목차
핍으로 설치
pip install Spire.Doc
관련된 링크들
웹 페이지에서 문서를 생성하는 것은 일반적인 요구 사항이 되었습니다. 웹 콘텐츠 보관, 웹 페이지 오프라인 공유, 인쇄 가능한 보고서 작성 등 사람들은 HTML 파일을 안정적이고 보편적으로 액세스할 수 있는 PDF 형식으로 변환할 수 있는 신뢰할 수 있는 방법이 필요한 경우가 많습니다. 강력한 Python 언어를 도입함으로써 우리는 원활하게 변환할 수 있습니다 Python을 사용하여 HTML을 PDF로 웹 콘텐츠에서 PDF를 쉽게 생성할 수 있는 프로그램입니다.

이 글은 활용에 초점을 맞췄습니다 HTML을 PDF로 변환하는 Python 변환, 변환의 이점, 주요 단계 및 코드 예제를 강조합니다. 여기에는 다음 주제가 포함됩니다.
- Python을 사용하여 HTML을 PDF로 변환하기 위한 팁 및 고려 사항
- HTML을 PDF로 변환하기 위한 Python API
- Python에서 HTML을 PDF로 변환하는 단계 및 코드 예제
- Python을 통해 HTML 문자열을 PDF로 렌더링하는 단계 및 코드 예제
- HTML을 PDF로 변환하기 위한 Python API 무료 라이센스
- HTML을 PDF로 변환하는 무료 온라인 변환기
Python을 사용하여 HTML을 PDF로 변환하기 위한 팁 및 고려 사항
Python 라이브러리의 도움으로 개발자와 사용자는 웹 페이지에서 이미지, 서식, 하이퍼링크를 포함하여 전문가 수준의 PDF 문서를 쉽게 생성할 수 있습니다. Python을 사용한 HTML-PDF 변환의 주요 이점은 다음과 같습니다.
- 장치 전반에 걸쳐 일관된 콘텐츠 모양: Python HTML을 PDF로 변환하면 일관된 모양의 인쇄 가능한 보고서와 문서를 생성할 수 있습니다. 이를 통해 다양한 장치와 운영 체제에서 오프라인 액세스는 물론 원활한 공유 및 인쇄가 가능해집니다.
- 효율적인 일괄 변환: Python 코드를 사용하면 HTML을 PDF 문서로 효율적으로 일괄 변환할 수 있습니다. 개발자는 변환 프로세스를 자동화하고 여러 HTML 파일을 동시에 PDF 형식으로 변환하여 시간과 노력을 절약할 수 있습니다.
이러한 장점에도 불구하고 HTML을 PDF로 변환하는 데 한계가 있다는 점을 인식하는 것이 중요합니다. 주요 과제는 다음과 같습니다.
- 동적 콘텐츠: 웹 페이지에는 정적 PDF 문서에 복제하기 어려운 대화형 요소, 애니메이션 및 실시간 업데이트가 포함되는 경우가 많습니다.
- 렌더링 차이점: 웹 렌더링의 복잡성과 PDF 형식의 제한으로 인해 원본 웹 페이지와 비교하여 PDF 모양에 차이가 있을 수 있습니다.
최상의 결과를 얻기 위해 개발자는 HTML을 PDF로 변환하기 위해 Python을 사용할 때 더 간단한 웹 페이지를 선택할 수 있습니다. 또는 변환 전 텍스트 내용만 유지하여 HTML 파일을 전처리할 수도 있습니다.
HTML을 PDF로 변환하기 위한 Python API
Spire.Doc for Python 은 다음과 같은 작업을 포함하여 효율적인 문서 처리를 위해 설계된 강력한 Python 라이브러리입니다 문서작성, 편집, 변환. Spire.Doc for Python을 사용하면 개발자는 포괄적인 클래스 및 메서드 세트를 활용하여 Python에서 HTML 파일을 PDF로 원활하게 변환할 수 있습니다. 또한 이 라이브러리는 HTML 문자열을 PDF 문서로 변환하는 기능도 제공합니다.
Python에서 HTML을 PDF로 변환하기 위한 주요 클래스 및 메서드:
| 안건 | 설명 |
| 문서 클래스 | Word 문서를 나타냅니다. |
| Document.LoadFromFile() 메서드 | DOCX, HTML 및 기타 형식의 파일을 Word 문서로 로드합니다. |
| Document.SaveToFile() 메서드 | Word 문서를 DOCX, PDF, HTML 및 기타 형식의 파일로 저장합니다. |
| Paragraph.AppendHTML() 메서드 | 문서 내에서 HTML 문자열을 렌더링합니다. |
| FileFormat 열거형 | 다양한 유형의 파일 형식을 나타내는 Enum 클래스입니다. |
| XHTMLValidationType 열거형 | 아니요, 엄격 및 전환 유효성 검사를 포함하여 XHTML 유효성 검사 옵션을 나타내는 열거형 클래스입니다. |
사용자는 다음을 수행할 수 있습니다 Spire.Doc for Python 다운로드 공식 웹사이트에 접속하거나 PyPI로 설치하세요:
- Python
Pip install Spire.Doc
Python에서 HTML을 PDF로 변환하는 단계 및 코드 예제
개발자는 HTML 파일을 로드하고 PDF 파일로 저장함으로써 Python을 사용하여 간단한 코드로 HTML을 PDF로 변환할 수 있습니다. 주요 단계는 다음과 같습니다.
- 필요한 모듈을 가져옵니다.
- Document 클래스의 객체를 생성합니다.
- Document.LoadFromFile() 메서드를 사용하여 HTML 파일을 로드합니다.
- HTML 파일을 PDF로 변환하고 Document.SaveToFile() 메서드를 사용하여 저장합니다.
다음은 Python에서 HTML을 PDF로 변환하는 코드 예제입니다.
- Python
from spire.doc import Document
from spire.doc import FileFormat
from spire.doc import XHTMLValidationType
# Create an object of Document class
doc = Document()
# Load an HTML file
doc.LoadFromFile("Sample.html", FileFormat.Html, XHTMLValidationType.none)
# Save convert the file to PDF format and save it
doc.SaveToFile("output/HTMLToPDF.pdf", FileFormat.PDF)
doc.Close()
Conversion Effect:
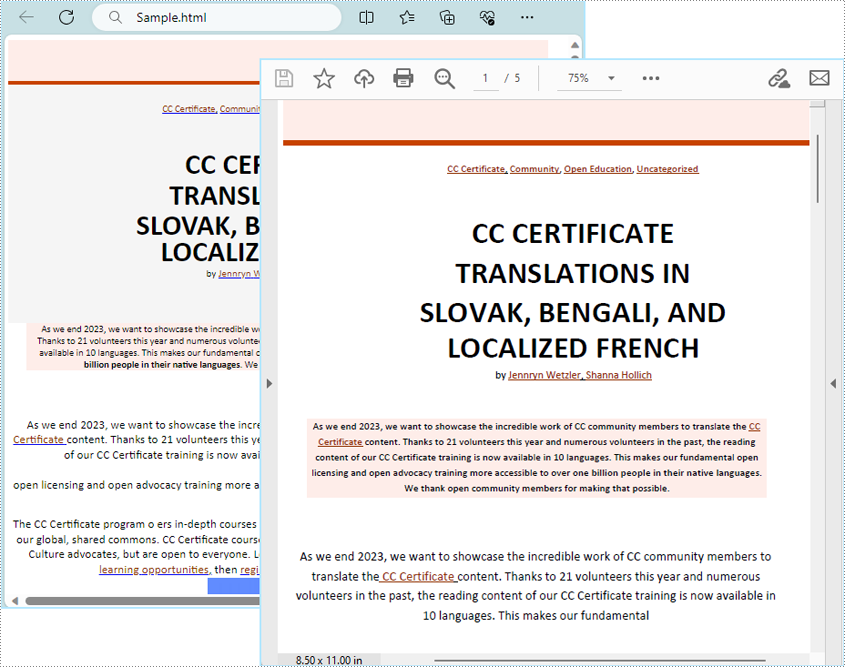
Python을 통해 HTML 문자열을 PDF로 렌더링하는 단계 및 코드 예제
HTML 문자열은 일반적으로 웹 페이지의 구조와 표현을 설명하는 HTML 태그, 속성 및 콘텐츠가 포함된 텍스트를 나타냅니다. Paragraph.AppendHTML() 메서드를 사용하면 개발자는 쉽게 문서의 HTML 문자열을 렌더링한 다음 PDF 파일로 저장할 수 있습니다. 주요 단계는 다음과 같습니다.
- 필요한 모듈을 가져옵니다.
- Document 클래스의 객체를 생성합니다.
- Document.AddSection() 메서드를 사용하여 문서에 섹션을 추가하고, Section.AddParagraph() 메서드를 사용하여 해당 섹션에 단락을 추가합니다.
- HTML 문자열을 지정합니다.
- Paragraph.AppendHTML() 메서드를 사용하여 문서의 HTML 문자열을 렌더링합니다.
- 문서를 PDF로 변환하고 Document.SaveToFile() 메서드를 사용하여 저장합니다.
Python에서 HTML 문자열을 PDF로 변환하는 코드 예제:
- Python
from spire.doc import Document
from spire.doc import FileFormat
# Create an object of Document class
doc = Document()
# Add a section to the document
sec = doc.AddSection()
# Add a paragraph to the section
par = sec.AddParagraph()
# Specify the HTML string
htmlString = """
<html>
<head>
<title>HTML Example</title>
</head>
<body>
<h1 style="color: blue;">Welcome to My Website</h1>
<h2>Personal Information</h2>
<ul>
<li>Name: John Doe</li>
<li>Age: 30</li>
<li>Nationality: United States</li>
</ul>
<h2>Work Experience</h2>
<table border="1">
<tr>
<th>Company</th>
<th>Position</th>
<th>Year</th>
</tr>
<tr>
<td>ABC Company</td>
<td>Software Engineer</td>
<td>2018-2020</td>
</tr>
<tr>
<td>XYZ Company</td>
<td>Project Manager</td>
<td>2020-2022</td>
</tr>
</table>
<h2>Project List</h2>
<ol>
<li>Project A</li>
<li>Project B</li>
<li>Project C</li>
</ol>
</body>
</html>
"""
# Render the HTML string in the document
par.AppendHTML(htmlString)
# Save the document as an PDF file
doc.SaveToFile("output/HTMLStringToPDF.pdf", FileFormat.PDF)
doc.Close()
생성된 PDF 문서:
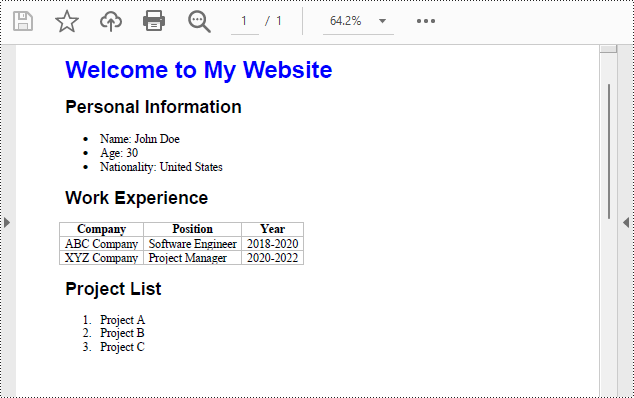
HTML을 PDF로 변환하기 위한 Python API 무료 라이센스
Spire.Doc for Python 사용자가 Python을 사용한 HTML에서 PDF로의 변환을 포함하여 문서 처리 및 변환에 대한 모든 제한을 해제할 수 있는 30일 무료 라이센스를 제공합니다. 에 의해 무료 라이센스를 신청하고, 사용자는 API가 제공하는 강력한 파일 처리 및 변환 기능을 완벽하게 활용할 수 있습니다.
HTML을 PDF로 변환하는 무료 온라인 변환기
복잡한 작업 없이 소수의 간단한 HTML 파일을 PDF 문서로 변환하려는 사용자의 경우 다음을 활용하는 것이 좋습니다 무료 온라인 PDF 변환기. 이 도구를 사용하면 HTML 파일을 업로드하고 결과 PDF 문서를 다운로드하여 쉽게 변환할 수 있습니다. 빠르고 번거롭지 않은 변환을 위한 간단한 솔루션을 제공합니다.

결론
위 기사는 HTML을 PDF로 변환하기 위한 Python에 중점을 두었습니다. 변환의 장점과 한계를 설명했습니다 Python을 사용하여 HTML을 PDF로 그리고 Spire.Doc for Python을 사용하여 HTML을 PDF로, HTML 문자열을 PDF로 변환하는 방법에 대한 지침과 코드 예제를 제공했습니다. 위의 방법을 참조하여 개발자는 자동화된 고품질 변환을 달성하기 위해 자신만의 Python 프로그램을 만들 수 있습니다. Spire.Doc for Python을 사용하는 동안 문제가 발생한 경우 다음으로 이동하세요. Spire.Doc 포럼 기술 지원을 위해.
