
Extracting text from a PDF document is a process that allows one to retrieve the textual content within a PDF file. PDFs, or Portable Document Format files, are widely used for their ability to preserve the formatting and layout of documents across different platforms. However, extracting text from a PDF can be necessary when you need to work with the text separately, such as analyzing data, conducting research, or converting it into another format. In this article, you will learn how to extract text from a PDF document in Python using Spire.PDF for Python.
- Extract Text from a Particular Page in Python
- Extract Text from a Rectangle Area in Python
- Extract Text from a PDF Document Using Simply Extraction Strategy in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Extract Text from a Particular Page in Python
The PdfTextExtractor class in Spire.PDF for Python allows you to extract text from a particular page, while the PdfTextExtractOptions class enables you to control the extraction process and define how the text will be extracted. The following are the steps to extract text from a certain page of a PDF document.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and set the IsExtractAllText property to true.
- Extract text from the selected page using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile('C:/Users/Administrator/Desktop/Terms of service.pdf')
# Get a specific page
page = doc.Pages[1]
# Create a PdfTextExtractot object
textExtractor = PdfTextExtractor(page)
# Create a PdfTextExtractOptions object
extractOptions = PdfTextExtractOptions()
# Set IsExtractAllText to Ture
extractOptions.IsExtractAllText = True
# Extract text from the page keeping white spaces
text = textExtractor.ExtractText(extractOptions)
# Write text to a txt file
with open('output/TextOfPage.txt', 'w') as file:
file.write(text)

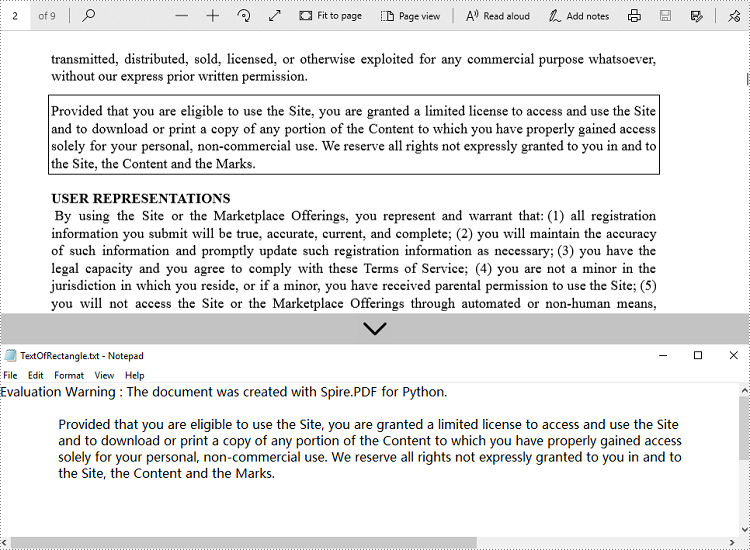
Extract Text from a Rectangle Area in Python
The PdfTextExtactOptions.ExtractArea property specifies a rectangle area from which the text will be extracted. The following are the steps to extract text from a rectangle area of a page using Spire.PDF for Python.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and specify the rectangle area through the ExtractArea property of it.
- Extract text from the rectangle using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile('C:/Users/Administrator/Desktop/Terms of service.pdf')
# Get a specific page
page = doc.Pages[1]
# Create a PdfTextExtractot object
textExtractor = PdfTextExtractor(page)
# Create a PdfTextExtractOptions object
extractOptions = PdfTextExtractOptions()
# Set the rectangle area
extractOptions.ExtractArea = RectangleF(0.0, 100.0, 890.0, 80.0)
# Extract text from the rectangle area keeping white spaces
text = textExtractor.ExtractText(extractOptions)
# Write text to a txt file
with open('output/TextOfRectangle.txt', 'w') as file:
file.write(text)
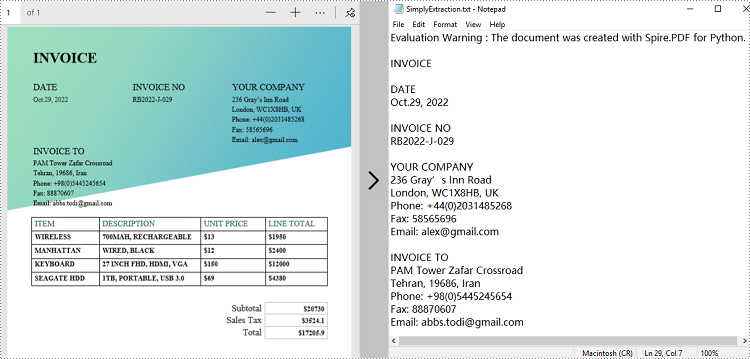
Extract Text from a PDF Document Using Simply Extraction Strategy in Python
The above methods extract text line by line. When extracting text using SimpleExtraction strategy, it keeps track of the current Y position of each string and inserts a line break into the output if the Y position has changed. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object and set the IsSimpleExtraction property to true.
- Extract text from the selected page using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile('C:/Users/Administrator/Desktop/Invoice.pdf')
# Get a specific page
page = doc.Pages[0]
# Create a PdfTextExtractot object
textExtractor = PdfTextExtractor(page)
# Create a PdfTextExtractOptions object
extractOptions = PdfTextExtractOptions()
# Set IsSimpleExtraction to Ture
extractOptions.IsSimpleExtraction = True
# Extract text from the page using SimpleExtraction strategy
text = textExtractor.ExtractText(extractOptions)
# Write text to a txt file
with open('output/SimplyExtraction.txt', 'w') as file:
file.write(text)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

