
Sometimes, we need to extract the OLE Objects that are embedded in a word document. With Spire.Doc, we can easily achieve this task with a few lines of code. This article explains how to extract the embedded PDF document and Excel workbook from a word document using Spire.Doc and C#.
Below is the screenshot of the word document:
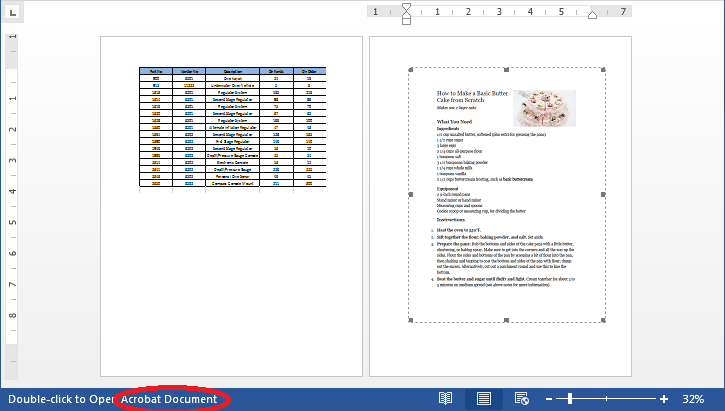
Detail steps:
Step 1: Instantiate a Document object and load the word document.
Document doc = new Document();
doc.LoadFromFile("OleObject.docx");
Step 2: Traverse through the word document, find the Ole Objects, then get the Object type of each Ole Object to determine if the Ole Object is PDF document or Excel workbook and write the native data of the Ole object into a new PDF document or an Excel workbook.
//Traverse through all sections of the word document
foreach (Section sec in doc.Sections)
{
//Traverse through all Child Objects in the body of each section
foreach (DocumentObject obj in sec.Body.ChildObjects)
{
if (obj is Paragraph)
{
Paragraph par = obj as Paragraph;
//Traverse through all Child Objects in Paragraph
foreach (DocumentObject o in par.ChildObjects)
{
//Find the Ole Objects and Extract
if (o.DocumentObjectType == DocumentObjectType.OleObject)
{
DocOleObject Ole = o as DocOleObject;
string s = Ole.ObjectType;
//If s == "AcroExch.Document.11", means it’s a PDF document
if (s == "AcroExch.Document.11")
{
File.WriteAllBytes("Result.pdf", Ole.NativeData);
}
//If s == " Excel.Sheet.12", means it’s an Excel workbook
else if (s == "Excel.Sheet.12")
{
File.WriteAllBytes("Result.xlsx", Ole.NativeData);
}
}
}
}
}
}
Below is the screenshot of the extracted PDF file and Excel workbook after running the code:
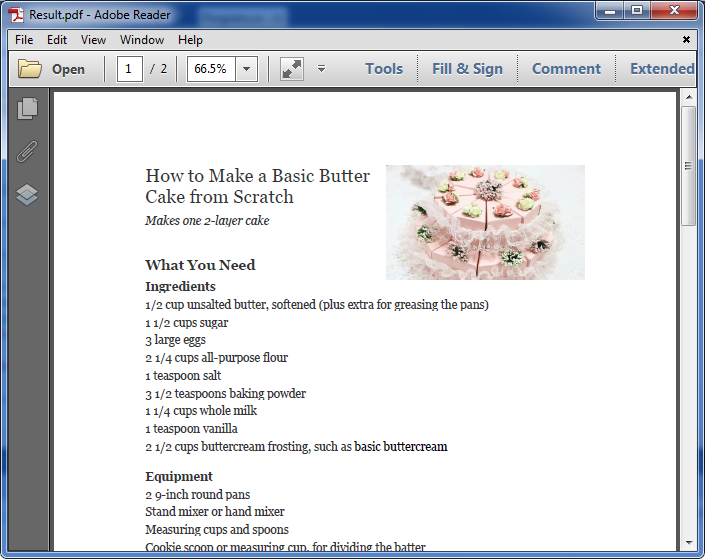
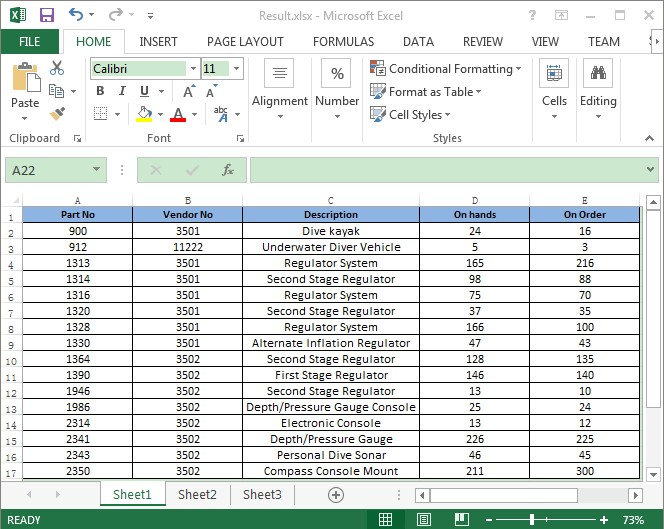
Full codes:
using System.IO;
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
namespace Extract_OLEObjects_from_Word
{
class Program
{
static void Main(string[] args)
{
Document doc = new Document();
doc.LoadFromFile("OleObject.docx");
foreach (Section sec in doc.Sections)
{
foreach (DocumentObject obj in sec.Body.ChildObjects)
{
if (obj is Paragraph)
{
Paragraph par = obj as Paragraph;
foreach (DocumentObject o in par.ChildObjects)
{
if (o.DocumentObjectType == DocumentObjectType.OleObject)
{
DocOleObject Ole = o as DocOleObject;
string s = Ole.ObjectType;
if (s == "AcroExch.Document.11")
{
File.WriteAllBytes("Result.pdf", Ole.NativeData);
}
else if (s == "Excel.Sheet.12")
{
File.WriteAllBytes("Result.xlsx", Ole.NativeData);
}
}
}
}
}
}
}
}
}
