Sommario
Installato tramite NuGet
PM> Install-Package Spire.PDF
Link correlati
Molti rapporti finanziari, documenti di ricerca, documenti legali o fatture sono spesso distribuiti in formato PDF. La lettura di file PDF consente di estrarre informazioni, analizzare contenuti ed eseguire attività di elaborazione dati come estrazione di testo, ricerca di parole chiave, classificazione di documenti e data mining.
Utilizzando C# per leggere PDF, puoi automatizzare l'attività ripetitiva per ottenere un recupero efficiente di informazioni specifiche da un'ampia raccolta di file PDF. Ciò è utile per le applicazioni che richiedono la ricerca in archivi estesi, librerie digitali o repository di documenti. Questo articolo fornirà i seguenti esempi per mostrarti come fare leggere il file PDF in C#.
- Leggi il testo da una pagina PDF in C#
- Leggi il testo da un'area di pagina PDF in C#
- Leggi PDF senza preservare il layout del testo in C#
- Estrai immagini e tabelle in PDF in C#
Libreria di lettori PDF C#
La libreria Spire.PDF for .NET può fungere da libreria di lettori PDF che consente agli sviluppatori di integrare funzionalità di lettura PDF nelle loro applicazioni. Fornisce funzioni e API per l'analisi, il rendering e l'elaborazione di file PDF all'interno delle applicazioni .NET.
Puoi entrambi scaricare il lettore PDF C# per aggiungere manualmente i file DLL come riferimenti nel tuo progetto .NET o installarlo direttamente tramite NuGet.
PM> Install-Package Spire.PDF
Leggi il testo da una pagina PDF in C#
Spire.PDF for .NET semplifica la lettura del testo PDF in C# tramite la classe PdfTextExtractor. Di seguito sono riportati i passaggi per leggere tutto il testo da una pagina PDF specificata.
- Crea un oggetto PdfDocument.
- Carica un file PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Ottieni la pagina specifica tramite la proprietà PdfDocument.Pages[index].
- Crea un oggetto PdfTextExtractor.
- Crea un oggetto PdfTextExtractOptions e imposta la proprietà IsExtractAllText su true.
- Estrai il testo dalla pagina selezionata utilizzando il metodo PdfTextExtractor.ExtractText().
- Scrivi il testo estratto in un file TXT.
Nell'esempio di codice seguente viene illustrato come utilizzare C# per leggere il testo PDF da una pagina specificata.
- C#
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDF.txt", text);
}
}
}
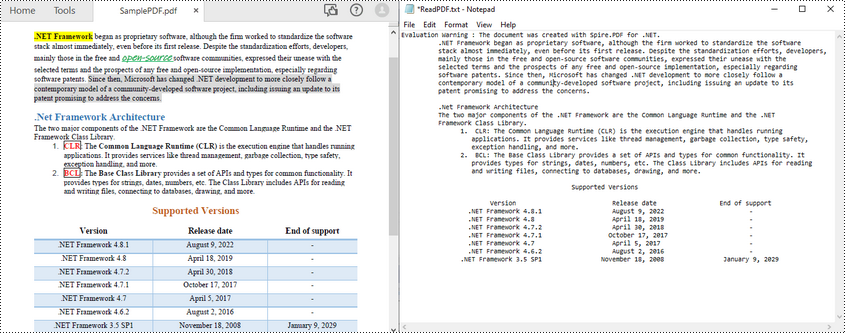
Leggi il testo da un'area di pagina PDF in C#
Per leggere il testo PDF da un'area di pagina specificata nel PDF, puoi prima definire un'area rettangolare e quindi chiamare il metodo setExtractArea() della classe PdfTextExtractOptions per estrarre il testo da essa. Di seguito sono riportati i passaggi per estrarre il testo PDF da un'area rettangolare di una pagina.
- Crea un oggetto PdfDocument.
- Carica un file PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Ottieni la pagina specifica tramite la proprietà PdfDocument.Pages[index].
- Crea un oggetto PdfTextExtractor.
- Crea un oggetto PdfTextExtractOptions e specifica l'area del rettangolo tramite la sua proprietà ExtractArea.
- Estrai il testo dal rettangolo utilizzando il metodo PdfTextExtractor.ExtractText().
- Scrivi il testo estratto in un file TXT.
L'esempio di codice seguente mostra come usare C# per leggere il testo PDF da un'area della pagina specificata.
- C#
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Specify a rectangle area
extractOptions.ExtractArea = new RectangleF(0, 180, 800, 160);
//Read PDF text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDFArea.txt", text);
}
}
}
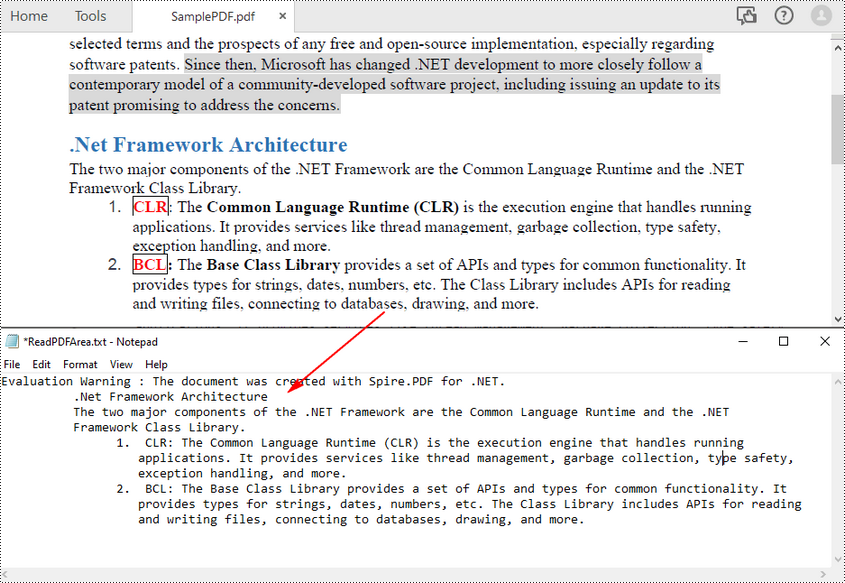
Leggi PDF senza preservare il layout del testo in C#
I metodi sopra indicati leggono il testo PDF riga per riga. Puoi anche leggere semplicemente il testo PDF senza conservarne il layout utilizzando la strategia SimpleExtraction. Tiene traccia della posizione Y corrente di ciascuna stringa e inserisce un'interruzione di riga nell'output se la posizione Y è cambiata. Di seguito sono riportati i passaggi per leggere semplicemente il testo PDF.
- Crea un oggetto PdfDocument.
- Carica un file PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Ottieni la pagina specifica tramite la proprietà PdfDocument.Pages[index].
- Crea un oggetto PdfTextExtractor.
- Crea un oggetto PdfTextExtractOptions e imposta la proprietà IsSimpleExtraction su true.
- Estrai il testo dalla pagina selezionata utilizzando il metodo PdfTextExtractor.ExtractText().
- Scrivi il testo estratto in un file TXT.
L'esempio di codice seguente mostra come usare C# per leggere il testo PDF senza preservare il layout del testo.
- C#
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true to
extractOptions.IsSimpleExtraction = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ExtractPDF.txt", text);
}
}
}
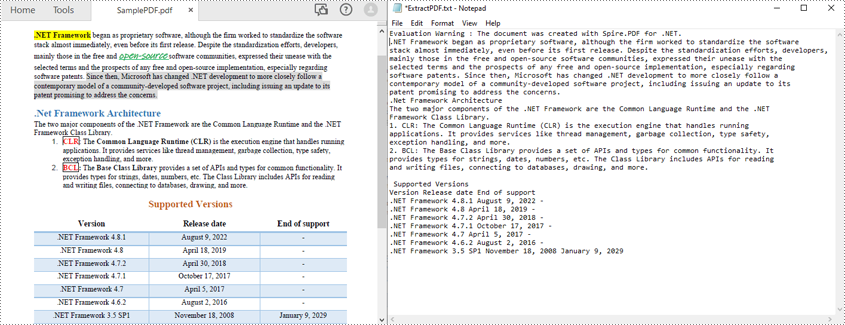
Estrai immagini e tabelle in PDF in C#
Oltre a leggere il testo PDF in C#, la libreria Spire.PDF for .NET consente anche di estrarre immagini da PDF o leggere solo i dati della tabella in un file PDF. I seguenti collegamenti ti indirizzeranno ai tutorial ufficiali pertinenti:
- Estrai immagini da PDF in C#
- Estrai i dati della tabella dal PDF in C#
- Estrai tabelle da PDF a Excel in C#
Conclusione
Questo articolo ha introdotto vari modi per leggere il file PDF in C#. Puoi imparare dagli esempi forniti su come leggere il testo PDF da una pagina specifica, da un'area rettangolare specifica o leggere file PDF senza preservare il layout del testo. Inoltre, l'estrazione di immagini o tabelle in un file PDF può essere ottenuta anche con la libreria Spire.PDF for .NET.
Esplora ulteriori funzionalità di elaborazione e conversione PDF della libreria PDF .NET utilizzando la documentazione. Se si sono verificati problemi durante il test, non esitate a contattare il team di supporto tecnico tramite e-mail o forum.
