Tabla de contenido
Instalar con Pip
pip install Spire.PDF
enlaces relacionados
Convertir PDF a Excel consiste en extraer datos tabulares de un documento PDF y convertirlos a un formato de hoja de cálculo estructurado y editable. Esto hace que sea mucho más fácil trabajar con datos PDF, realizar cálculos y analizar información, ya que MS Excel proporciona funciones avanzadas de procesamiento de datos.
Cuando hay una gran cantidad de archivos PDF que deben convertirse a Excel, puede implementar la conversión por lotes a través de la programación, lo que ayuda a automatizar el proceso de conversión de PDF a Excel, ahorrando así tiempo y esfuerzo. Este artículo le guiará sobre cómo programar convertir PDF a Excel en Python.
- Cómo convertir PDF a Excel en Python
- Convertir PDF a Excel XLSX en Python
- Convierta un PDF de varias páginas en una hoja de Excel en Python
Convertidor de PDF a Excel de Python
Para usar Python para la conversión de PDF a Excel, necesitaremos la biblioteca Spire.PDF for Python. Esta biblioteca PDF de Python ofrece un gran potencial para que los desarrolladores trabajen con archivos PDF en programas Python de manera eficiente. Admite la creación de archivos PDF, el procesamiento de archivos PDF existentes y la conversión de PDF a Word, PDF a imágenes, PDF a Excel, PDF a HTML y más.
Para instalar el convertidor de PDF a Excel, simplemente use el siguiente comando pip para instalar desde PyPI:
pip install Spire.PDF
Cómo convertir PDF a Excel en Python
Antes de comenzar, echemos un vistazo a las clases y métodos principales para convertir archivos PDF a Excel usando la biblioteca Spire.PDF for Python.
- Clase PdfDocument: representa un modelo de documento PDF.
- Clase XlsxLineLayoutOptions: se utiliza para especificar las opciones de conversión para controlar cómo se convertirá su PDF a Excel. El constructor de la clase XlsxLineLayoutOptions acepta los cinco parámetros siguientes:
- convertToMultipleSheet (bool): especifica si se debe convertir cada página en una hoja de cálculo diferente en el mismo Excel. Si se establece en Falso, todas las páginas de un archivo PDF se convertirán en una única hoja de cálculo de Excel.
- texto rotado (bool): especifica si se muestra el texto rotado.
- splitCell (bool): especifica si se debe convertir el texto de una celda de PDF (que abarca más de dos líneas) a una celda de Excel o a varias celdas.
- wrapText (bool): especifica si se debe ajustar el texto en una celda de Excel.
- superposición de texto (bool): especifica si se mostrará texto superpuesto.
- Método PdfDocument.ConvertOptions.SetPdfToXlsxOptions(): Aplica la opción de conversión.
- Método PdfDocument.SaveToFile (nombre de archivo de cadena, FileFormat.XLSX): guarda el PDF en formato Excel XLSX.
Los siguientes son los pasos principales que muestran cómo convertir PDF a Excel en Python.
- 1. Instale Spire.PDF for Python.
- 2. Importe los módulos necesarios.
- 3. Cree un objeto de la clase PdfDocument.
- 4. Cargue un archivo PDF mediante el método PdfDocument.LoadFromFile().
- 5. Si necesita configurar las opciones de conversión, cree un objeto de la clase XlsxLineLayoutOptions y pase los parámetros correspondientes a su constructor.
- 6. Aplique las opciones de conversión a través del método PdfDocument.ConvertOptions.SetPdfToXlsxOptions().
- 7. Llame al método PdfDocument.SaveToFile() para convertir PDF a Excel.
Convertir PDF a Excel XLSX en Python
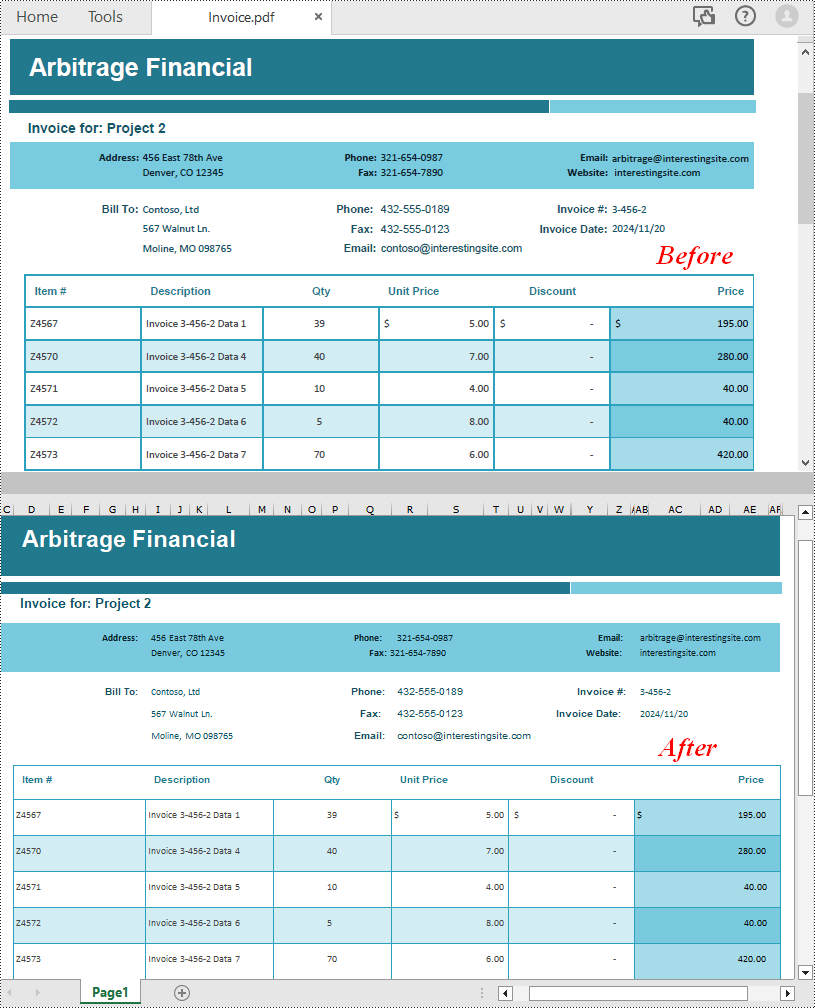
Es bastante fácil convertir PDF a Excel usando Spire.PDF for Python. Sólo necesitamos cargar un archivo PDF y luego guardarlo en formato XLSX. Sólo se requieren tres líneas de código para una conversión sencilla de PDF a Excel en Python.
- Python
from spire.pdf.common import *
from spire.pdf import *
inputFile = "Invoice.pdf"
outputFile = "PdfToExcel.xlsx"
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile(inputFile)
# Save the PDF file to Excel XLSX format
pdf.SaveToFile(outputFile, FileFormat.XLSX)
pdf.Close()
Convierta un PDF de varias páginas en una hoja de Excel en Python
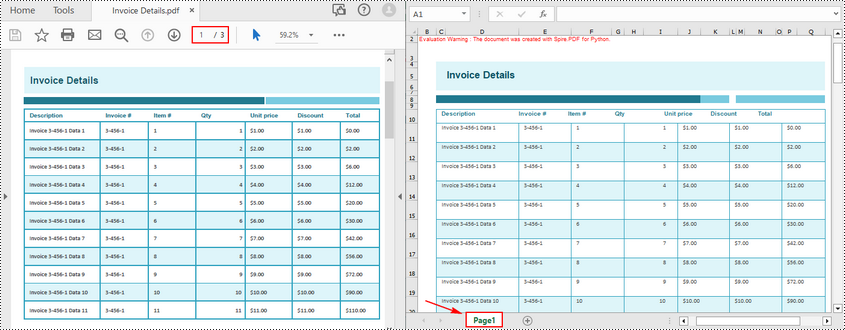
Además del método de conversión simple, Spire.PDF for Python también nos permite personalizar las opciones de conversión a través de la clase XlsxLineLayoutOptions mientras convertimos PDF a Excel. Como se introdujo anteriormente, podemos establecer el primer parámetro de su constructor, convertToMultipleSheet, en False para convertir varias páginas PDF en una hoja de Excel.
- Python
from spire.pdf.common import *
from spire.pdf import *
inputFile = "Invoice Details.pdf"
outputFile = "PdfToExcelwithOptions.xlsx"
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile(inputFile)
# Create an XlsxLineLayoutOptions object to specify the conversion options
# Parameters: convertToMultipleSheet, rotatedText, splitCell, wrapText, overlapText
pdf.ConvertOptions.SetPdfToXlsxOptions(XlsxLineLayoutOptions(False, True, False, True, False))
# Save the PDF file to Excel xlsx format
pdf.SaveToFile(outputFile, FileFormat.XLSX)
pdf.Close()
Licencia gratuita para convertidor de PDF a Excel
Para usar Spire.PDF for Python para la conversión de PDF a Excel sin marcas de agua ni limitaciones, solicite una licencia temporal gratuita de 1 mes.
Conclusión
Este artículo proporciona pasos detallados y ejemplos de código para demostrar cómo convertir PDF a Excel usando Python. Al utilizar la clase XlsxLineLayoutOptions de Spire.PDF for Python, podemos personalizar las opciones de conversión de PDF a Excel para lograr el efecto de conversión deseado, como convertir un PDF de varias páginas a una hoja de cálculo de Excel, ajustar el texto en la celda de Excel convertida, mostrar /ocultar texto rotado, etc.
No dude en explorar otras funciones de conversión y procesamiento de PDF de la biblioteca Spire.PDF for Python utilizando el documentación. Para cualquier problema durante la prueba, comuníquese con nuestro equipo de soporte técnico por correo electrónico o foro.
