Tabla de contenido
Instalado a través de NuGet
PM> Install-Package Spire.PDF
enlaces relacionados
Muchos informes financieros, trabajos de investigación, documentos legales o facturas suelen distribuirse en formato PDF. La lectura de archivos PDF le permite extraer información, analizar contenido y realizar tareas de procesamiento de datos, como extracción de texto, búsqueda de palabras clave, clasificación de documentos y extracción de datos.
Al utilizar C# para leer PDF, puede automatizar la tarea repetitiva para lograr una recuperación eficiente de información específica de una gran colección de archivos PDF. Esto es valioso para aplicaciones que requieren búsquedas en archivos extensos, bibliotecas digitales o repositorios de documentos. Este artículo le dará los siguientes ejemplos para mostrarle cómo leer el archivo PDF en C#.
- Leer texto de una página PDF en C#
- Leer texto de un área de página PDF en C#
- Leer PDF sin conservar el diseño del texto en C#
- Extraer imágenes y tablas en PDF en C#
Biblioteca de lectores de PDF de C#
La biblioteca Spire.PDF for .NET puede servir como una biblioteca de lectura de PDF que permite a los desarrolladores integrar capacidades de lectura de PDF en sus aplicaciones. Proporciona funciones y API para analizar, representar y procesar archivos PDF dentro de aplicaciones .NET.
Tu también puedes descargar el lector de PDF de C# para agregar manualmente los archivos DLL como referencias en su proyecto .NET, o instalarlo directamente a través de NuGet.
PM> Install-Package Spire.PDF
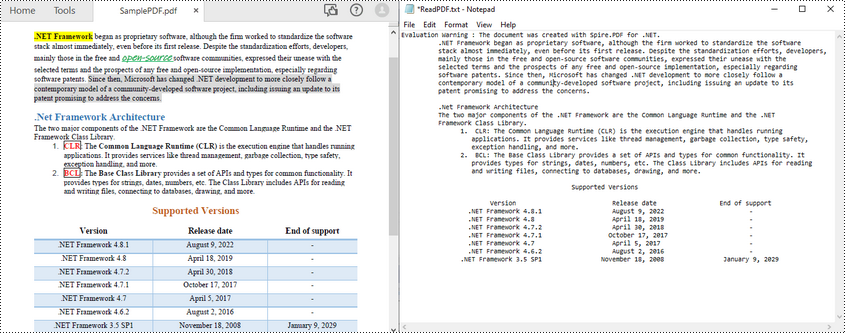
Leer texto de una página PDF en C#
Spire.PDF for .NET facilita la lectura de texto PDF en C# a través de la clase PdfTextExtractor. Los siguientes son los pasos para leer todo el texto de una página PDF específica.
- Cree un objeto PdfDocument.
- Cargue un archivo PDF utilizando el método PdfDocument.LoadFromFile().
- Obtenga la página específica a través de la propiedad PdfDocument.Pages[index].
- Cree un objeto PdfTextExtractor.
- Cree un objeto PdfTextExtractOptions y establezca la propiedad IsExtractAllText en verdadero.
- Extraiga texto de la página seleccionada utilizando el método PdfTextExtractor.ExtractText().
- Escriba el texto extraído en un archivo TXT.
El siguiente ejemplo de código muestra cómo usar C# para leer texto PDF desde una página específica.
- C#
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDF.txt", text);
}
}
}
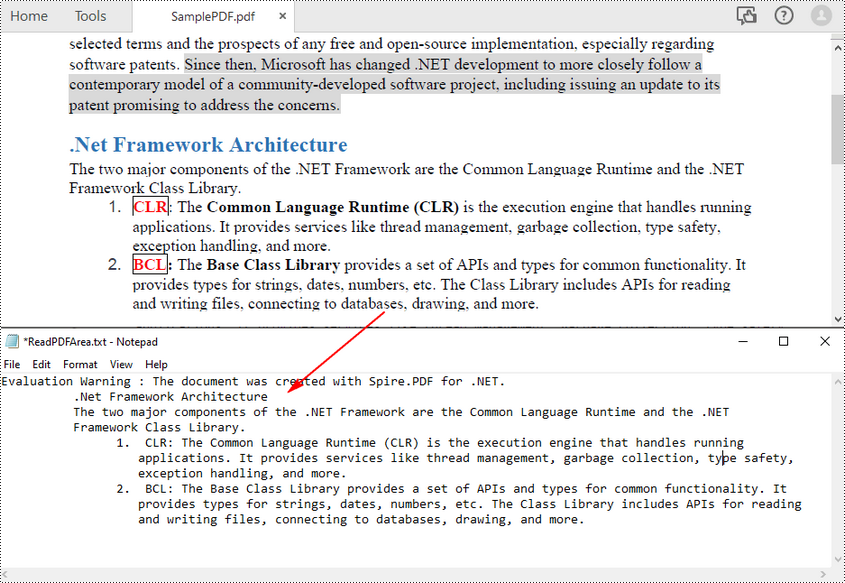
Leer texto de un área de página PDF en C#
Para leer texto PDF desde un área de página específica en PDF, primero puede definir un área rectangular y luego llamar al método setExtractArea() de la clase PdfTextExtractOptions para extraer texto de ella. Los siguientes son los pasos para extraer texto PDF de un área rectangular de una página.
- Cree un objeto PdfDocument.
- Cargue un archivo PDF utilizando el método PdfDocument.LoadFromFile().
- Obtenga la página específica a través de la propiedad PdfDocument.Pages[index].
- Cree un objeto PdfTextExtractor.
- Cree un objeto PdfTextExtractOptions y especifique el área del rectángulo a través de la propiedad ExtractArea del mismo.
- Extraiga texto del rectángulo utilizando el método PdfTextExtractor.ExtractText().
- Escriba el texto extraído en un archivo TXT.
El siguiente ejemplo de código muestra cómo usar C# para leer texto PDF desde un área de página específica.
- C#
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Specify a rectangle area
extractOptions.ExtractArea = new RectangleF(0, 180, 800, 160);
//Read PDF text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDFArea.txt", text);
}
}
}
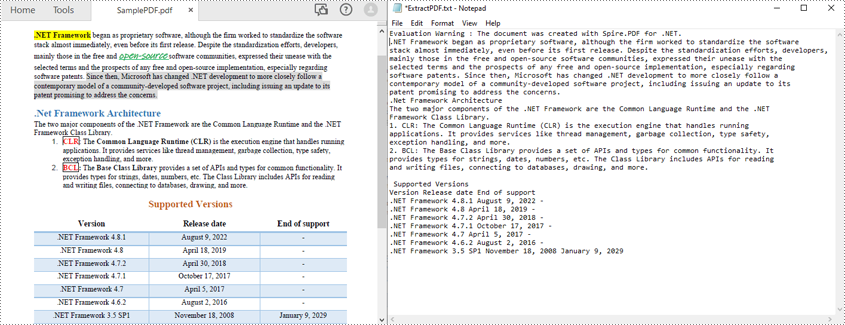
Leer PDF sin conservar el diseño del texto en C#
Los métodos anteriores leen el texto PDF línea por línea. También puede leer texto PDF simplemente sin conservar su diseño utilizando la estrategia SimpleExtraction. Realiza un seguimiento de la posición Y actual de cada cadena e inserta un salto de línea en la salida si la posición Y ha cambiado. Los siguientes son los pasos para leer texto PDF de forma sencilla
- Cree un objeto PdfDocument.
- Cargue un archivo PDF utilizando el método PdfDocument.LoadFromFile().
- Obtenga la página específica a través de la propiedad PdfDocument.Pages[index].
- Cree un objeto PdfTextExtractor.
- Cree un objeto PdfTextExtractOptions y establezca la propiedad IsSimpleExtraction en verdadero.
- Extraiga texto de la página seleccionada utilizando el método PdfTextExtractor.ExtractText().
- Escriba el texto extraído en un archivo TXT.
El siguiente ejemplo de código muestra cómo usar C# para leer texto PDF sin conservar el diseño del texto.
- C#
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true to
extractOptions.IsSimpleExtraction = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ExtractPDF.txt", text);
}
}
}
Extraer imágenes y tablas en PDF en C#
Además de leer texto PDF en C#, la biblioteca Spire.PDF for .NET también le permite extraer imágenes de PDF o leer solo los datos de la tabla en un archivo PDF. Los siguientes enlaces lo dirigirán a los tutoriales oficiales relevantes:
- Extraer imágenes de PDF en C#
- Extraer datos de tabla de PDF en C#
- Extraiga tablas de PDF a Excel en C#
Conclusión
Este artículo presentó varias formas de leer archivos PDF en C#. Puede aprender de los ejemplos proporcionados sobre cómo leer texto PDF desde una página específica, desde un área rectangular específica o leer archivos PDF sin conservar el diseño del texto. Además, también se puede extraer imágenes o tablas en un archivo PDF con la biblioteca Spire.PDF for .NET .
Explore más capacidades de conversión y procesamiento de PDF de la biblioteca .NET PDF utilizando la documentación. Si ocurrió algún problema durante la prueba, no dude en comunicarse con el equipo de soporte técnico por correo electrónico o foro.
