
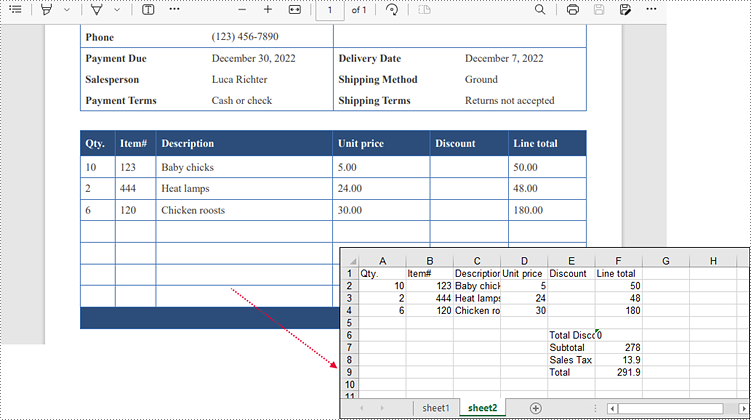
Extracting tables from PDFs and converting them into Excel format offers numerous advantages, such as enabling data manipulation, analysis, and visualization in a more versatile and familiar environment. This task is particularly valuable for researchers, analysts, and professionals dealing with large amounts of tabular data. In this article, you will learn how to extract tables from PDF to Excel in C# and VB.NET using Spire.Office for .NET.
Install Spire.Office for .NET
To begin with, you need to add the Spire.Pdf.dll and the Spire.Xls.dll included in the Spire.Office for.NET package as references in your .NET project. Spire.PDF is responsible for extracting data from PDF tables, and Spire.XLS is responsible for creating an Excel document based on the data obtained from PDF.
The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.Office
Extract Tables from PDF to Excel in C#, VB.NET
Spire.PDF for .NET offers the PdfTableExtractor.ExtractTable(int pageIndex) method to extract tables from a specific page of a searchable PDF document. The text of a specific cell can be accessed using PdfTable.GetText(int rowIndex, int columnIndex) method. This value can be then written to a worksheet through Worksheet.Range[int row, int column].Value property offered by Spire.XLS for .NET. The following are the detailed steps.
- Create an instance of PdfDocument class.
- Load the sample PDF document using PdfDocument.LoadFromFile() method.
- Extract tables from a specific page using PdfTableExtractor.ExtractTable() method.
- Get text of a certain table cell using PdfTable.GetText() method.
- Create a Workbook object.
- Write the cell data obtained from PDF into a worksheet through Worksheet.Range.Value property.
- Save the workbook to an Excel file using Workbook.SaveTofile() method.
The following code example extracts all tables from a PDF document and writes each of them into an individual worksheet within a workbook.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Utilities;
using Spire.Xls;
namespace ExtractTablesToExcel
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load the sample PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\table.pdf");
//Create a Workbook object
Workbook workbook = new Workbook();
//Clear default worksheets
workbook.Worksheets.Clear();
//Initialize an instance of PdfTableExtractor class
PdfTableExtractor extractor = new PdfTableExtractor(doc);
//Declare a PdfTable array
PdfTable[] tableList = null;
int sheetNumber = 1;
//Loop through the pages
for (int pageIndex = 0; pageIndex < doc.Pages.Count; pageIndex++)
{
//Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex);
//Determine if the table list is null
if (tableList != null && tableList.Length > 0)
{
//Loop through the table in the list
foreach (PdfTable table in tableList)
{
//Add a worksheet
Worksheet sheet = workbook.Worksheets.Add(String.Format("sheet{0}", sheetNumber));
//Get row number and column number of a certain table
int row = table.GetRowCount();
int column = table.GetColumnCount();
//Loop though the row and colunm
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
//Get text from the specific cell
string text = table.GetText(i, j);
//Write text to a specified cell
sheet.Range[i + 1, j + 1].Value = text;
}
}
sheetNumber++;
}
}
}
//Save to file
workbook.SaveToFile("ToExcel.xlsx", ExcelVersion.Version2013);
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

