목차
핍으로 설치
pip install Spire.PDF
관련된 링크들
PDF를 Excel로 변환하는 것은 PDF 문서에서 표 형식의 데이터를 추출하여 편집 가능하고 구조화된 스프레드시트 형식으로 변환하는 것입니다. MS Excel이 고급 데이터 처리 기능을 제공하므로 PDF 데이터 작업, 계산 수행 및 정보 분석이 훨씬 쉬워집니다.
Excel로 변환해야 할 PDF 파일이 많은 경우 프로그래밍을 통해 일괄 변환을 구현할 수 있으며, 이는 PDF를 Excel로 변환하는 과정을 자동화하여 시간과 노력을 절약하는 데 도움이 됩니다. 이 문서에서는 프로그래밍 방식으로 방법을 안내합니다 Python에서 PDF를 Excel로 변환.
Python PDF를 Excel로 변환기
PDF를 Excel로 변환하기 위해 Python을 사용하려면 Spire.PDF for Python 라이브러리가 필요합니다. 이 Python PDF 라이브러리는 개발자가 Python 프로그램에서 PDF 파일을 효율적으로 작업할 수 있는 큰 잠재력을 제공합니다. PDF 작성, 기존 PDF 파일 처리, PDF를 Word로, PDF를 이미지로, PDF를 Excel로, PDF를 HTML로 변환하는 등의 작업을 지원합니다.
PDF-Excel 변환기를 설치하려면 다음 pip 명령을 사용하여 PyPI 에서 설치하면 됩니다.
pip install Spire.PDF
Python에서 PDF를 Excel로 변환하는 방법
시작하기 전에 Spire.PDF for Python 라이브러리를 사용하여 PDF 파일을 Excel로 변환하는 핵심 클래스와 메서드를 살펴보겠습니다.
- PdfDocument 클래스: PDF 문서 모델을 나타냅니다.
- XlsxLineLayoutOptions 클래스: PDF가 Excel로 변환되는 방법을 제어하는 변환 옵션을 지정하는 데 사용됩니다. XlsxLineLayoutOptions 클래스 생성자는 다음 5개 매개 변수를 허용합니다.
- convertToMultipleSheet (bool): 각 페이지를 동일한 Excel의 다른 워크시트로 변환할지 여부를 지정합니다. False로 설정하면 PDF 파일의 모든 페이지가 단일 Excel 워크시트로 변환됩니다.
- rotatedText (bool): 회전된 텍스트를 표시할지 여부를 지정합니다.
- splitCell (bool): PDF 셀(세 줄 이상)의 텍스트를 하나의 Excel 셀로 변환할지, 아니면 여러 셀로 변환할지를 지정합니다.
- wrapText (bool): Excel 셀에서 텍스트를 줄바꿈할지 여부를 지정합니다.
- overlapText (bool): 겹치는 텍스트를 표시할지 여부를 지정합니다.
- PdfDocument.ConvertOptions.SetPdfToXlsxOptions() 메서드: 변환 옵션을 적용합니다.
- PdfDocument.SaveToFile(string filename, FileFormat.XLSX) 메서드: PDF를 Excel XLSX 형식으로 저장합니다.
다음은 Python에서 PDF를 Excel로 변환하는 방법을 보여주는 주요 단계입니다.
- 1. Spire.PDF for Python 설치합니다.
- 2. 필요한 모듈을 가져옵니다.
- 3. PdfDocument 클래스의 개체를 만듭니다.
- 4. PdfDocument.LoadFromFile() 메서드를 통해 PDF 파일을 로드합니다.
- 5. 변환 옵션을 설정해야 하는 경우 XlsxLineLayoutOptions 클래스의 개체를 만들고 해당 매개 변수를 해당 생성자에 전달합니다.
- 6. PdfDocument.ConvertOptions.SetPdfToXlsxOptions() 메서드를 통해 변환 옵션을 적용합니다.
- 7. PdfDocument.SaveToFile() 메서드를 호출하여 PDF를 Excel로 변환합니다.
Python에서 PDF를 Excel XLSX로 변환
Spire.PDF for Python를 사용하여 PDF를 Excel로 변환하는 것은 매우 쉽습니다. PDF 파일을 로드한 다음 XLSX 형식으로 저장하면 됩니다. Python에서 PDF를 Excel로 간단히 변환하려면 세 줄의 코드만 필요합니다.
- Python
from spire.pdf.common import *
from spire.pdf import *
inputFile = "Invoice.pdf"
outputFile = "PdfToExcel.xlsx"
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile(inputFile)
# Save the PDF file to Excel XLSX format
pdf.SaveToFile(outputFile, FileFormat.XLSX)
pdf.Close()
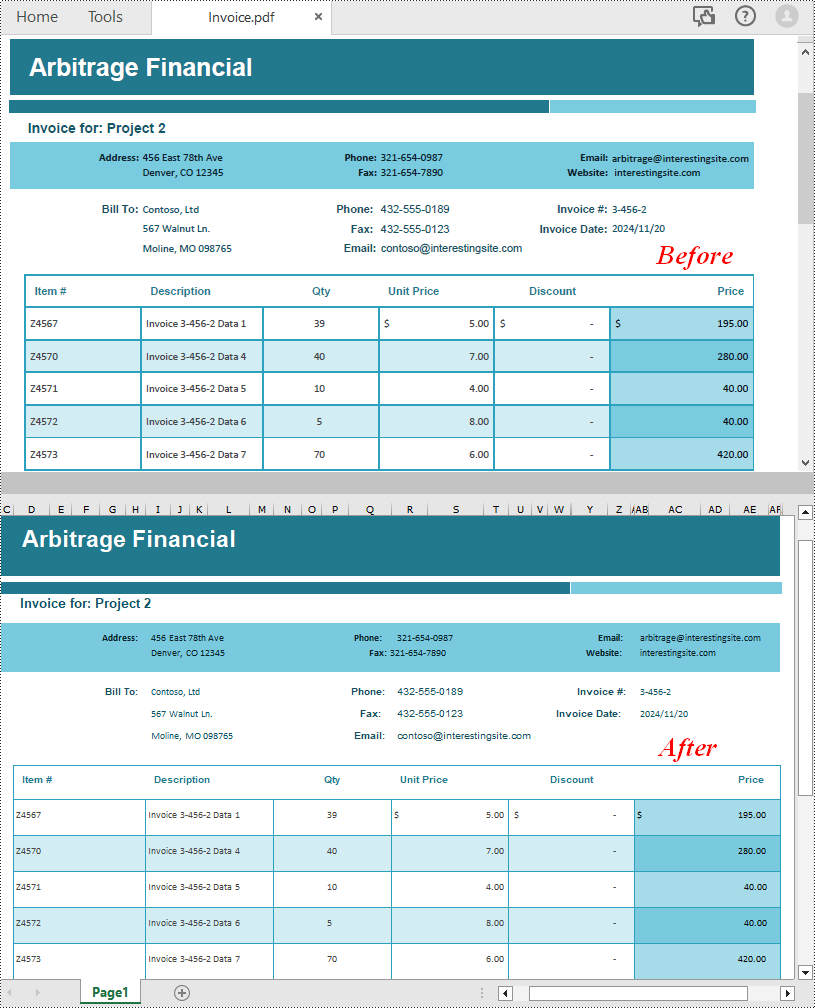
Python에서 다중 페이지 PDF를 하나의 Excel 시트로 변환
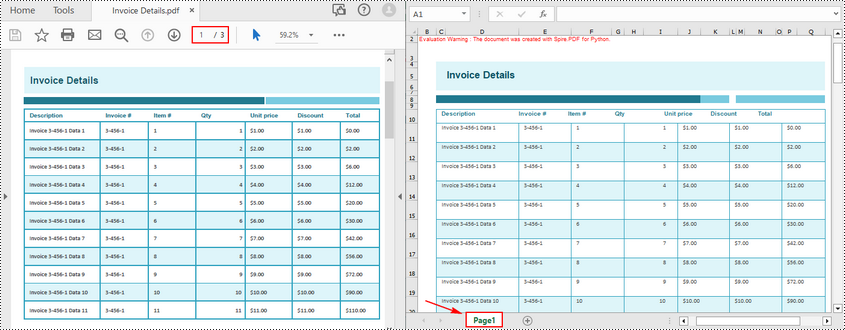
간단한 변환 방법 외에도 Spire.PDF for Python를 사용하면 PDF를 Excel로 변환하는 동안 XlsxLineLayoutOptions 클래스를 통해 변환 옵션을 사용자 정의할 수 있습니다. 위에서 소개한 것처럼 생성자의 첫 번째 매개변수인 ConvertToMultipleSheet를 False로 설정하여 여러 PDF 페이지를 하나의 Excel 시트로 변환할 수 있습니다.
- Python
from spire.pdf.common import *
from spire.pdf import *
inputFile = "Invoice Details.pdf"
outputFile = "PdfToExcelwithOptions.xlsx"
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile(inputFile)
# Create an XlsxLineLayoutOptions object to specify the conversion options
# Parameters: convertToMultipleSheet, rotatedText, splitCell, wrapText, overlapText
pdf.ConvertOptions.SetPdfToXlsxOptions(XlsxLineLayoutOptions(False, True, False, True, False))
# Save the PDF file to Excel xlsx format
pdf.SaveToFile(outputFile, FileFormat.XLSX)
pdf.Close()
PDF를 Excel로 변환하는 무료 라이센스
워터마크 및 제한 없이 PDF를 Excel로 변환하기 위해 Spire.PDF for Python를 사용하려면, 1개월 무료 임시 라이센스를 요청하세요.
결론
이 문서에서는 Python을 사용하여 PDF를 Excel로 변환하는 방법을 보여 주는 자세한 단계와 코드 예제를 제공합니다. Spire.PDF for Python의 XlsxLineLayoutOptions 클래스를 사용하여 PDF에서 Excel로의 변환 옵션을 사용자 정의하여 여러 페이지로 구성된 PDF를 하나의 Excel 워크시트로 변환, 변환된 Excel 셀에서 텍스트 줄 바꿈, 표시 등 원하는 변환 효과를 얻을 수 있습니다. /회전된 텍스트 숨기기 등
Spire.PDF for Python의 다른 PDF 처리 및 변환 기능을 자유롭게 살펴보세요 을 사용하는 도서관 선적 서류 비치. 테스트 중 문제가 있는 경우 다음을 통해 기술 지원팀에 문의하세요 이메일 이나 포럼.
