
오늘날 디지털 시대에 이미지나 스캔한 PDF에서 텍스트를 추출하는 것은 다양한 애플리케이션의 공통 요구 사항입니다. OCR(광학 문자 인식)은 컴퓨터가 이러한 문서에서 텍스트를 인식하고 추출할 수 있도록 하는 기술입니다. 이를 통해 이미지와 스캔한 PDF를 편집 및 검색 가능한 형식으로 쉽게 변환할 수 있으므로 텍스트 콘텐츠를 더 쉽게 처리하고 분석할 수 있습니다. 이번 블로그에서는 C#에서 OCR을 사용하여 이미지 및 스캔한 PDF에서 텍스트 추출.
이미지 및 스캔한 PDF에서 텍스트를 추출하기 위한 C# 라이브러리
이미지에서 텍스트를 추출하기 위해 다음을 활용하겠습니다 Spire.OCR for .NET 도서관. Spire.OCR for .NET 애플리케이션의 이미지에서 텍스트를 추출하기 위해 특별히 설계된 강력한 라이브러리입니다. BMP, JPG, PNG, TIFF, GIF 등 다양한 이미지 형식을 지원합니다.
Spire.OCR for .NET 설치하는 단계는 다음과 같습니다.
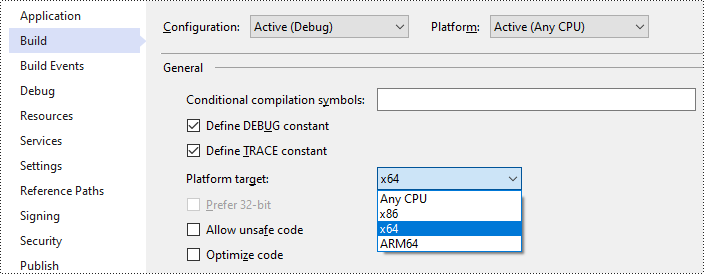
- 솔루션의 플랫폼 대상을 x64로 변경합니다.
- NuGet 패키지 관리자 콘솔에서 다음 명령을 실행하여 NuGet에서 Spire.OCR을 설치합니다.
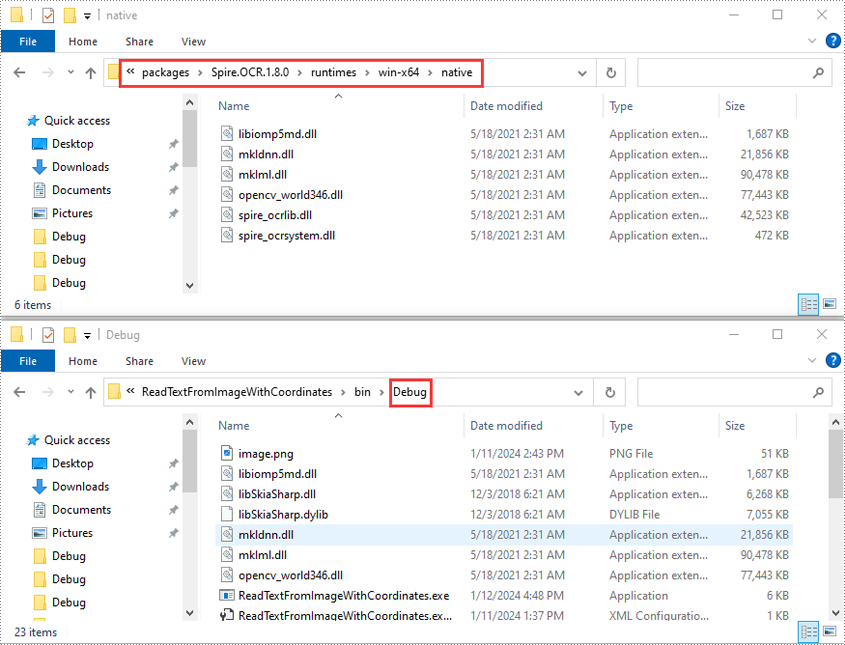
- 솔루션 폴더를 열고 "packages\Spire.OCR.1.8.0\runtimes\win-x64\native" 디렉터리로 이동합니다. 이 디렉터리에서 DLL 파일을 복사하여 솔루션의 "디버그" 폴더에 붙여넣습니다.
Install-Package Spire.OCR
스캔한 PDF에서 텍스트를 추출하려면 먼저 PDF 문서를 이미지로 변환해야 합니다. 이 작업을 위해 우리는 Spire.PDF for .NET 도서관. 변환이 완료되면 Spire.OCR을 활용하여 결과 이미지에서 텍스트를 추출할 수 있습니다.
NuGet 패키지 관리자 콘솔에서 다음 명령을 실행하여 NuGet에서 Spire.PDF for .NET를 설치할 수 있습니다.
Install-Package Spire.PDF
C#의 이미지에서 텍스트 추출
Spire.OCR은 이미지에서 텍스트를 인식하는 OcrScanner.Scan() 메서드를 제공합니다. 인식 후 OcrScanner.Text 속성을 사용하여 인식된 텍스트를 가져올 수 있습니다.
Spire.OCR을 사용하여 이미지에서 텍스트를 인식하는 주요 단계는 다음과 같습니다.
- OcrScanner 클래스의 인스턴스를 만듭니다.
- OcrScanner.Scan() 메서드를 사용하여 이미지에서 텍스트를 인식합니다.
- OcrScanner.Text 속성을 사용하여 OcrScanner 개체에서 인식된 텍스트를 가져옵니다.
- 텍스트를 텍스트 파일에 저장합니다.
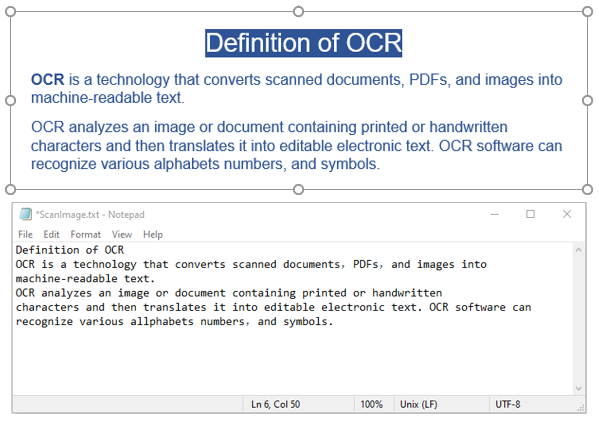
다음은 이미지에서 텍스트를 인식하고 결과를 텍스트 파일에 저장하는 방법을 보여주는 코드 예제입니다.
- C#
using Spire.OCR;
using System.IO;
namespace ReadTextFromImage
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imageFilePath = "Image.png";
//Specify the path of the output text file
string outputFilePath = "ScanImage.txt";
//Call the ScanTextFromImage method to scan text from an image
string scannedText = ScanTextFromImage(imageFilePath);
//Write the text to the specified file
File.WriteAllText(outputFilePath, scannedText);
}
public static string ScanTextFromImage(string imageFilePath)
{
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the recognized text from the OcrScanner object
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
C#에서 좌표가 있는 이미지에서 텍스트 추출
좌표 추출은 이미지에서 특정 텍스트 요소의 정확한 위치를 식별해야 할 때 유용합니다. Spire.OCR을 사용하면 인식된 텍스트를 블록이나 라인으로 검색할 수 있습니다. 각 블록에 대해 x 및 y 좌표는 물론 너비와 높이를 포함한 자세한 위치 정보를 얻을 수 있습니다.
다음은 Spire.OCR을 사용하여 이미지에서 위치 정보와 함께 텍스트를 추출하는 주요 단계입니다.
- OcrScanner 클래스의 인스턴스를 만듭니다.
- OcrScanner.Scan() 메서드를 사용하여 이미지에서 텍스트를 인식합니다.
- OcrScanner.Text 속성을 사용하여 OcrScanner 개체에서 인식된 텍스트를 가져옵니다.
- 인식된 텍스트의 텍스트 블록을 반복합니다.
- 각 블록에 대해 IOCRTextBlock.Text 및 IOCRTextBlock.Box 속성을 사용하여 해당 텍스트 및 위치 정보를 가져온 다음 결과를 문자열 목록에 추가합니다.
- 목록의 내용을 텍스트 파일로 저장합니다.
다음은 이미지의 위치 정보와 함께 텍스트를 인식하고 결과를 텍스트 파일에 저장하는 방법을 보여주는 코드 예제입니다.
- C#
using Spire.OCR;
using System.Collections.Generic;
using System.IO;
namespace ReadTextFromImageWithCoordinates
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imagePath = "Image.png";
//Specify the path of the output text file
string outputFile = "ScanImageWithCoordinates.txt";
//Call the ScanTextFromImageWithCoordinates method to extract text and its area information from the image
List<string> extractedText = ScanTextFromImageWithCoordinates(imagePath);
//Write the result to the specified file
File.WriteAllLines(outputFile, extractedText);
}
//Retrieve the text blocks along with their location information (x, y, width, height) from an image
public static List<string> ScanTextFromImageWithCoordinates(string imageFilePath)
{
//Create a list
List<string> extractedText = new List<string>();
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the scanned text
IOCRText text = ocrScanner.Text;
//Iterate through each text block
foreach (IOCRTextBlock block in text.Blocks)
{
//Append the text of each block and its location information to the list
extractedText.Add($"Text: {block.Text}\nRectangular Area: {block.Box}");
}
}
return extractedText;
}
}
}
C#으로 스캔한 PDF에서 텍스트 추출
스캔한 PDF에서 텍스트를 추출하려면 2단계 프로세스를 따라야 합니다. 먼저 Spire.PDF를 사용하여 스캔한 PDF를 이미지로 변환합니다. 그런 다음 Spire.OCR을 활용하여 해당 이미지에서 텍스트를 추출합니다.
Spire.PDF 및 Spire.OCR을 사용하여 스캔한 PDF에서 텍스트를 인식하는 주요 단계는 다음과 같습니다.
- PdfDocument 클래스의 인스턴스를 만듭니다.
- PdfDocument.LoadFromFile() 메서드를 사용하여 PDF 문서를 로드합니다.
- PDF 문서의 페이지를 반복합니다.
- PdfDocument.SaveAsImage() 메서드를 사용하여 각 페이지를 Image 개체로 변환합니다.
- Image.Save() 메서드를 사용하여 Image 객체를 스트림에 저장합니다.
- OcrScanner 클래스의 인스턴스를 만듭니다.
- OcrScanner.Scan() 메서드를 사용하여 스트림에서 텍스트를 인식합니다.
- IOCRText.Text 속성을 사용하여 인식된 텍스트를 가져와 문자열 목록에 추가합니다.
- 목록의 내용을 텍스트 파일로 저장합니다.
다음은 스캔한 PDF에서 텍스트를 인식하고 결과를 텍스트 파일에 저장하는 방법을 보여주는 코드 예제입니다.
- C#
using Spire.OCR;
using Spire.Pdf;
using System.Collections.Generic;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
namespace ReadTextFromScannedPDF
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the scanned PDF file
string pdfFilePath = "Sample.pdf";
//Specify the path of the output text file
string outputFilePath = "ScanPDF.txt";
//Extract text from the scanned PDF
List<string> extractedText = ExtractTextFromScannedPDF(pdfFilePath);
//Write the text to the specified file
File.WriteAllLines(outputFilePath, extractedText);
}
//Extract text from a scanned PDF
public static List<string> ExtractTextFromScannedPDF(string pdfFilePath)
{
//Create a list to store the extracted text
List<string> extractedText = new List<string>();
//Create an instance of the PdfDocument class
using (PdfDocument document = new PdfDocument())
{
//Load the PDF document
document.LoadFromFile(pdfFilePath);
//Iterate through each page of the document
for (int pageIndex = 0; pageIndex < document.Pages.Count; pageIndex++)
{
//Convert the page to an image
using (Image image = document.SaveAsImage(pageIndex, 300, 300))
{
//Create a memory stream to hold the image data
using (MemoryStream stream = new MemoryStream())
{
//Save the image to the memory stream in PNG format
image.Save(stream, ImageFormat.Png);
stream.Position = 0;
//Scan the text from the image and add it to the list
string text = ScanTextFromImageStream(stream);
extractedText.Add(text);
}
}
}
}
//Return the list
return extractedText;
}
//Scan text from an image stream
public static string ScanTextFromImageStream(Stream stream)
{
//Create an instance of the OcrScanner class
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan the text from the image stream in PNG format
ocrScanner.Scan(stream, OCRImageFormat.Png);
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
무료 라이센스 받기
평가 제한 없이 Spire.OCR for .NET 또는 Spire.PDF for .NET의 기능을 완전히 경험하려면 다음을 요청할 수 있습니다 30일 무료 평가판 라이센스.
결론
이 블로그 게시물에서는 C#에서 이미지와 스캔한 PDF 문서에서 텍스트를 추출하는 방법을 보여주었습니다. 질문이 있으시면 언제든지 저희 사이트에 게시해 주시기 바랍니다 법정 또는 다음을 통해 지원팀에 보내세요 이메일.
