
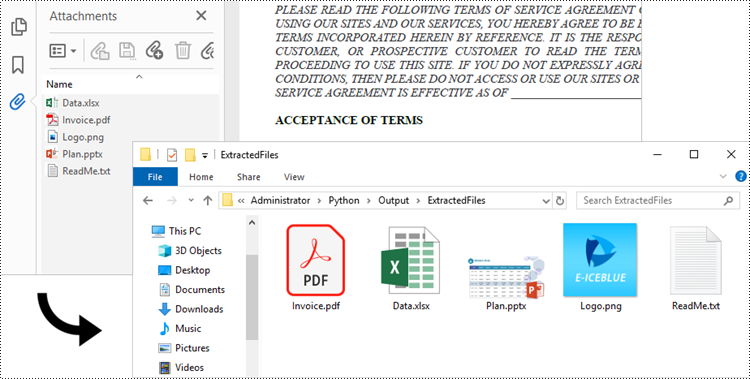
In addition to text and images, PDF files can also contain various types of attachments, such as documents, images, audio files, or other multimedia elements. Extracting attachments from PDF files allows users to retrieve and save the embedded content, enabling easy access and manipulation outside of the PDF environment. This process proves especially useful when dealing with PDFs that contain important supplementary materials, such as reports, spreadsheets, or legal documents.
In this article, you will learn how to extract attachments from a PDF document in Python using Spire.PDF for Python.
- Extract Document-Level Attachments from PDF in Python
- Extract Annotation Attachments from PDF in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Prerequisite Knowledge
There are generally two categories of attachments in PDF files: document-level attachments and annotation attachments. Below, you can find a table outlining the disparities between these two types of attachments and how they are represented in Spire.PDF.
| Attachment type | Represented by | Definition |
| Document level attachment | PdfAttachment class | A file attached to a PDF at the document level won't appear on a page, but can be viewed in the "Attachments" panel of a PDF reader. |
| Annotation attachment | PdfAnnotationAttachment class | A file attached as an annotation can be found on a page or in the "Attachments" panel. An annotation attachment is shown as a paper clip icon on the page; reviewers can double-click the icon to open the file. |
Extract Document-Level Attachments from PDF in Python
To retrieve document-level attachments in a PDF document, you can use the PdfDocument.Attachments property. Each attachment has a PdfAttachment.FileName property, which provides the name of the specific attachment, including the file extension. Additionally, the PdfAttachment.Data property allows you to access the attachment's data. To save the attachment to a specific folder, you can utilize the PdfAttachment.Data.Save() method.
The steps to extract document-level attachments from a PDF using Python are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a collection of attachments using PdfDocument.Attachments property.
- Iterate through the attachments in the collection.
- Get a specific attachment from the collection, and get the file name and data of the attachment using PdfAttachment.FileName property and PdfAttachment.Data property.
- Save the attachment to a specified folder using PdfAttachment.Data.Save() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Attachments.pdf")
# Get the attachment collection from the document
collection = doc.Attachments
# Loop through the collection
if collection.Count > 0:
for i in range(collection.Count):
# Get a specific attachment
attactment = collection.get_Item(i)
# Get the file name and data of the attachment
fileName= attactment.FileName
data = attactment.Data
# Save it to a specified folder
data.Save("Output\\ExtractedFiles\\" + fileName)
doc.Close()
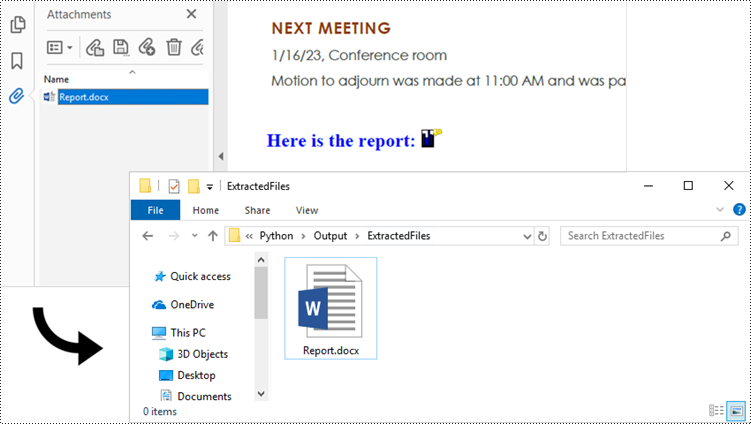
Extract Annotation Attachments from PDF in Python
The Annotations attachment is a page-based element. To retrieve annotations from a specific page, use the PdfPageBase.AnnotationsWidget property. You then need to determine if a particular annotation is an attachment. If it is, save it to the specified folder while retaining its original filename.
The following are the steps to extract annotation attachments from a PDF using Python.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Iterate though the pages in the document.
- Get the annotations from a particular page using PdfPageBase.AnnotationsWidget property.
- Iterate though the annotations, and determine if a specific annotation is an attachment annotation.
- If it is, get the file name and data of the annotation using PdfAttachmentAnnotation.FileName property and PdfAttachmentAnnotation.Data property.
- Save the annotated attachment to a specified folder.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\AnnotationAttachment.pdf")
# Iterate through the pages in the document
for i in range(doc.Pages.Count):
# Get a specific page
page = doc.Pages.get_Item(i)
# Get the annotation collection of the page
annotationCollection = page.AnnotationsWidget
# If the page has annotations
if annotationCollection.Count > 0:
# Iterate through the annotations
for j in range(annotationCollection.Count):
# Get a specific annotation
annotation = annotationCollection.get_Item(j)
# Determine if the annotation is an attachment annotation
if isinstance(annotation, PdfAttachmentAnnotationWidget):
# Get the file name and data of the attachment
fileName = annotation.FileName
byteData = annotation.Data
streamMs = Stream(byteData)
# Save the attachment into a specified folder
streamMs.Save("Output\\ExtractedFiles\\" + fileName)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
