
Hyperlinks in Word documents can lead readers to a webpage, an external file, an email address, and a specific place of the document being read. They are commonly used in Word documents for their convenience. This article will teach you how to use Spire.Doc for Java to find and extract hyperlinks in Word documents, including hypertexts and links.
- Find and Extract a Specified Hyperlink in a Word Document
- Find and Extract All the Hyperlinks in a Word Document
Install Spire.Doc for Java
First, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>13.6.2</version>
</dependency>
</dependencies>
Find and Extract a Specified Hyperlink in a Word Document
The detailed steps are as follows:
- Create a Document instance and load a Word document from disk using Document.loadFromFile() method.
- Create an object of ArrayList<Field>.
- Iterate through the items in the sections to find all hyperlinks.
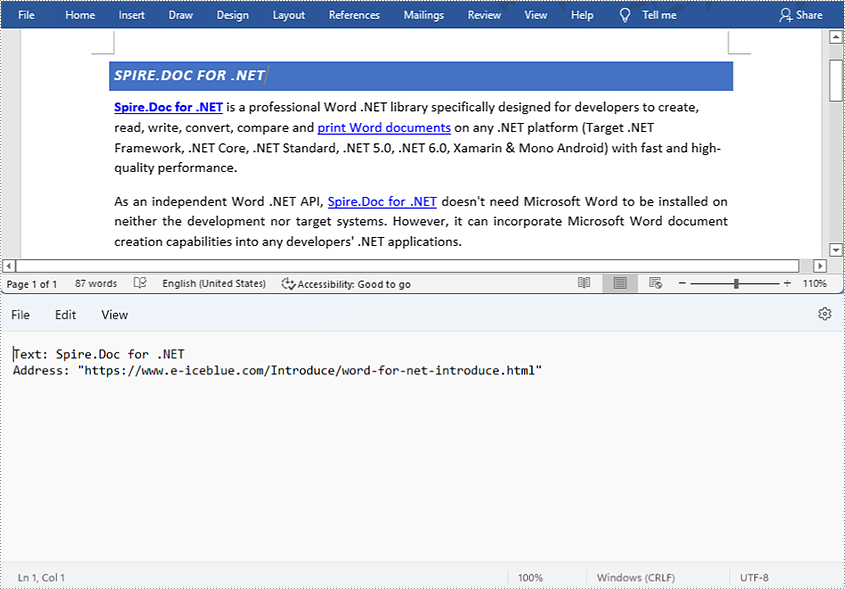
- Get the text of the first hyperlink using Field.get().getFieldText() method and get its link using Field.get().getValue() method.
- Save the text and the link of the first hyperlink to a TXT file using custom method writeStringToText().
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.Field;
import java.io.*;
import java.util.ArrayList;
public class findHyperlinks {
public static void main(String[] args) throws IOException {
//Create a Document instance and load a Word document from file
String input = "D:/testp/test.docx";
Document doc = new Document();
doc.loadFromFile(input);
//Create an object of ArrayList
ArrayList hyperlinks = new ArrayList();
//Iterate through the items in the sections to find all hyperlinks
for (Section section : (Iterable) doc.getSections()) {
for (DocumentObject object : (Iterable) section.getBody().getChildObjects()) {
if (object.getDocumentObjectType().equals(DocumentObjectType.Paragraph)) {
Paragraph paragraph = (Paragraph) object;
for (DocumentObject cObject : (Iterable) paragraph.getChildObjects()) {
if (cObject.getDocumentObjectType().equals(DocumentObjectType.Field)) {
Field field = (Field) cObject;
if (field.getType().equals(FieldType.Field_Hyperlink)) {
hyperlinks.add(field);
}
}
}
}
}
}
//Get the text and the address of the first hyperlink
String hyperlinksText = hyperlinks.get(0).getFieldText();
String hyperlinkAddress = hyperlinks.get(0).getValue();
//Save the text and the link of the first hyperlink to a TXT file
String output = "D:/javaOutput/HyperlinkTextAndLink.txt";
writeStringToText("Text:\r\n" + hyperlinksText+ "\r\n" + "Link:\r\n" + hyperlinkAddress, output);
}
//Create a method to write the text and link of hyperlinks to a TXT file
public static void writeStringToText(String content, String textFileName) throws IOException {
File file = new File(textFileName);
if (file.exists())
{
file.delete();
}
FileWriter fWriter = new FileWriter(textFileName, true);
try {
fWriter.write(content);
} catch (IOException ex) {
ex.printStackTrace();
} finally {
try {
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
Find and Extract All the Hyperlinks in a Word Document
The detailed steps are as follows:
- Create a Document instance and load a Word document from disk using Document.loadFromFile() method.
- Create an object of ArrayList<Field>.
- Iterate through the items in the sections to find all hyperlinks.
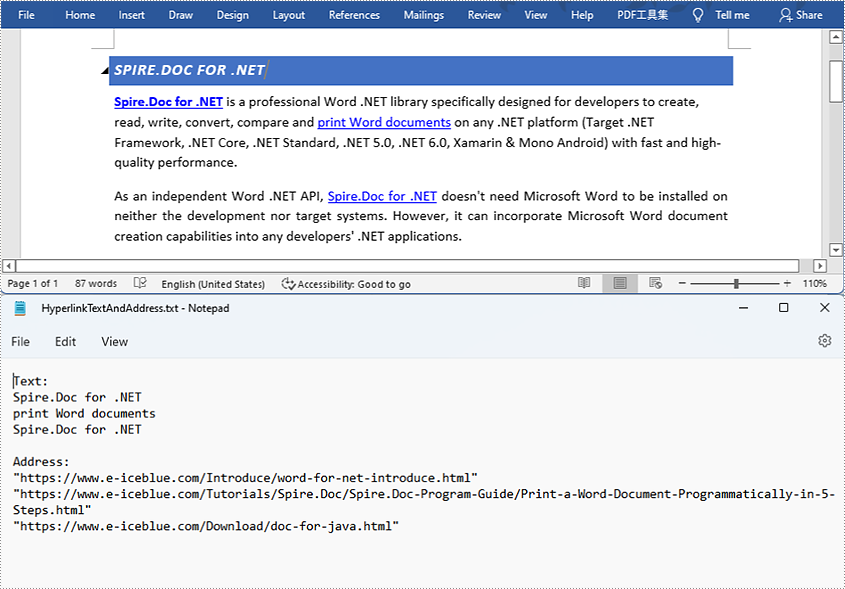
- Get the texts of the hyperlinks using Field.get().getFieldText() method and get their links using Field.get().getValue() method.
- Save the text and the links of the hyperlinks to a TXT file using custom method writeStringToText().
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.Field;
import java.io.*;
import java.util.ArrayList;
public class findHyperlinks {
public static void main(String[] args) throws IOException {
//Create a Document instance and load a Word document from file
String input = "D:/testp/test.docx";
Document doc = new Document();
doc.loadFromFile(input);
//Create an object of ArrayList
ArrayList hyperlinks = new ArrayList();
String hyperlinkText = "";
String hyperlinkAddress = "";
//Iterate through the items in the sections to find all hyperlinks
for (Section section : (Iterable) doc.getSections()) {
for (DocumentObject object : (Iterable) section.getBody().getChildObjects()) {
if (object.getDocumentObjectType().equals(DocumentObjectType.Paragraph)) {
Paragraph paragraph = (Paragraph) object;
for (DocumentObject cObject : (Iterable) paragraph.getChildObjects()) {
if (cObject.getDocumentObjectType().equals(DocumentObjectType.Field)) {
Field field = (Field) cObject;
if (field.getType().equals(FieldType.Field_Hyperlink)) {
hyperlinks.add(field);
//Get the texts and links of all hyperlinks
hyperlinkText += field.getFieldText() + "\r\n";
hyperlinkAddress += field.getValue() + "\r\n";
}
}
}
}
}
}
//Save the texts and the links of the hyperlinks to a TXT file
String output = "D:/javaOutput/HyperlinksTextsAndLinks.txt";
writeStringToText("Text:\r\n " + hyperlinkText + "\r\n" + "Link:\r\n" + hyperlinkAddress + "\r\n", output);
}
//Create a method to write the text and link of hyperlinks to a TXT file
public static void writeStringToText(String content, String textFileName) throws IOException {
File file = new File(textFileName);
if (file.exists())
{
file.delete();
}
FileWriter fWriter = new FileWriter(textFileName, true);
try {
fWriter.write(content);
} catch (IOException ex) {
ex.printStackTrace();
} finally {
try {
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
