] ab.
- Erstellen Sie ein PdfTextExtractor-Objekt.
- Erstellen Sie ein PdfTextExtractOptions-Objekt und geben Sie den Rechteckbereich über dessen ExtractArea-Eigenschaft an.
- Extrahieren Sie Text aus dem Rechteck mit der Methode PdfTextExtractor.ExtractText().
- Schreiben Sie den extrahierten Text in eine TXT-Datei.
Das folgende Codebeispiel zeigt, wie Sie mit C# PDF-Text aus einem angegebenen Seitenbereich lesen.
- C#
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Specify a rectangle area
extractOptions.ExtractArea = new RectangleF(0, 180, 800, 160);
//Read PDF text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDFArea.txt", text);
}
}
}
PDF lesen, ohne das Textlayout in C# beizubehalten
Die oben genannten Methoden lesen PDF-Text Zeile für Zeile. Mit der SimpleExtraction-Strategie können Sie PDF-Text auch einfach lesen, ohne das Layout beizubehalten. Es verfolgt die aktuelle Y-Position jeder Zeichenfolge und fügt einen Zeilenumbruch in die Ausgabe ein, wenn sich die Y-Position geändert hat. Im Folgenden finden Sie die Schritte zum einfachen Lesen von PDF-Text.
- Erstellen Sie ein PdfDocument-Objekt.
- Laden Sie eine PDF-Datei mit der Methode PdfDocument.LoadFromFile().
- Rufen Sie die spezifische Seite über die Eigenschaft PdfDocument.Pages[index] ab.
- Erstellen Sie ein PdfTextExtractor-Objekt.
- Erstellen Sie ein PdfTextExtractOptions-Objekt und legen Sie die IsSimpleExtraction-Eigenschaft auf true fest.
- Extrahieren Sie Text aus der ausgewählten Seite mit der Methode PdfTextExtractor.ExtractText().
- Schreiben Sie den extrahierten Text in eine TXT-Datei.
Das folgende Codebeispiel zeigt, wie Sie mit C# PDF-Text lesen, ohne das Textlayout beizubehalten.
- C#
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true to
extractOptions.IsSimpleExtraction = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ExtractPDF.txt", text);
}
}
}
Extrahieren Sie Bilder und Tabellen in PDF in C#
Zusätzlich zum Lesen von PDF-Text in C# ermöglicht Ihnen die Bibliothek Spire.PDF for .NET auch das Extrahieren von Bildern aus PDF oder das Lesen nur der Tabellendaten in einer PDF-Datei. Über die folgenden Links gelangen Sie zu den entsprechenden offiziellen Tutorials:
- Bilder aus PDF in C# extrahieren
- Tabellendaten aus PDF in C# extrahieren
- Extrahieren Sie Tabellen aus PDF nach Excel in C#
Abschluss
In diesem Artikel werden verschiedene Möglichkeiten zum Lesen von PDF-Dateien in C# vorgestellt. Anhand der angegebenen Beispiele können Sie lernen, wie Sie PDF-Text von einer bestimmten Seite oder einem bestimmten Rechteckbereich lesen oder PDF-Dateien lesen, ohne das Textlayout beizubehalten. Darüber hinaus ist das Extrahieren von Bildern oder Tabellen in einer PDF-Datei auch mit der Bibliothek Spire.PDF for .NET möglich.
Entdecken Sie mithilfe der Dokumentation. weitere PDF-Verarbeitungs- und Konvertierungsfunktionen der .NET PDF-Bibliothek. Wenn beim Testen Probleme aufgetreten sind, wenden Sie sich bitte per E-Mail oder Forum an das technische Support-Team.
