
Bookmarks in PDF function as interactive table of contents, allowing users to quickly jump to specific sections within the document. Extracting these bookmarks not only provides a comprehensive overview of the document's structure, but also reveals its core parts or key information, providing users with a streamlined and intuitive method of accessing content. In this article, you will learn how to extract PDF bookmarks in Java using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.10.7</version>
</dependency>
</dependencies>
Extract Bookmarks from PDF in Java
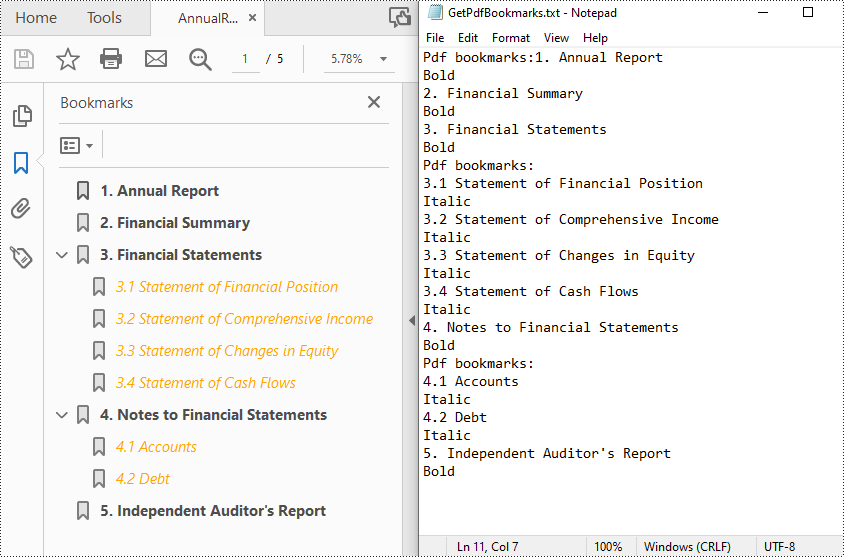
With Spire.PDF for Java, you can create custom methods GetBookmarks() and GetChildBookmark() to get the title and text styles of both parent and child bookmarks in a PDF file, then export them to a TXT file. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Get bookmarks collection in the PDF file using PdfDocument.getBookmarks() method.
- Call custom methods GetBookmarks() and GetChildBookmark() to get the text content and text style of parent and child bookmarks.
- Export the extracted PDF bookmarks to a TXT file.
- Java
import com.spire.pdf.*;
import com.spire.pdf.bookmarks.*;
import java.io.*;
public class getAllPdfBookmarks {
public static void main(String[] args) throws IOException{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF file
pdf.loadFromFile("AnnualReport.pdf");
//Get bookmarks collections of the PDF file
PdfBookmarkCollection bookmarks = pdf.getBookmarks();
//Get the contents of bookmarks and save them to a TXT file
GetBookmarks(bookmarks, "GetPdfBookmarks.txt");
}
private static void GetBookmarks(PdfBookmarkCollection bookmarks, String result) throws IOException {
//create a StringBuilder instance
StringBuilder content = new StringBuilder();
//Get parent bookmarks information
if (bookmarks.getCount() > 0) {
content.append("Pdf bookmarks:");
for (int i = 0; i < bookmarks.getCount(); i++) {
PdfBookmark parentBookmark = bookmarks.get(i);
content.append(parentBookmark.getTitle() + "\r\n");
//Get the text style
String textStyle = parentBookmark.getDisplayStyle().toString();
content.append(textStyle + "\r\n");
GetChildBookmark(parentBookmark, content);
}
}
writeStringToTxt(content.toString(),result);
}
private static void GetChildBookmark(PdfBookmark parentBookmark, StringBuilder content)
{
//Get child bookmarks information
if (parentBookmark.getCount() > 0)
{
content.append("Pdf bookmarks:" + "\r\n");
for (int i = 0; i < parentBookmark.getCount(); i++)
{
PdfBookmark childBookmark = parentBookmark.get(i);
content.append(childBookmark.getTitle() +"\r\n");
//Get the text style
String textStyle = childBookmark.getDisplayStyle().toString();
content.append(textStyle +"\r\n");
GetChildBookmark(childBookmark, content);
}
}
}
public static void writeStringToTxt(String content, String txtFileName) throws IOException {
FileWriter fWriter = new FileWriter(txtFileName, true);
try {
fWriter.write(content);
} catch (IOException ex) {
ex.printStackTrace();
} finally {
try {
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

