Tabla de contenido
Instalar con Pip
pip install Spire.PDF
enlaces relacionados
Fusionar PDF es la integración de varios archivos PDF en un solo archivo PDF. Permite a los usuarios combinar el contenido de varios archivos PDF relacionados en un solo archivo PDF para categorizar, administrar y compartir mejor los archivos. Por ejemplo, antes de compartir un documento, se pueden combinar documentos similares en un solo archivo para simplificar el proceso de compartir. Esta publicación le mostrará cómo use Python para fusionar archivos PDF con código simple.
- Biblioteca Python para fusionar archivos PDF
- Fusionar archivos PDF en Python
- Fusionar archivos PDF clonando páginas en Python
- Fusionar páginas seleccionadas de archivos PDF en Python
Biblioteca Python para fusionar archivos PDF
Spire.PDF for Python es una poderosa biblioteca de Python para crear y manipular archivos PDF. Con él, también puedes usar Python para fusionar archivos PDF sin esfuerzo. Antes de eso, necesitamos instalar Spire.PDF for Python y plum-dispatch v1.7.4, que se puede instalar fácilmente en VS Code usando los siguientes comandos pip.
pip install Spire.PDF
Este artículo cubre más detalles de la instalación: Cómo instalar Spire.PDF for Python en VS Code
Fusionar archivos PDF en Python
Este método admite la combinación directa de varios archivos PDF en un solo archivo.
Pasos
- Importe los módulos de biblioteca necesarios.
- Cree una lista que contenga las rutas de los archivos PDF que se fusionarán.
- Utilice el método Document.MergeFiles(inputFiles: List[str]) para fusionar estos archivos PDF en un solo PDF.
- Llame al método PdfDocumentBase.Save(filename: str, FileFormat.PDF) para guardar el archivo combinado en formato PDF en la ruta de salida especificada y liberar recursos.
Código de muestra
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a list of the PDF file paths
inputFile1 = "C:/Users/Administrator/Desktop/PDFs/Sample-1.pdf"
inputFile2 = "C:/Users/Administrator/Desktop/PDFs/Sample-2.pdf"
inputFile3 = "C:/Users/Administrator/Desktop/PDFs/Sample-3.pdf"
files = [inputFile1, inputFile2, inputFile3]
# Merge the PDF documents
pdf = PdfDocument.MergeFiles(files)
# Save the result document
pdf.Save("C:/Users/Administrator/Desktop/MergePDF.pdf", FileFormat.PDF)
pdf.Close()
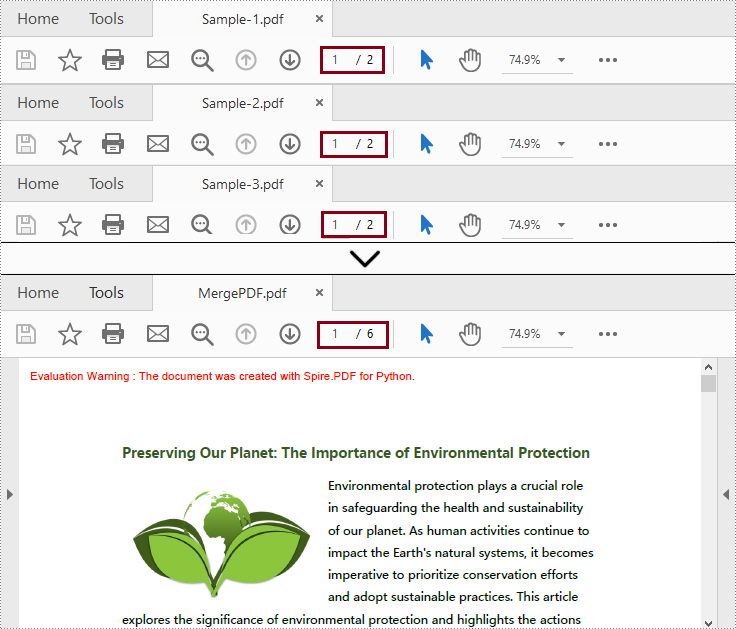
Fusionar archivos PDF clonando páginas en Python
A diferencia del método anterior, este método combina varios archivos PDF copiando páginas del documento e insertándolas en un archivo nuevo.
Pasos
- Importe los módulos de biblioteca necesarios.
- Cree una lista que contenga las rutas de los archivos PDF que se fusionarán.
- Recorra cada archivo de la lista y cárguelo como un objeto PdfDocument; luego agréguelos a una nueva lista.
- Cree un nuevo objeto PdfDocument como archivo de destino.
- Itere a través de los objetos PdfDocument en la lista y agregue sus páginas al nuevo objeto PdfDocument.
- Finalmente, llame al método PdfDocument.SaveToFile() para guardar el nuevo objeto PdfDocument en la ruta de salida especificada.
Código de muestra
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a list of the PDF file paths
file1 = "C:/Users/Administrator/Desktop/PDFs/Sample-1.pdf"
file2 = "C:/Users/Administrator/Desktop/PDFs/Sample-2.pdf"
file3 = "C:/Users/Administrator/Desktop/PDFs/Sample-3.pdf"
files = [file1, file2, file3]
# Load each PDF file as an PdfDocument object and add them to a list
pdfs = []
for file in files:
pdfs.append(PdfDocument(file))
# Create an object of PdfDocument class
newPdf = PdfDocument()
# Insert the pages of the loaded PDF documents into the new PDF document
for pdf in pdfs:
newPdf.AppendPage(pdf)
# Save the new PDF document
newPdf.SaveToFile("C:/Users/Administrator/Desktop/ClonePage.pdf")
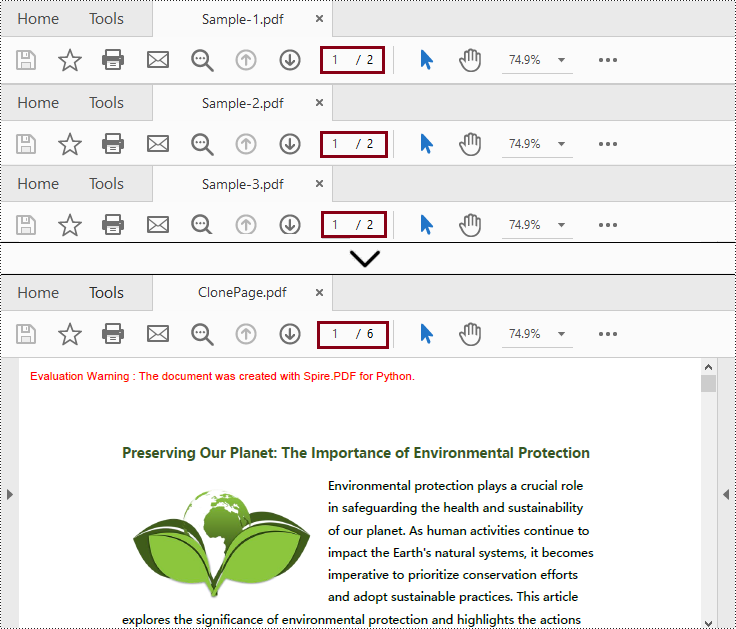
Fusionar páginas seleccionadas de archivos PDF en Python
Este método es similar a fusionar archivos PDF mediante la clonación de páginas y puede especificar las páginas deseadas al fusionar.
Pasos
- Importe los módulos de biblioteca necesarios.
- Cree una lista que contenga las rutas de los archivos PDF que se fusionarán.
- Recorra cada archivo de la lista y cárguelo como un objeto PdfDocument; luego agréguelos a una nueva lista.
- Cree un nuevo objeto PdfDocument como archivo de destino.
- Inserte las páginas seleccionadas de los archivos cargados en el nuevo objeto PdfDocument utilizando el método PdfDocument.InsertPage(PdfDocument, pageIndex: int) o el método PdfDocument.InsertPageRange(PdfDocument, startIndex: int, endIndex: int).
- Finalmente, llame al método PdfDocument.SaveToFile() para guardar el nuevo objeto PdfDocument en la ruta de salida especificada.
Código de muestra
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create a list of the PDF file paths
file1 = "C:/Users/Administrator/Desktop/PDFs/Sample-1.pdf"
file2 = "C:/Users/Administrator/Desktop/PDFs/Sample-2.pdf"
file3 = "C:/Users/Administrator/Desktop/PDFs/Sample-3.pdf"
files = [file1, file2, file3]
# Load each PDF file as an PdfDocument object and add them to a list
pdfs = []
for file in files:
pdfs.append(PdfDocument(file))
# Create an object of PdfDocument class
newPdf = PdfDocument()
# Insert the selected pages from the loaded PDF documents into the new document
newPdf.InsertPage(pdfs[0], 0)
newPdf.InsertPage(pdfs[1], 1)
newPdf.InsertPageRange(pdfs[2], 0, 1)
# Save the new PDF document
newPdf.SaveToFile("C:/Users/Administrator/Desktop/SelectedPages.pdf")
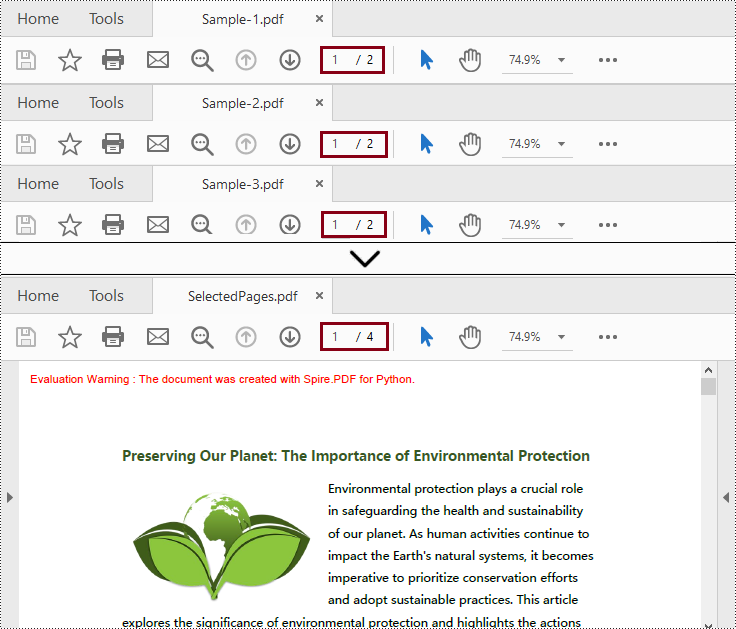
Obtenga una licencia gratuita para que la biblioteca combine PDF en Python
Puedes conseguir un licencia temporal gratuita de 30 días de Spire.PDF for Python para fusionar archivos PDF en Python sin limitaciones de evaluación.
Conclusión
En este artículo, has aprendido cómo fusionar archivos PDF en Python. Spire.PDF for Python proporciona dos formas diferentes de fusionar varios archivos PDF, incluida la fusión de archivos directamente y la copia de páginas. Además, puede fusionar páginas seleccionadas de varios archivos PDF según el segundo método. En una palabra, esta biblioteca simplifica el proceso y permite a los desarrolladores centrarse en crear aplicaciones potentes que impliquen tareas de manipulación de PDF.
