목차
NuGet을 통해 설치됨
PM> Install-Package Spire.PDF
관련된 링크들
많은 재무 보고서, 연구 논문, 법률 문서 또는 송장 등이 PDF 형식으로 배포되는 경우가 많습니다. PDF 파일을 읽으면 정보 추출, 내용 분석, 텍스트 추출, 키워드 검색, 문서 분류, 데이터 마이닝 등의 데이터 처리 작업을 수행할 수 있습니다.
C#을 사용하여 PDF를 읽으면 반복 작업을 자동화하여 대규모 PDF 파일 컬렉션에서 특정 정보를 효율적으로 검색할 수 있습니다. 이는 광범위한 아카이브, 디지털 라이브러리 또는 문서 저장소를 검색해야 하는 애플리케이션에 유용합니다. 이 기사에서는 다음 예를 통해 방법을 보여줍니다 C#에서 PDF 파일을 읽습니다.
C# PDF 리더 라이브러리
Spire.PDF for .NET 라이브러리는 개발자가 PDF 읽기 기능을 응용 프로그램에 통합할 수 있는 PDF 리더 라이브러리 역할을 할 수 있습니다. .NET 애플리케이션 내에서 PDF 파일을 구문 분석, 렌더링 및 처리하기 위한 기능과 API를 제공합니다.
다음 중 하나를 수행할 수 있습니다 C# PDF 리더 다운로드 .NET 프로젝트에서 DLL 파일을 참조로 수동으로 추가하거나 NuGet을 통해 직접 설치합니다.
PM> Install-Package Spire.PDF
C#에서 PDF 페이지의 텍스트 읽기
Spire.PDF for .NET를 사용하면 PdfTextExtractor 클래스를 통해 C#에서 PDF 텍스트를 쉽게 읽을 수 있습니다. 다음은 지정된 PDF 페이지의 모든 텍스트를 읽는 단계입니다.
- PdfDocument 개체를 만듭니다./li>
- PdfDocument.LoadFromFile() 메서드를 사용하여 PDF 파일을 로드합니다.
- PdfDocument.Pages[index] 속성을 통해 특정 페이지를 가져옵니다.
- PdfTextExtractor 개체를 만듭니다.
- PdfTextExtractOptions 개체를 만들고 IsExtractAllText 속성을 true로 설정합니다.
- PdfTextExtractor.ExtractText() 메서드를 사용하여 선택한 페이지에서 텍스트를 추출합니다.
- 추출된 텍스트를 TXT 파일에 씁니다.
다음 코드 예제에서는 C#을 사용하여 지정된 페이지에서 PDF 텍스트를 읽는 방법을 보여줍니다.
- C#
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDF.txt", text);
}
}
}
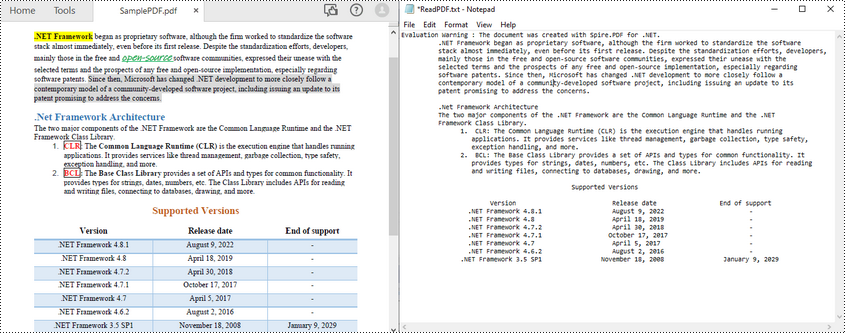
C#의 PDF 페이지 영역에서 텍스트 읽기
PDF의 지정된 페이지 영역에서 PDF 텍스트를 읽으려면 먼저 직사각형 영역을 정의한 다음 PdfTextExtractOptions 클래스의 setExtractArea() 메서드를 호출하여 여기에서 텍스트를 추출할 수 있습니다. 다음은 페이지의 직사각형 영역에서 PDF 텍스트를 추출하는 단계입니다.
- PdfDocument 개체를 만듭니다.
- PdfDocument.LoadFromFile() 메서드를 사용하여 PDF 파일을 로드합니다.
- PdfDocument.Pages[index] 속성을 통해 특정 페이지를 가져옵니다.
- PdfTextExtractor 개체를 만듭니다.
- PdfTextExtractOptions 개체를 만들고 해당 개체의 ExtractArea 속성을 통해 사각형 영역을 지정합니다.
- PdfTextExtractor.ExtractText() 메서드를 사용하여 사각형에서 텍스트를 추출합니다.
- 추출된 텍스트를 TXT 파일에 씁니다.
다음 코드 샘플은 C#을 사용하여 지정된 페이지 영역에서 PDF 텍스트를 읽는 방법을 보여줍니다.
- C#
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Specify a rectangle area
extractOptions.ExtractArea = new RectangleF(0, 180, 800, 160);
//Read PDF text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDFArea.txt", text);
}
}
}
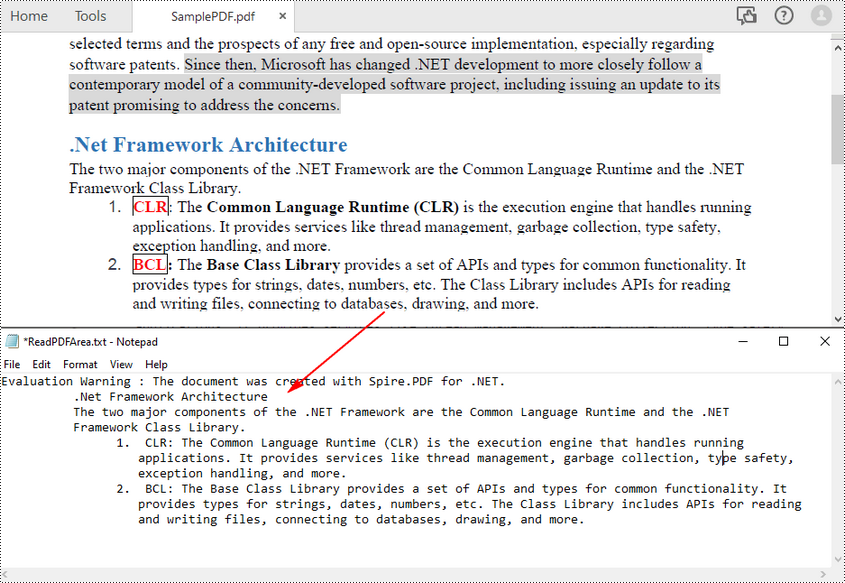
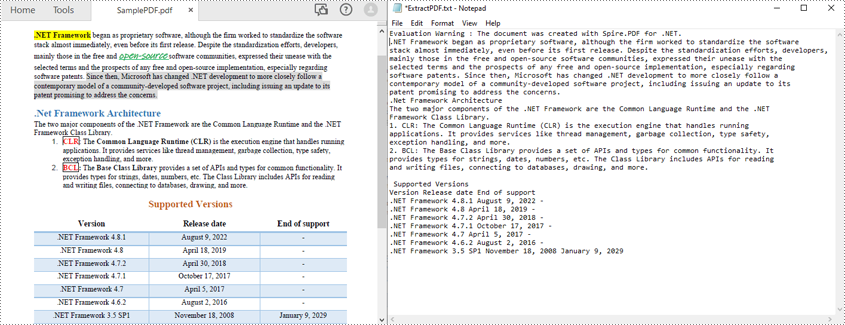
C#에서 텍스트 레이아웃을 유지하지 않고 PDF 읽기
위의 방법은 PDF 텍스트를 한 줄씩 읽습니다. SimpleExtraction 전략을 사용하면 레이아웃을 유지하지 않고도 PDF 텍스트를 간단히 읽을 수도 있습니다. 각 문자열의 현재 Y 위치를 추적하고 Y 위치가 변경된 경우 출력에 줄 바꿈을 삽입합니다. 다음은 PDF 텍스트를 간단하게 읽는 단계입니다.
- PdfDocument 개체를 만듭니다.
- PdfDocument.LoadFromFile() 메서드를 사용하여 PDF 파일을 로드합니다.
- PdfDocument.Pages[index] 속성을 통해 특정 페이지를 가져옵니다.
- PdfTextExtractor 개체를 만듭니다.
- PdfTextExtractOptions 개체를 만들고 IsSimpleExtraction 속성을 true로 설정합니다.
- PdfTextExtractor.ExtractText() 메서드를 사용하여 선택한 페이지에서 텍스트를 추출합니다.
- 추출된 텍스트를 TXT 파일에 씁니다.
다음 코드 샘플은 C#을 사용하여 텍스트 레이아웃을 유지하지 않고 PDF 텍스트를 읽는 방법을 보여줍니다.
- C#
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true to
extractOptions.IsSimpleExtraction = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ExtractPDF.txt", text);
}
}
}
C#에서 PDF의 이미지 및 테이블 추출
C#에서 PDF 텍스트를 읽는 것 외에도 Spire.PDF for .NET 라이브러리를 사용하면 PDF에서 이미지를 추출하거나 PDF 파일의 테이블 데이터만 읽을 수 있습니다. 다음 링크는 관련 공식 튜토리얼로 연결됩니다.
결론
이 기사에서는 C#에서 PDF 파일을 읽는 다양한 방법을 소개했습니다. 지정된 페이지, 지정된 직사각형 영역에서 PDF 텍스트를 읽는 방법 또는 텍스트 레이아웃을 유지하지 않고 PDF 파일을 읽는 방법에 대해 제공된 예제를 통해 배울 수 있습니다. 또한 Spire.PDF for .NET 라이브러리를 사용하여 PDF 파일의 이미지나 표를 추출할 수도 있습니다.
다음을 사용하여 .NET PDF 라이브러리의 더 많은 PDF 처리 및 변환 기능을 살펴보세요 선적 서류 비치. 테스트 중 문제가 발생한 경우 다음을 통해 기술 지원팀에 문의하시기 바랍니다 이메일 또는 포럼.
