Inhaltsverzeichnis
Über NuGet installiert
PM> Install-Package Spire.PDF
verwandte Links
PDF-Dokumente haben ein festes Layout und erlauben es Benutzern nicht, Änderungen daran vorzunehmen. Um den PDF-Inhalt wieder bearbeitbar zu machen, können Sie dies tun PDF zu Word konvertieren oder extrahieren Sie Text aus PDF. In diesem Artikel erfahren Sie, wie das geht Text aus einer bestimmten PDF-Seite extrahieren, wie man Text aus einem bestimmten Rechteckbereich extrahieren, und wie Extrahieren Sie Text mit SimpleTextExtractionStrategy in C# und VB.NET unter Verwendung von Spire.PDF for .NET.
- Extrahieren Sie Text von einer bestimmten Seite
- Extrahieren Sie Text aus einem Rechteck
- Extrahieren Sie Text mit SimpleTextExtractionStrategy
Installieren Sie Spire.PDF for .NET
Zunächst müssen Sie die im Spire.PDF for.NET-Paket enthaltenen DLL-Dateien als Referenzen in Ihrem .NET-Projekt hinzufügen. Die DLL-Dateien können entweder über diesen Link heruntergeladen oder über NuGet installiert werden.
PM> Install-Package Spire.PDF
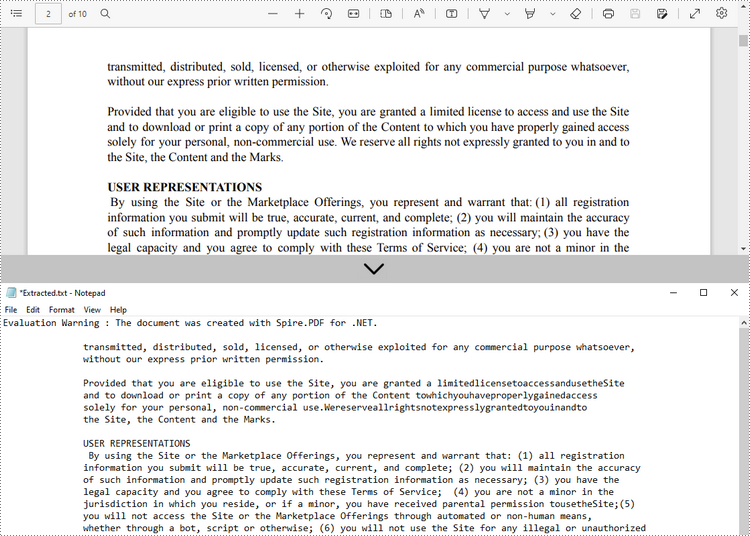
Extrahieren Sie Text von einer bestimmten Seite
Im Folgenden finden Sie die Schritte zum Extrahieren von Text aus einer bestimmten Seite eines PDF-Dokuments mit Spire.PDF for .NET.
- Erstellen Sie ein PdfDocument-Objekt.
- Laden Sie eine PDF-Datei mit der Methode PdfDocument.LoadFromFile().
- Rufen Sie die spezifische Seite über die Eigenschaft PdfDocument.Pages[index] ab.
- Erstellen Sie ein PdfTextExtractor-Objekt.
- Erstellen Sie ein PdfTextExtractOptions-Objekt und legen Sie die IsExtractAllText-Eigenschaft auf true fest.
- Extrahieren Sie Text aus der ausgewählten Seite mit der Methode PdfTextExtractor.ExtractText().
- Schreiben Sie den extrahierten Text in eine TXT-Datei.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
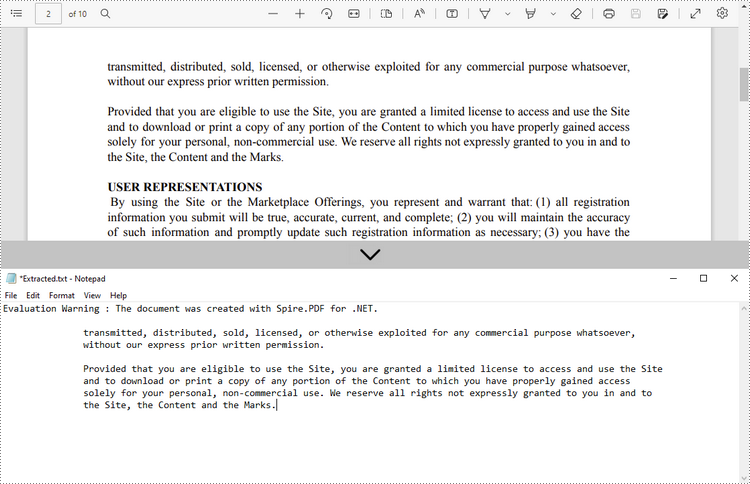
Extrahieren Sie Text aus einem Rechteck
Im Folgenden finden Sie die Schritte zum Extrahieren von Text aus einem rechteckigen Bereich einer Seite mit Spire.PDF for .NET.
- Erstellen Sie ein PdfDocument-Objekt.
- Laden Sie eine PDF-Datei mit der Methode PdfDocument.LoadFromFile().
- Rufen Sie die spezifische Seite über die Eigenschaft PdfDocument.Pages[index] ab.
- Erstellen Sie ein PdfTextExtractor-Objekt.
- Erstellen Sie ein PdfTextExtractOptions-Objekt und geben Sie den Rechteckbereich über dessen ExtractArea-Eigenschaft an.
- Extrahieren Sie Text aus dem Rechteck mit der Methode PdfTextExtractor.ExtractText().
- Schreiben Sie den extrahierten Text in eine TXT-Datei.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
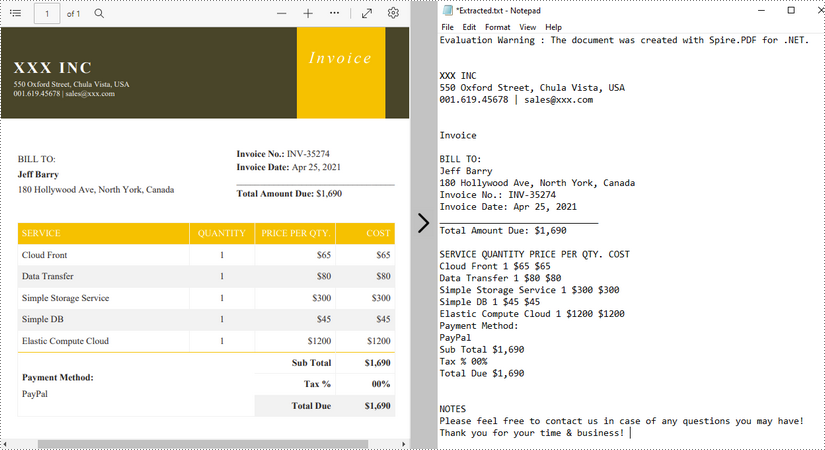
Extrahieren Sie Text mit SimpleTextExtractionStrategy
Die oben genannten Methoden extrahieren Text Zeile für Zeile. Beim Extrahieren von Text mit SimpleTextExtractionStrategy wird die aktuelle Y-Position jeder Zeichenfolge verfolgt und ein Zeilenumbruch in die Ausgabe eingefügt, wenn sich die Y-Position geändert hat. Im Folgenden finden Sie die detaillierten Schritte.
- Erstellen Sie ein PdfDocument-Objekt.
- Laden Sie eine PDF-Datei mit der Methode PdfDocument.LoadFromFile().
- Rufen Sie die spezifische Seite über die Eigenschaft PdfDocument.Pages[index] ab.
- Erstellen Sie ein PdfTextExtractor-Objekt.
- Erstellen Sie ein PdfTextExtractOptions-Objekt und legen Sie die IsSimpleExtraction-Eigenschaft auf true fest.
- Extrahieren Sie Text aus der ausgewählten Seite mit der Methode PdfTextExtractor.ExtractText().
- Schreiben Sie den extrahierten Text in eine TXT-Datei.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Beantragen Sie eine temporäre Lizenz
Wenn Sie die Bewertungsmeldung aus den generierten Dokumenten entfernen oder die Funktionseinschränkungen beseitigen möchten, wenden Sie sich bitte an uns Fordern Sie eine 30-Tage-Testlizenz an für sich selbst.
