
Efficiently managing Word documents often requires the task of splitting them into smaller sections. However, manually performing this task can be time-consuming and labor-intensive. Fortunately, Spire.Doc for Python provides a convenient and efficient way to programmatically segment Word documents, helping users to extract specific parts of a document, split lengthy documents into smaller chunks, and streamline data extraction. This article demonstrates how to use Spire.Doc for Python to split a Word document into multiple documents in Python.
The splitting of a Word document is typically done by page breaks and section breaks due to the dynamic nature of document content. Therefore, this article focuses on the following two parts:
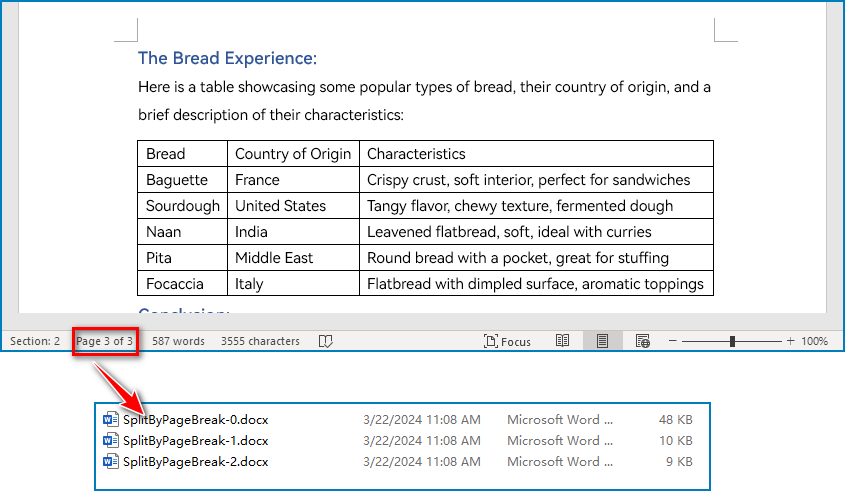
- Split a Word Document by Page Breaks with Python
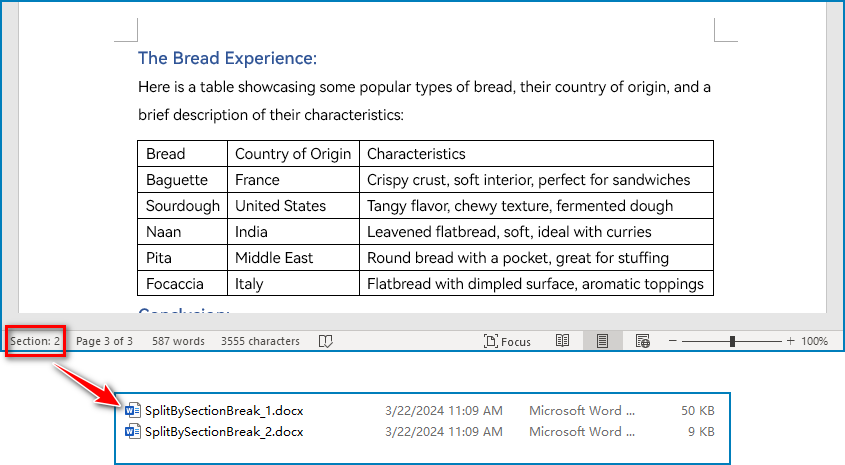
- Split a Word Document by Section Breaks with Python
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to: How to Install Spire.Doc for Python on Windows
Split a Word Document by Page Breaks with Python
Page breaks allow for the forced pagination of a document, thereby achieving a fixed division of content. By using page breaks as divisions, we can split a Word document into smaller content-related documents. The detailed steps for splitting a Word document by page breaks are as follows:
- Create an instance of Document class and load a Word document using Document.LoadFromFile() method.
- Create a new document, add a section to it using Document.AddSection() method.
- Iterate through all body child objects in each section in the original document and check if the child object is a paragraph or a table.
- If the child object is a table, add it to the section in the new document using Section.Body.ChildObjects.Add() method.
- If the child object is a paragraph, add the paragraph object to the section in the new document. Then, iterate through all child objects of the paragraph and check if a child object is a page break.
- If the child object in the paragraph is a page break, get its index using Paragraph.ChildObjects.IndexOf() method and remove it from the paragraph by its index.
- Save the new document using Document.SaveToFile() method and repeat the above process.
- Python
from spire.doc import *
from spire.doc.common import *
inputFile = "Sample.docx"
outputFolder = "output/SplitDocument/"
# Create an instance of Document
original = Document()
# Load a Word document
original.LoadFromFile(inputFile)
# Create a new word document and add a section to it
newWord = Document()
section = newWord.AddSection()
original.CloneDefaultStyleTo(newWord)
original.CloneThemesTo(newWord)
original.CloneCompatibilityTo(newWord)
index = 0
# Iterate through all sections of original document
for m in range(original.Sections.Count):
sec = original.Sections.get_Item(m)
# Iterate through all body child objects of each section
for k in range(sec.Body.ChildObjects.Count):
obj = sec.Body.ChildObjects.get_Item(k)
if isinstance(obj, Paragraph):
para = obj if isinstance(obj, Paragraph) else None
sec.CloneSectionPropertiesTo(section)
# Add paragraph object in original section into section of new document
section.Body.ChildObjects.Add(para.Clone())
for j in range(para.ChildObjects.Count):
parobj = para.ChildObjects.get_Item(j)
if isinstance(parobj, Break) and ( parobj if isinstance(parobj, Break) else None).BreakType == BreakType.PageBreak:
# Get the index of page break in paragraph
i = para.ChildObjects.IndexOf(parobj)
# Remove the page break from its paragraph
section.Body.LastParagraph.ChildObjects.RemoveAt(i)
# Save the new document
resultF = outputFolder
resultF += "SplitByPageBreak-{0}.docx".format(index)
newWord.SaveToFile(resultF, FileFormat.Docx)
index += 1
# Create a new document and add a section
newWord = Document()
section = newWord.AddSection()
original.CloneDefaultStyleTo(newWord)
original.CloneThemesTo(newWord)
original.CloneCompatibilityTo(newWord)
sec.CloneSectionPropertiesTo(section)
# Add paragraph object in original section into section of new document
section.Body.ChildObjects.Add(para.Clone())
if section.Paragraphs[0].ChildObjects.Count == 0:
# Remove the first blank paragraph
section.Body.ChildObjects.RemoveAt(0)
else:
# Remove the child objects before the page break
while i >= 0:
section.Paragraphs[0].ChildObjects.RemoveAt(i)
i -= 1
if isinstance(obj, Table):
# Add table object in original section into section of new document
section.Body.ChildObjects.Add(obj.Clone())
# Save the document
result = outputFolder+"SplitByPageBreak-{0}.docx".format(index)
newWord.SaveToFile(result, FileFormat.Docx2013)
newWord.Close()
Split a Word Document by Section Breaks with Python
Sections divide a Word document into different logical parts and allow for independent formatting for each section. By splitting a Word document into sections, we can obtain multiple documents with relatively independent content and formatting. The detailed steps for splitting a Word document by section breaks are as follows:
- Create an instance of Document class and load a Word document using Document.LoadFromFile() method.
- Iterate through each section in the document.
- Get a section using Document.Sections.get_Item() method.
- Create a new Word document and copy the section in the original document to the new document using Document.Sections.Add() method.
- Save the new document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an instance of Document class
document = Document()
# Load a Word document
document.LoadFromFile("Sample.docx")
# Iterate through all sections
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
result = "output/SplitDocument/" + "SplitBySectionBreak_{0}.docx".format(i+1)
# Create a new Word document
newWord = Document()
# Add the section to the new document
newWord.Sections.Add(section.Clone())
#Save the new document
newWord.SaveToFile(result)
newWord.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

