Table des matières
Installer avec Pip
pip install Spire.PDF
Liens connexes
La fusion de PDF est l'intégration de plusieurs fichiers PDF en un seul fichier PDF. Il permet aux utilisateurs de combiner le contenu de plusieurs fichiers PDF associés en un seul fichier PDF pour mieux catégoriser, gérer et partager des fichiers. Par exemple, avant de partager un document, des documents similaires peuvent être fusionnés en un seul fichier pour simplifier le processus de partage. Cet article vous montrera comment utilisez Python pour fusionner des fichiers PDF avec un code simple.
- Bibliothèque Python pour fusionner des fichiers PDF
- Fusionner des fichiers PDF en Python
- Fusionner des fichiers PDF en clonant des pages en Python
- Fusionner les pages sélectionnées de fichiers PDF en Python
Bibliothèque Python pour fusionner des fichiers PDF
Spire.PDF for Python est une puissante bibliothèque Python permettant de créer et de manipuler des fichiers PDF. Avec lui, vous pouvez également utiliser Python pour fusionner des fichiers PDF sans effort. Avant cela, nous devons installer Spire.PDF for Python et plum-dispatch v1.7.4, qui peut être facilement installé dans VS Code à l'aide des commandes pip suivantes.
pip install Spire.PDF
Cet article couvre plus de détails sur l'installation: Comment installer Spire.PDF for Python dans VS Code
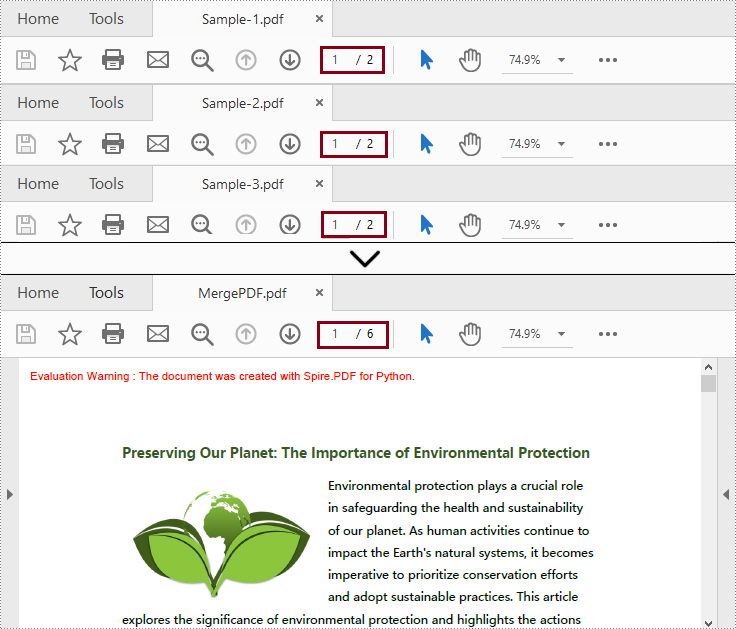
Fusionner des fichiers PDF en Python
Cette méthode prend en charge la fusion directe de plusieurs fichiers PDF en un seul fichier.
Pas
- Importez les modules de bibliothèque requis.
- Créez une liste contenant les chemins des fichiers PDF à fusionner.
- Utilisez la méthode Document.MergeFiles(inputFiles: List[str]) pour fusionner ces PDF en un seul PDF.
- Appelez la méthode PdfDocumentBase.Save(filename: str, FileFormat.PDF) pour enregistrer le fichier fusionné au format PDF dans le chemin de sortie spécifié et libérer les ressources.
Exemple de code
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a list of the PDF file paths
inputFile1 = "C:/Users/Administrator/Desktop/PDFs/Sample-1.pdf"
inputFile2 = "C:/Users/Administrator/Desktop/PDFs/Sample-2.pdf"
inputFile3 = "C:/Users/Administrator/Desktop/PDFs/Sample-3.pdf"
files = [inputFile1, inputFile2, inputFile3]
# Merge the PDF documents
pdf = PdfDocument.MergeFiles(files)
# Save the result document
pdf.Save("C:/Users/Administrator/Desktop/MergePDF.pdf", FileFormat.PDF)
pdf.Close()
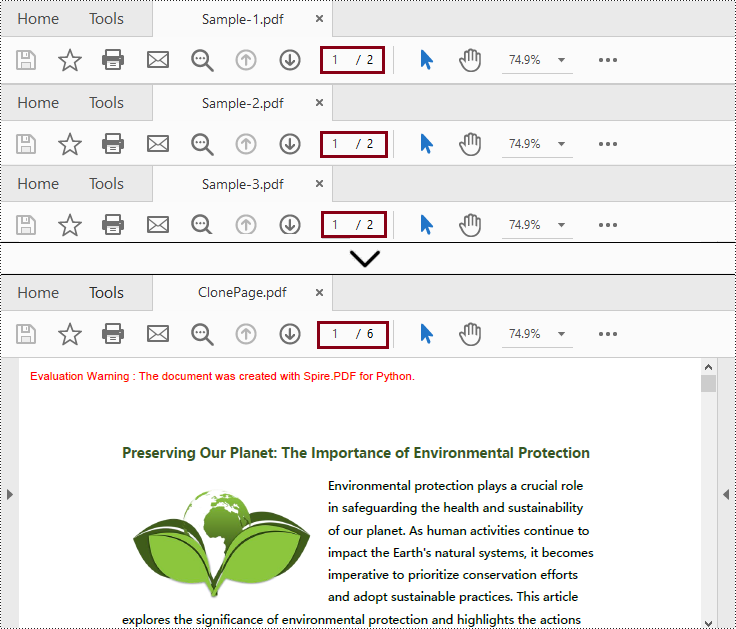
Fusionner des fichiers PDF en clonant des pages en Python
Contrairement à la méthode ci-dessus, cette méthode fusionne plusieurs fichiers PDF en copiant les pages du document et en les insérant dans un nouveau fichier.
Pas
- Importez les modules de bibliothèque requis.
- Créez une liste contenant les chemins des fichiers PDF à fusionner.
- Parcourez chaque fichier de la liste et chargez-le en tant qu'objet PdfDocument ; puis ajoutez-les à une nouvelle liste.
- Créez un nouvel objet PdfDocument comme fichier de destination.
- Parcourez les objets PdfDocument dans la liste et ajoutez leurs pages au nouvel objet PdfDocument.
- Enfin, appelez la méthode PdfDocument.SaveToFile() pour enregistrer le nouvel objet PdfDocument dans le chemin de sortie spécifié.
Exemple de code
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a list of the PDF file paths
file1 = "C:/Users/Administrator/Desktop/PDFs/Sample-1.pdf"
file2 = "C:/Users/Administrator/Desktop/PDFs/Sample-2.pdf"
file3 = "C:/Users/Administrator/Desktop/PDFs/Sample-3.pdf"
files = [file1, file2, file3]
# Load each PDF file as an PdfDocument object and add them to a list
pdfs = []
for file in files:
pdfs.append(PdfDocument(file))
# Create an object of PdfDocument class
newPdf = PdfDocument()
# Insert the pages of the loaded PDF documents into the new PDF document
for pdf in pdfs:
newPdf.AppendPage(pdf)
# Save the new PDF document
newPdf.SaveToFile("C:/Users/Administrator/Desktop/ClonePage.pdf")
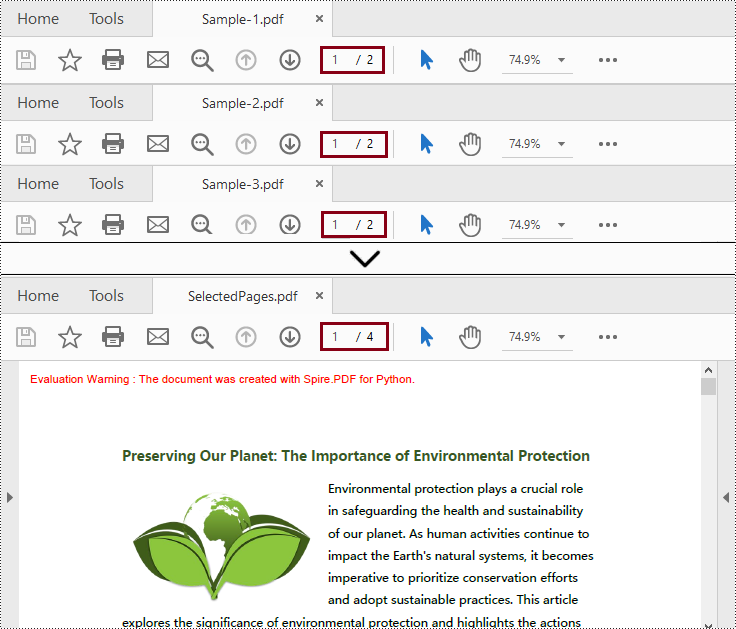
Fusionner les pages sélectionnées de fichiers PDF en Python
Cette méthode est similaire à la fusion de PDF par clonage de pages, et vous pouvez spécifier les pages souhaitées lors de la fusion.
Pas
- Importez les modules de bibliothèque requis.
- Créez une liste contenant les chemins des fichiers PDF à fusionner.
- Parcourez chaque fichier de la liste et chargez-le en tant qu'objet PdfDocument ; puis ajoutez-les à une nouvelle liste.
- Créez un nouvel objet PdfDocument comme fichier de destination.
- Insérez les pages sélectionnées à partir des fichiers chargés dans le nouvel objet PdfDocument à l'aide de la méthode PdfDocument.InsertPage(PdfDocument, pageIndex: int) ou PdfDocument.InsertPageRange(PdfDocument, startIndex: int, endIndex: int).
- Enfin, appelez la méthode PdfDocument.SaveToFile() pour enregistrer le nouvel objet PdfDocument dans le chemin de sortie spécifié.
Exemple de code
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create a list of the PDF file paths
file1 = "C:/Users/Administrator/Desktop/PDFs/Sample-1.pdf"
file2 = "C:/Users/Administrator/Desktop/PDFs/Sample-2.pdf"
file3 = "C:/Users/Administrator/Desktop/PDFs/Sample-3.pdf"
files = [file1, file2, file3]
# Load each PDF file as an PdfDocument object and add them to a list
pdfs = []
for file in files:
pdfs.append(PdfDocument(file))
# Create an object of PdfDocument class
newPdf = PdfDocument()
# Insert the selected pages from the loaded PDF documents into the new document
newPdf.InsertPage(pdfs[0], 0)
newPdf.InsertPage(pdfs[1], 1)
newPdf.InsertPageRange(pdfs[2], 0, 1)
# Save the new PDF document
newPdf.SaveToFile("C:/Users/Administrator/Desktop/SelectedPages.pdf")
Obtenez une licence gratuite pour la bibliothèque pour fusionner des PDF en Python
Vous pouvez obtenir un licence temporaire gratuite de 30 jours de Spire.PDF for Python pour fusionner des fichiers PDF en Python sans limitations d'évaluation.
Conclusion
Dans cet article, vous avez appris à fusionner des fichiers PDF en Python. Spire.PDF for Python propose deux manières différentes de fusionner plusieurs fichiers PDF, notamment la fusion directe de fichiers et la copie de pages. En outre, vous pouvez fusionner les pages sélectionnées de plusieurs fichiers PDF en fonction de la deuxième méthode. En un mot, cette bibliothèque simplifie le processus et permet aux développeurs de se concentrer sur la création d'applications puissantes impliquant des tâches de manipulation de PDF.
