Table des matières
Installé via NuGet
PM> Install-Package Spire.PDF
Liens connexes
De nombreux rapports financiers, documents de recherche, documents juridiques ou factures sont souvent distribués au format PDF. La lecture de fichiers PDF vous permet d'extraire des informations, d'analyser le contenu et d'effectuer des tâches de traitement de données telles que l'extraction de texte, la recherche par mot clé, la classification de documents et l'exploration de données.
En utilisant C# pour lire des PDF, vous pouvez automatiser la tâche répétitive pour réaliser une récupération efficace d'informations spécifiques à partir d'une grande collection de fichiers PDF. Ceci est utile pour les applications qui nécessitent une recherche dans de vastes archives, bibliothèques numériques ou référentiels de documents. Cet article donnera les exemples suivants pour vous montrer comment lire le fichier PDF en C#.
- Lire le texte d'une page PDF en C#
- Lire le texte d'une zone de page PDF en C#
- Lire un PDF sans conserver la mise en page du texte en C#
- Extraire des images et des tableaux au format PDF en C#
Bibliothèque de lecteurs PDF C#
La bibliothèque Spire.PDF for .NET peut servir de bibliothèque de lecture PDF permettant aux développeurs d'intégrer des capacités de lecture PDF dans leurs applications. Il fournit des fonctions et des API pour l'analyse, le rendu et le traitement des fichiers PDF dans les applications .NET.
Tu peux soit télécharger le lecteur PDF C# pour ajouter manuellement les fichiers DLL comme références dans votre projet .NET, ou installez-le directement via NuGet.
PM> Install-Package Spire.PDF
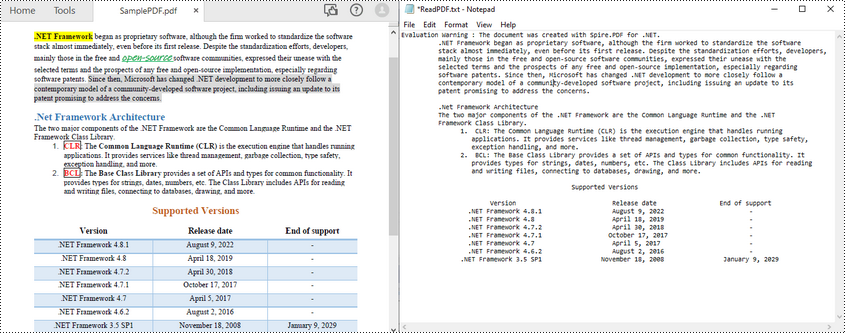
Lire le texte d'une page PDF en C#
Spire.PDF for .NET facilite la lecture du texte PDF en C# via la classe PdfTextExtractor. Voici les étapes pour lire tout le texte d’une page PDF spécifiée.
- Créez un objet PdfDocument.
- Chargez un fichier PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Obtenez la page spécifique via la propriété PdfDocument.Pages[index].
- Créez un objet PdfTextExtractor.
- Créez un objet PdfTextExtractOptions et définissez la propriété IsExtractAllText sur true.
- Extrayez le texte de la page sélectionnée à l’aide de la méthode PdfTextExtractor.ExtractText().
- Écrivez le texte extrait dans un fichier TXT.
L'exemple de code suivant montre comment utiliser C# pour lire le texte PDF à partir d'une page spécifiée.
- C#
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDF.txt", text);
}
}
}
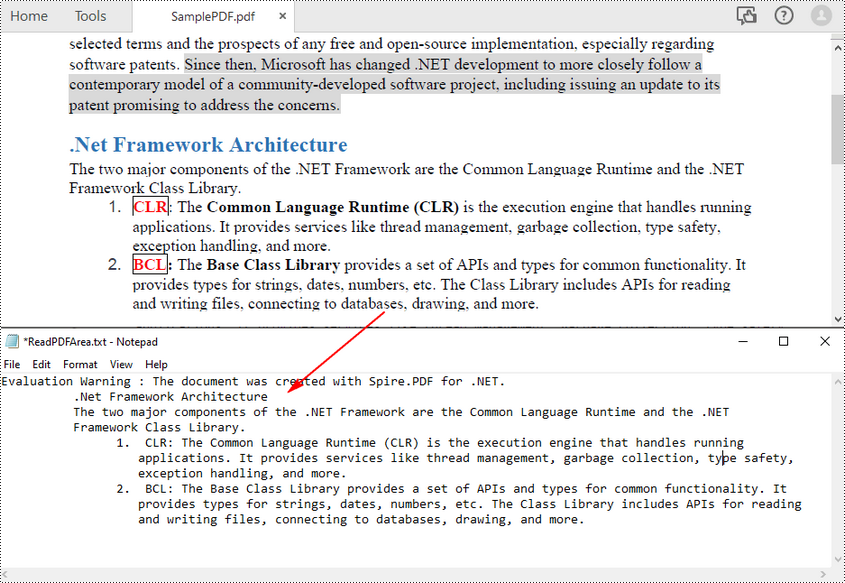
Lire le texte d'une zone de page PDF en C#
Pour lire le texte PDF d'une zone de page spécifiée dans PDF, vous pouvez d'abord définir une zone rectangulaire, puis appeler la méthode setExtractArea() de la classe PdfTextExtractOptions pour en extraire le texte. Voici les étapes pour extraire le texte PDF d’une zone rectangulaire d’une page.
- Créez un objet PdfDocument.
- Chargez un fichier PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Obtenez la page spécifique via la propriété PdfDocument.Pages[index].
- Créez un objet PdfTextExtractor.
- Créez un objet PdfTextExtractOptions et spécifiez la zone rectangulaire via sa propriété ExtractArea.
- Extrayez le texte du rectangle à l’aide de la méthode PdfTextExtractor.ExtractText().
- Écrivez le texte extrait dans un fichier TXT.
L'exemple de code suivant montre comment utiliser C# pour lire du texte PDF à partir d'une zone de page spécifiée.
- C#
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Specify a rectangle area
extractOptions.ExtractArea = new RectangleF(0, 180, 800, 160);
//Read PDF text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDFArea.txt", text);
}
}
}
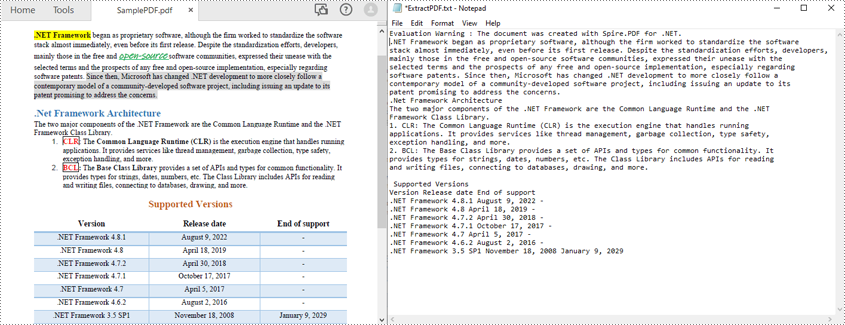
Lire un PDF sans conserver la mise en page du texte en C#
Les méthodes ci-dessus lisent le texte PDF ligne par ligne. Vous pouvez également lire du texte PDF simplement sans conserver sa mise en page grâce à la stratégie SimpleExtraction. Il garde une trace de la position Y actuelle de chaque chaîne et insère un saut de ligne dans la sortie si la position Y a changé. Voici les étapes pour lire simplement le texte PDF.
- Créez un objet PdfDocument.
- Chargez un fichier PDF à l'aide de la méthode PdfDocument.LoadFromFile().
- Obtenez la page spécifique via la propriété PdfDocument.Pages[index].
- Créez un objet PdfTextExtractor.
- Créez un objet PdfTextExtractOptions et définissez la propriété IsSimpleExtraction sur true.
- Extrayez le texte de la page sélectionnée à l’aide de la méthode PdfTextExtractor.ExtractText().
- Écrivez le texte extrait dans un fichier TXT.
L'exemple de code suivant montre comment utiliser C# pour lire du texte PDF sans conserver la disposition du texte.
- C#
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true to
extractOptions.IsSimpleExtraction = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ExtractPDF.txt", text);
}
}
}
Extraire des images et des tableaux au format PDF en C#
En plus de lire du texte PDF en C#, la bibliothèque Spire.PDF for .NET vous permet également d'extraire des images d'un PDF ou de lire uniquement les données du tableau dans un fichier PDF. Les liens suivants vous dirigeront vers les tutoriels officiels concernés :
- Extraire des images d'un PDF en C#
- Extraire les données d'un tableau d'un PDF en C#
- Extraire des tableaux de PDF vers Excel en C#
Conclusion
Cet article présente différentes manières de lire un fichier PDF en C#. Vous pouvez apprendre des exemples donnés sur la façon de lire du texte PDF à partir d'une page spécifiée, d'une zone rectangulaire spécifiée, ou de lire des fichiers PDF sans conserver la mise en page du texte. De plus, l'extraction d'images ou de tableaux dans un fichier PDF peut également être réalisée avec la bibliothèque Spire.PDF for .NET.
Découvrez davantage de fonctionnalités de traitement et de conversion PDF de la bibliothèque PDF .NET à l'aide de la documentation. Si des problèmes surviennent lors des tests, n'hésitez pas à contacter l'équipe d'assistance technique par e-mail ou sur le forum.
