
Annotations in PDF documents play a crucial role in enhancing collaboration, emphasizing key points, or providing additional context. Extracting annotations is essential for efficiently analyzing PDF content, but manual extraction can be tedious. This guide demonstrates how to extract annotations from PDF with Python using Spire.PDF for Python, providing a faster and more flexible solution to access important information.
- Extract Specified Annotations from PDF Documents
- Extract All Annotations from a PDF Page
- Extract All Annotations from PDF Files
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install it, please refer to this tutorial: How to Install Spire.PDF for Python on Windows.
Extract Specified Annotations from PDF Documents
Although Adobe Acrobat offers a built-in one-click annotation extraction feature, it lacks flexibility when handling specific annotations. If you only need to extract one or a few annotations, you must manually locate and copy them, which can be inefficient, especially when working with PDFs containing multiple annotations. Spire.PDF (short for Spire.PDF for Python), however, provides the PdfAnnotationCollection.get_item() method, enabling targeted extraction of specific annotations, making PDF annotation management more flexible and efficient.
Steps to extract specified annotations from PDF:
- Create an object of PdfDocument class.
- Load a PDF document from the local storage with PdfDocument.LoadFromFile() method.
- Get a page using PdfDocument.Pages[] property, and access the annotations collection with PdfPageBase.AnnotationsWidget property.
- Create a list to store annotation information.
- Access the specified annotation using PdfAnnotationCollection.get_Item() method.
- Append annotation details to the list.
- Save the list as a Text file.
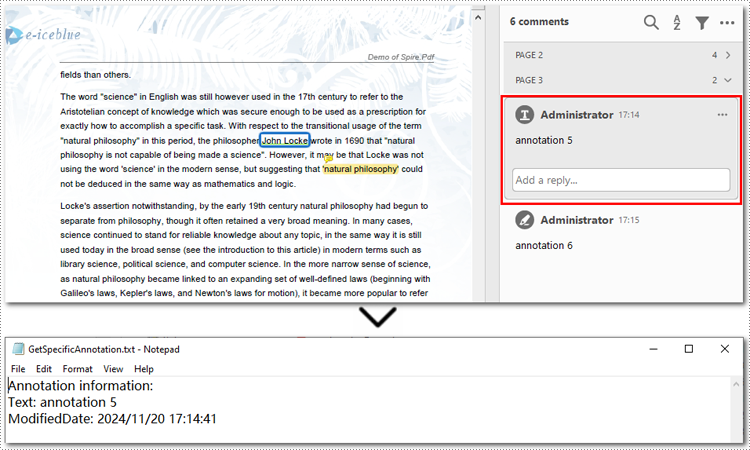
Here is the code example of exporting the first annotation on the third page:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
pdf = PdfDocument()
# Load the file from disk
pdf.LoadFromFile( "Sample.pdf")
# Get the third page
page = pdf.Pages[2]
# Access the annotations on the page
annotations = page.AnnotationsWidget
# Create a list to save information of annotations
sb = []
# Access the first annotation on the page
annotation = annotations.get_Item(0)
# Append the annotation details to the list
sb.append("Annotation information: ")
sb.append("Text: " + annotation.Text)
modifiedDate = annotation.ModifiedDate.ToString()
sb.append("ModifiedDate: " + modifiedDate)
# Save the list as a Text file
with open("GetSpecificAnnotation.txt", "w", encoding="utf-8") as file:
file.write("\n".join(sb))
# Close the PDF file
pdf.Close()
Extract All Annotations from a PDF Page
To export all annotations from a specified PDF page, you can still use the PdfPageBase.AnnotationsWidget property along with the PdfAnnotationCollection.get_item() method. However, you will need to iterate through all the annotations on the page to ensure none are missed. Below are the steps and code examples to guide you through the process.
Steps to extract annotations from PDF pages:
- Create a PdfDocument instance.
- Read a PDF document from the local storage with PdfDocument.LoadFromFile() method.
- Access the annotation collection on the specified page using PdfDocument.Pages.AnnotationsWidget property.
- Create a list to store annotation information.
- Loop through annotations on a certain page.
- Retrieve each annotation using PdfAnnotationCollection.get_Item() method.
- Add annotation details to the list.
- Save the list as a Text file.
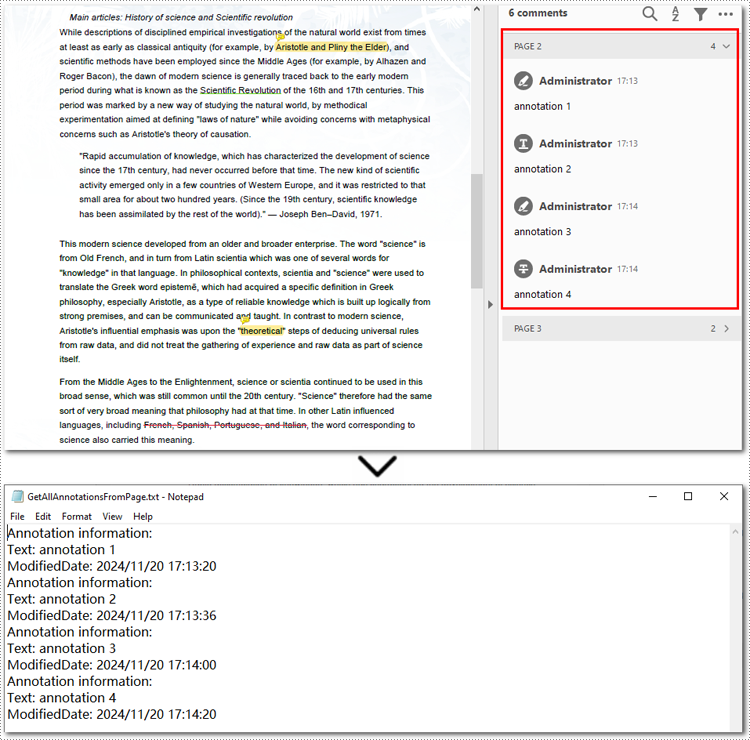
Below is the code example of extracting all annotations on the second page:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
pdf = PdfDocument()
# Load the file from disk
pdf.LoadFromFile("Sample.pdf")
# Get all annotations from the second page
annotations = pdf.Pages[1].AnnotationsWidget
# Create a list to maintain annotation details
sb = []
# Loop through annotations on the page
if annotations.Count > 0:
for i in range(annotations.Count):
# Get the current annotation
annotation = annotations.get_Item(i)
# Get the annotation details
if isinstance(annotation, PdfPopupAnnotationWidget):
continue
sb.append("Annotation information: ")
sb.append("Text: " + annotation.Text)
modifiedDate = annotation.ModifiedDate.ToString()
sb.append("ModifiedDate: " + modifiedDate)
# Save annotations as a Text file
with open("GetAllAnnotationsFromPage.txt", "w", encoding="utf-8") as file:
file.write("\n".join(sb))
# Release resources
pdf.Close()
Extract All Annotations from PDF Files
The final section of this guide illustrates how to extract all annotations from a PDF document using Python. The process is similar to exporting annotations from a single page but involves iterating through each page, traversing all annotations, and accessing their details. Finally, the extracted annotation details are saved to a text file for further use. Let’s take a closer look at the detailed steps.
Steps to extract all annotations from a PDF document:
- Create an instance of PdfDocument class.
- Read a PDF document from the disk with PdfDocument.LoadFromFile() method.
- Initialize a list to store annotation information.
- Loop through all pages and access the annotation collection with PdfDocument.Pages.AnnotationsWidget property.
- Iterate each annotation in the collection and get annotations using PdfAnnotationCollection.get_item() method.
- Append annotation details to the list.
- Output the list as a Text file.
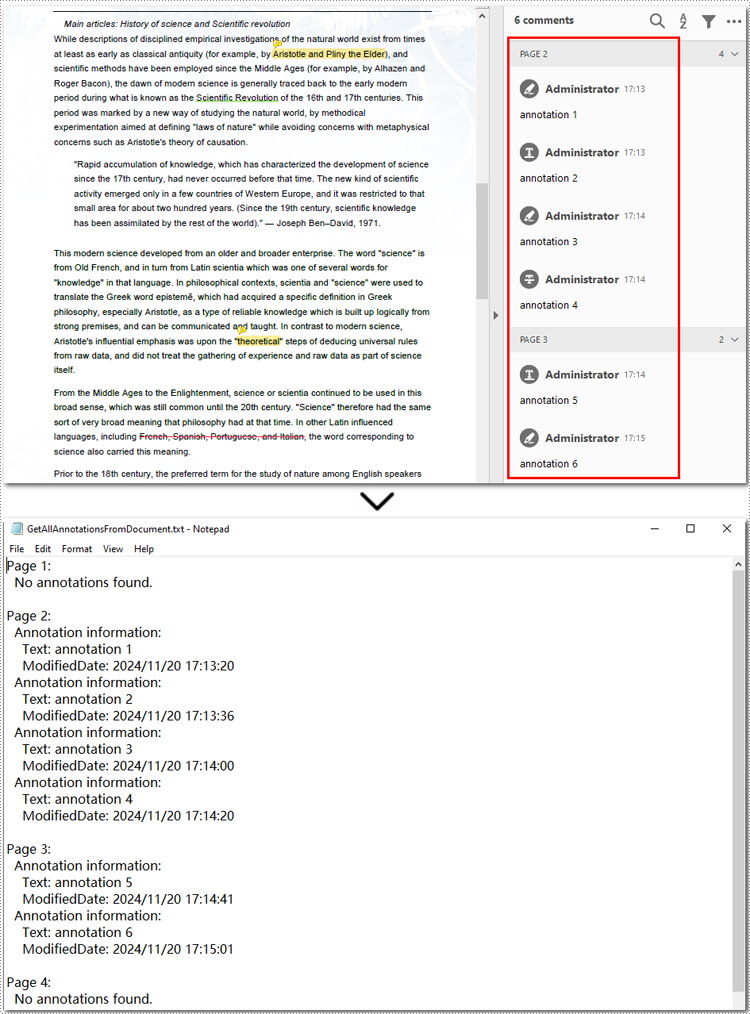
Here is an example of exporting all annotations from a PDF file:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a new PDF document
pdf = PdfDocument()
# Load the file from disk
pdf.LoadFromFile("Sample.pdf")
# Create a list to save annotation details
sb = []
# Iterate through all pages in the PDF document
for pageIndex in range(pdf.Pages.Count):
sb.append(f"Page {pageIndex + 1}:")
# Access the annotation collection of the current page
annotations = pdf.Pages[pageIndex].AnnotationsWidget
# Loop through annotations in the collection
if annotations.Count > 0:
for i in range(annotations.Count):
# Get the annotations of the current page
annotation = annotations.get_Item(i)
# Skip invalid annotations (empty text and default date)
if not annotation.Text.strip() and annotation.ModifiedDate.ToString() == "0001/1/1 0:00:00":
continue
# Extract annotation information
sb.append("Annotation information: ")
sb.append("Text: " + (annotation.Text.strip() or "N/A"))
modifiedDate = annotation.ModifiedDate.ToString()
sb.append("ModifiedDate: " + modifiedDate)
else:
sb.append("No annotations found.")
# Add a blank line after each page
sb.append("")
# Save all annotations to a file
with open("GetAllAnnotationsFromDocument.txt", "w", encoding="utf-8") as file:
file.write("\n".join(sb))
# Close the PDF document
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

