
HTML (Hypertext Markup Language) has become one of the most commonly used text markup languages on the Internet, and nearly all web pages are created using HTML. While HTML contains numerous tags and formatting information, the most valuable content is typically the visible text. It is important to know how to extract the text content from an HTML file when users intend to utilize it for tasks such as editing, AI training, or storing in databases. This article will demonstrate how to extract text from HTML using Spire.Doc for Java within Java programs.
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>13.4.1</version>
</dependency>
</dependencies>
Extract Text from HTML File
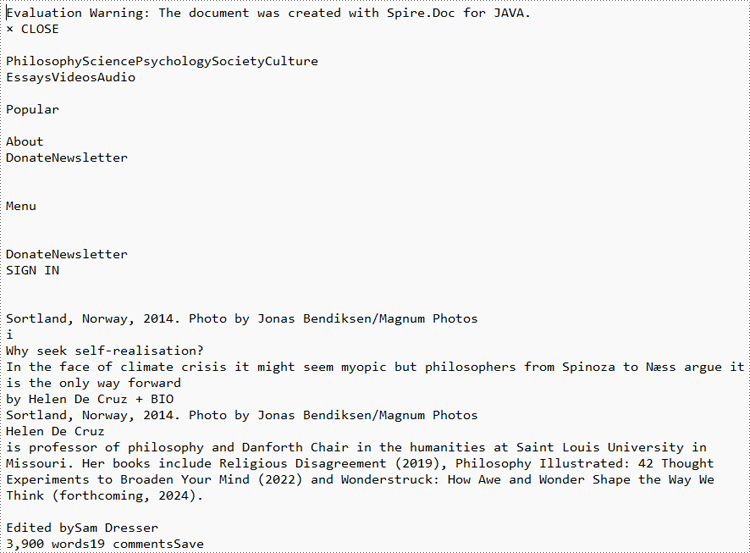
Spire.Doc for Java supports loading HTML files using the Document.loadFromFile(fileName, FileFormat.Html) method. Then, users can use Document.getText() method to get the text that is visible in browsers and write it to a TXT file. The detailed steps are as follows:
- Create an object of Document class.
- Load an HTML file using Document.loadFromFile(fileName, FileFormat.Html) method.
- Get the text of the HTML file using Document.getText() method.
- Write the text to a TXT file.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTextFromHTML {
public static void main(String[] args) throws IOException {
//Create an object of Document class
Document doc = new Document();
//Load an HTML file
doc.loadFromFile("Sample.html", FileFormat.Html);
//Get text from the HTML file
String text = doc.getText();
//Write the text to a TXT file
FileWriter fileWriter = new FileWriter("HTMLText.txt");
fileWriter.write(text);
fileWriter.close();
}
}
HTML Web Page:

Extracted Text:
Extract Text from URL
To extract text from a URL, users need to create a custom method to retrieve the HTML file from the URL and then extract the text from it. The detailed steps are as follows:
- Create an object of Document class.
- Use the custom method readHTML() to get the HTML file from a URL and return the file path.
- Load the HTML file using Document.loadFromFile(filename, FileFormat.Html) method.
- Get the text from the HTML file using Document.getText() method.
- Write the text to a TXT file.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
public class ExtractTextFromURL {
public static void main(String[] args) throws IOException {
//Create an object of Document
Document doc = new Document();
//Call the custom method to load the HTML file from a URL
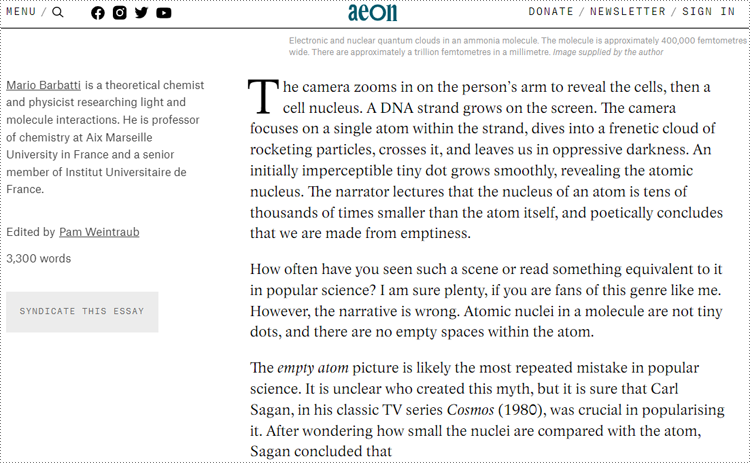
doc.loadFromFile(readHTML("https://aeon.co/essays/how-to-face-the-climate-crisis-with-spinoza-and-self-knowledge", "output.html"), FileFormat.Html);
//Get the text from the HTML file
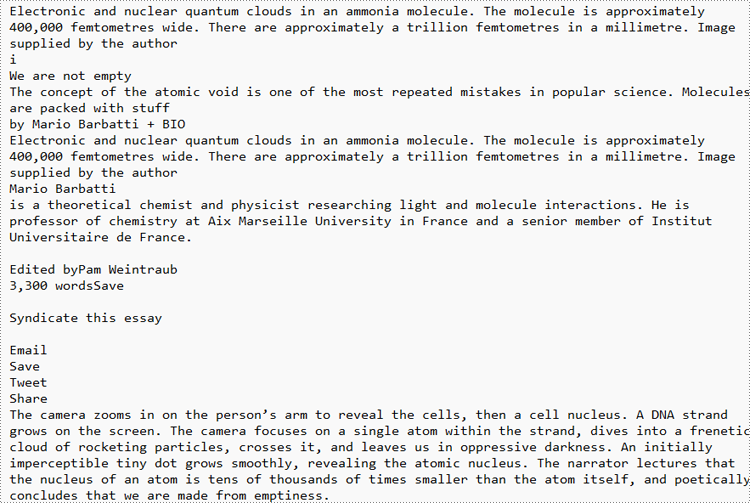
String urlText = doc.getText();
//Write the text to a TXT file
FileWriter fileWriter = new FileWriter("URLText.txt");
fileWriter.write(urlText);
}
public static String readHTML(String urlString, String saveHtmlFilePath) throws IOException {
//Create an object of URL class
URL url = new URL(urlString);
//Open the URL
URLConnection connection = url.openConnection();
//Save the url as an HTML file
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(saveHtmlFilePath), "UTF-8"));
String line;
while ((line = reader.readLine()) != null) {
writer.write(line);
writer.newLine();
}
reader.close();
writer.close();
//Return the file path of the saved HTML file
return saveHtmlFilePath;
}
}
URL Web Page:
Extracted Text:
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
