Table of Contents
Installed via NuGet
PM> Install-Package Spire.PDF
Related Links
Many financial reports, research papers, legal documents, or invoices are often distributed in PDF format. Reading PDF files enables you to extract information, analyze content, and perform data processing tasks such as text extraction, keyword search, document classification, and data mining.
By using C# to read PDF, you can automate the repetitive task to realize efficient retrieval of specific information from a large collection of PDF files. This is valuable for applications that require searching through extensive archives, digital libraries, or document repositories. This article will give the following examples to show you how to read PDF file in C#.
- Read Text from a PDF Page in C#
- Read Text from a PDF Page Area in C#
- Read PDF Without Preserving Text Layout in C#
- Extract Images and Tables in PDF in C#
C# PDF Reader Library
Spire.PDF for .NET library can serve as a PDF reader library that allows developers to integrate PDF reading capabilities into their applications. It provides functions and APIs for parsing, rendering, and processing of PDF files within .NET applications.
You can either download the C# PDF reader to manually add the DLL files as references in your .NET project, or install it directly via NuGet.
PM> Install-Package Spire.PDF
Read Text from a PDF Page in C#
Spire.PDF for .NET makes it easy to read PDF text in C# through the PdfTextExtractor class. The following are the steps to read all text from a specified PDF page.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and set the IsExtractAllText property to true.
- Extract text from the selected page using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
The following code example shows how to use C# to read PDF text from a specified page.
- C#
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDF.txt", text);
}
}
}
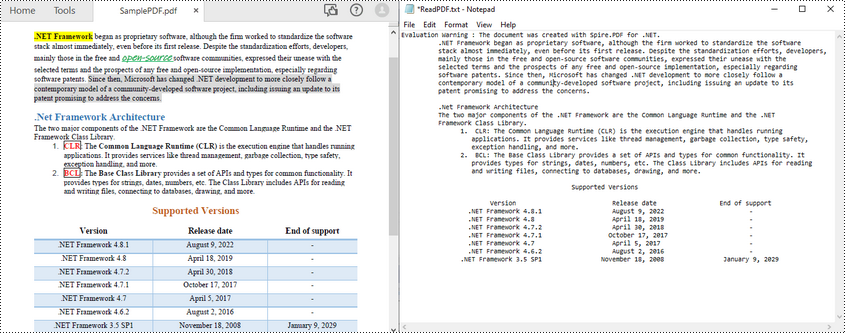
Read Text from a PDF Page Area in C#
To read PDF text from a specified page area in PDF, you can first define a rectangle area and then call the setExtractArea() method of PdfTextExtractOptions class to extract text from it. The following are the steps to extract PDF text from a rectangle area of a page.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object, and specify the rectangle area through the ExtractArea property of it.
- Extract text from the rectangle using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
The following code sample shows how to use C# to read PDF text from a specified page area.
- C#
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Specify a rectangle area
extractOptions.ExtractArea = new RectangleF(0, 180, 800, 160);
//Read PDF text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDFArea.txt", text);
}
}
}
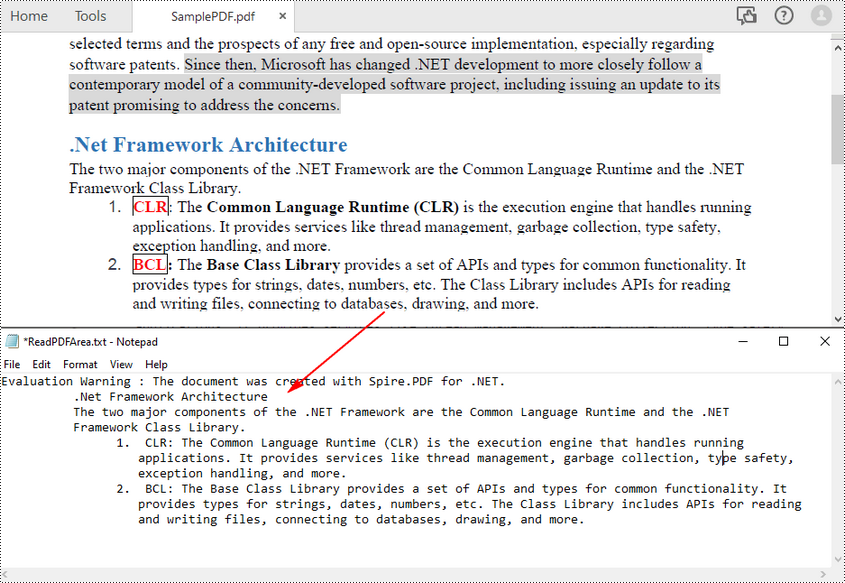
Read PDF Without Preserving Text Layout in C#
The above methods read PDF text line by line. You can also read PDF text simply without retain its layout using the SimpleExtraction strategy. It keeps track of the current Y position of each string and inserts a line break into the output if the Y position has changed. The following are the steps to read PDF text simply.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the specific page through PdfDocument.Pages[index] property.
- Create a PdfTextExtractor object.
- Create a PdfTextExtractOptions object and set the IsSimpleExtraction property to true.
- Extract text from the selected page using PdfTextExtractor.ExtractText() method.
- Write the extracted text to a TXT file.
The following code sample shows how to use C# to read PDF text without preserving text layout.
- C#
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true to
extractOptions.IsSimpleExtraction = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ExtractPDF.txt", text);
}
}
}
Extract Images and Tables in PDF in C#
In addition to read PDF text in C#, Spire.PDF for .NET library also allows you to extract images from PDF or read only the table data in a PDF file. The following links will direct you to the relevant official tutorials:
- Extract Images from PDF in C#
- Extract Table Data from PDF in C#
- Extract Tables from PDF to Excel in C#
Conclusion
This article introduced various ways to read PDF file in C#. You can learn from the given examples on how to read PDF text from a specified page, from a specified rectangle area, or read PDF files without preserving text layout. In addition, extracting images or tables in a PDF file can also be achieved with the Spire.PDF for .NET library.
Explore more PDF processing and conversion capabilities of the .NET PDF library using the documentation. If any issues occurred while testing, feel free to contact technical support team via email or forum.
