
Managing PDF documents often involves removing annotations. Whether you're preparing documents for a presentation, sharing the final files with clients when questions are settled down, or archiving important records, deleting annotations can be essential.
Spire.PDF for Python allows users to delete annotations from PDFs in Python efficiently. Follow the instructions below to clean up your PDF files seamlessly.
- Delete Specified Annotations
- Delete All Annotations from a Page
- Delete All Annotations from the PDF Document
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install it, please refer to this tutorial: How to Install Spire.PDF for Python on Windows.
Delete Specified Annotations from PDF in Python
To delete a specified annotation from PDF documents, you need to target the annotation to be removed at first. Then you can remove it by calling the Page.AnnotationsWidget.RemoveAt() method offered by Spire.PDF for Python. This section will guide you through the whole process step by step.
Steps to remove an annotation from a page:
- Create a new Document object.
- Load a PDF document from files using Document.LoadFromFile() method.
- Get the specific page of the PDF with Document.Pages.get_Item() method.
- Delete the annotation from the page by calling Page.AnnotationsWidget.RemoveAt() method.
- Save the resulting document using Document.SaveToFile() method.
Here's the code example for you to refer to:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
doc = PdfDocument()
# Open the PDF document to be modified from the disk
doc.LoadFromFile("sample1.pdf")
# Get the first page of the document
page = doc.Pages.get_Item(0)
# Remove the 2nd annotation from the page
page.AnnotationsWidget.RemoveAt(1)
# Save the PDF document
doc.SaveToFile("output/delete_2nd_annotation.pdf", FileFormat.PDF)
doc.Close()
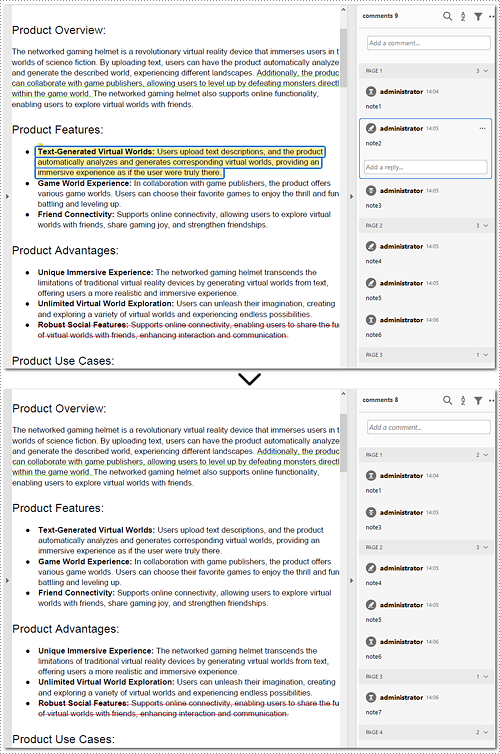
Delete All Annotations from a PDF Page in Python
The Pages.AnnotationsWidget.Clear() method provided by Spire.PDF for Python helps you to complete the task of removing each annotation from a page. This part will demonstrate how to delete all annotations from a page in Python with a detailed guide and a code example.
Steps to delete all annotations from a page:
- Create an instance of the Document class.
- Read the PDF document from the disk by Document.LoadFromFile() method.
- Remove annotations on the page using Pages.AnnotationsWidget.Clear() method.
- Write the document to disk with Document.SaveToFile() method.
Below is the code example of deleting annotations from the first page:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
document = PdfDocument()
# Load the file from the disk
document.LoadFromFile("sample1.pdf")
# Remove all annotations from the first page
document.Pages[0].AnnotationsWidget.Clear()
# Save the document
document.SaveToFile("output/delete_annotations_page.pdf", FileFormat.PDF)
document.Close()
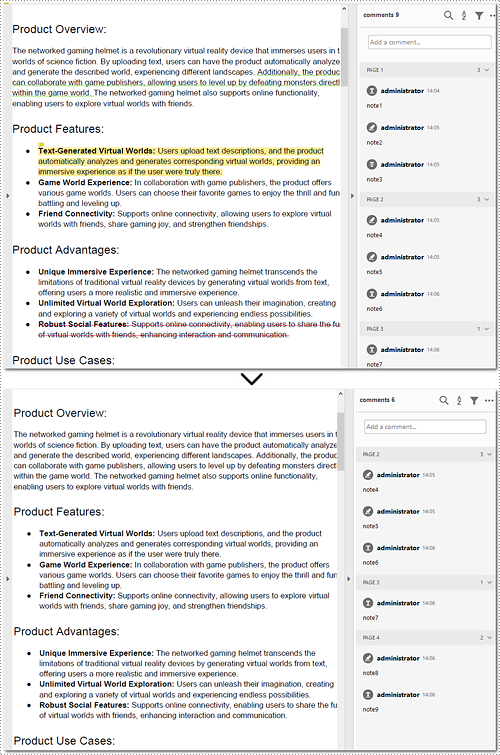
Delete All Annotations of PDF Documents in Python
Removing all annotations from a PDF document involves retrieving the annotations first, which means you need to loop through each page to ensure that every annotation is deleted. The section will introduce how to accomplish the task in Python, providing detailed steps and an example to assist in cleaning up PDF documents.
Steps to remove all annotations of the whole PDF document:
- Instantiate a Document object.
- Open the document from files using Document.LoadFromFile() method.
- Loop through pages of the PDF document.
- Get each page of the PDF document with Document.Pages.get_Item() method.
- Remove all annotations from each page using Page.AnnotationsWidget.Clear() method.
- Save the document to your local file with Document.SaveToFile() method.
Here is the example for reference:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of PDF class
document = PdfDocument()
# Load the file to be operated from the disk
document.LoadFromFile("sample1.pdf")
# Loop through all pages in the PDF document
for i in range(document.Pages.Count):
# Get a specific page
page = document.Pages.get_Item(i)
# Remove all annotations from the page
page.AnnotationsWidget.Clear()
# Save the resulting document
document.SaveToFile("output/delete_all_annotations.pdf", FileFormat.PDF)
document.Close()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
