

Extracting tables from Word documents is essential for many applications, as they often contain critical data for analysis, reporting, or system integration. By automating this process with Java, developers can create robust applications that seamlessly access this structured data, enabling efficient conversion into alternative formats suitable for databases, spreadsheets, or web-based visualizations. This article will demonstrate how to use Spire.Doc for Java to efficiently extract tables from Word documents in Java programs.
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>13.4.1</version>
</dependency>
</dependencies>
Extract Tables from Word Documents with Java
With Spire.Doc for Java, developers can extract tables from Word documents using the Section.getTables() method. Table data can be accessed by iterating through rows and cells. The process for extracting tables is detailed below:
- Create a Document object.
- Load a Word document using the Document.loadFromFile() method.
- Access the sections in the document using the Document.getSections() method and iterate through them.
- Access the tables in each section using the Section.getTables() method and iterate through them.
- Access the rows in each table using the Table.getRows() method and iterate through them.
- Access the cells in each row using the TableRow.getCells() method and iterate through them.
- Retrieve text from each cell by iterating through its paragraphs using the TableCell.getParagraphs() and Paragraph.getText() methods.
- Add the extracted table data to a StringBuilder object.
- Write the StringBuilder object to a text file or use it as needed.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractWordTable {
public static void main(String[] args) {
// Create a Document object
Document doc = new Document();
try {
// Load a Word document
doc.loadFromFile("Sample.docx");
// Iterate the sections in the document
for (int i = 0; i < doc.getSections().getCount(); i++) {
// Get a section
Section section = doc.getSections().get(i);
// Iterate the tables in the section
for (int j = 0; j < section.getTables().getCount(); j++) {
// Get a table
Table table = section.getTables().get(j);
// Collect all table content
StringBuilder tableText = new StringBuilder();
for (int k = 0; k < table.getRows().getCount(); k++) {
// Get a row
TableRow row = table.getRows().get(k);
// Iterate the cells in the row
StringBuilder rowText = new StringBuilder();
for (int l = 0; l < row.getCells().getCount(); l++) {
// Get a cell
TableCell cell = row.getCells().get(l);
// Iterate the paragraphs to get the text in the cell
String cellText = "";
for (int m = 0; m < cell.getParagraphs().getCount(); m++) {
Paragraph paragraph = cell.getParagraphs().get(m);
cellText += paragraph.getText() + " ";
}
if (l < row.getCells().getCount() - 1) {
rowText.append(cellText).append("\t");
} else {
rowText.append(cellText).append("\n");
}
}
tableText.append(rowText);
}
// Write the table text to a file using try-with-resources
try (FileWriter writer = new FileWriter("output/Tables/Section-" + (i + 1) + "-Table-" + (j + 1) + ".txt")) {
writer.write(tableText.toString());
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
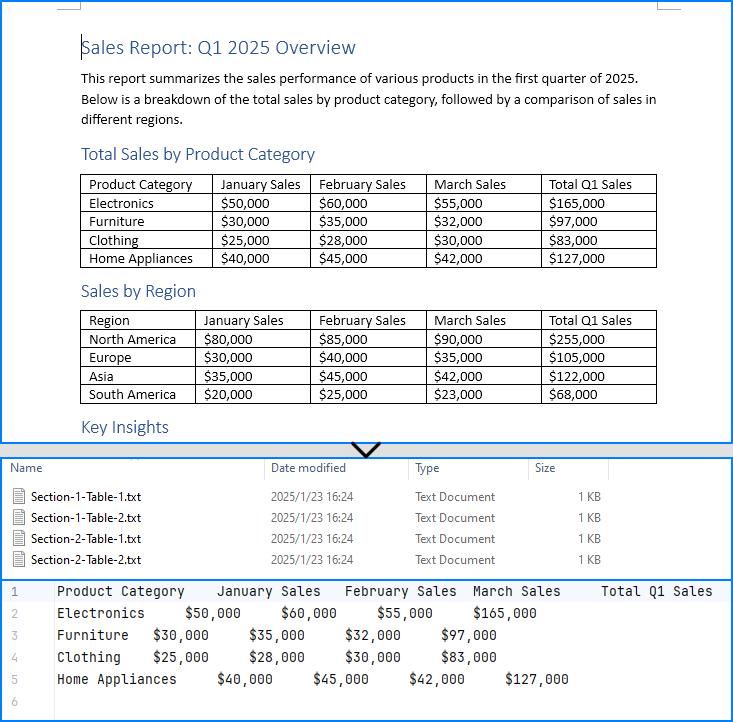
Extract Tables from Word Documents to Excel Worksheets
Developers can use Spire.Doc for Java with Spire.XLS for Java to extract table data from Word documents and write it to Excel worksheets. To get started, download Spire.XLS for Java or add the following Maven configuration:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>15.4.0</version>
</dependency>
</dependencies>
The detailed steps for extracting tables from Word documents to Excel workbooks are as follows:
- Create a Document object.
- Create a Workbook object and remove the default worksheets using the Workbook.getWorksheets().clear() method.
- Load a Word document using the Document.loadFromFile() method.
- Access the sections in the document using the Document.getSections() method and iterate through them.
- Access the tables in each section using the Section.getTables() method and iterate through them.
- Create a worksheet for each table using the Workbook.getWorksheets().add() method.
- Access the rows in each table using the Table.getRows() method and iterate through them.
- Access the cells in each row using the TableRow.getCells() method and iterate through them.
- Retrieve text from each cell by iterating through its paragraphs using the TableCell.getParagraphs() and Paragraph.getText() methods.
- Write the extracted cell text to the corresponding cell in the worksheet using the Worksheet.getRange().get(row, column).setValue() method.
- Format the worksheet as needed.
- Save the workbook to an Excel file using the Workbook.saveToFile() method.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import com.spire.xls.FileFormat;
import com.spire.xls.Workbook;
import com.spire.xls.Worksheet;
public class ExtractWordTableToExcel {
public static void main(String[] args) {
// Create a Document object
Document doc = new Document();
// Create a Workbook object
Workbook workbook = new Workbook();
// Remove the default worksheets
workbook.getWorksheets().clear();
try {
// Load a Word document
doc.loadFromFile("Sample.docx");
// Iterate the sections in the document
for (int i = 0; i < doc.getSections().getCount(); i++) {
// Get a section
Section section = doc.getSections().get(i);
// Iterate the tables in the section
for (int j = 0; j < section.getTables().getCount(); j++) {
// Get a table
Table table = section.getTables().get(j);
// Create a worksheet for each table
Worksheet sheet = workbook.getWorksheets().add("Section-" + (i + 1) + "-Table-" + (j + 1));
for (int k = 0; k < table.getRows().getCount(); k++) {
// Get a row
TableRow row = table.getRows().get(k);
for (int l = 0; l < row.getCells().getCount(); l++) {
// Get a cell
TableCell cell = row.getCells().get(l);
// Iterate the paragraphs to get the text in the cell
String cellText = "";
for (int m = 0; m < cell.getParagraphs().getCount(); m++) {
Paragraph paragraph = cell.getParagraphs().get(m);
if (m > 0 && m < cell.getParagraphs().getCount() - 1) {
cellText += paragraph.getText() + "\n";
}
else {
cellText += paragraph.getText();
}
// Write the cell text to the corresponding cell in the worksheet
sheet.getRange().get(k + 1, l + 1).setValue(cellText);
}
// Auto-fit columns
sheet.autoFitColumn(l + 1);
}
}
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
workbook.saveToFile("output/WordTableToExcel.xlsx", FileFormat.Version2016);
}
}

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

