
Comments in Word documents are often used for collaborative review and feedback purposes. They may contain text and images that provide valuable information to guide document improvements. Extracting the text and images from comments allows you to analyze and evaluate the feedback provided by reviewers, helping you gain a comprehensive understanding of the strengths, weaknesses, and suggestions related to the document. In this article, we will demonstrate how to extract text and images from Word comments in Python using Spire.Doc for Python.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Extract Text from Word Comments in Python
You can easily retrieve the author and text of a Word comment using the Comment.Format.Author and Comment.Body.Paragraphs[index].Text properties provided by Spire.Doc for Python. The detailed steps are as follows.
- Create an object of the Document class.
- Load a Word document using the Document.LoadFromFile() method.
- Create a list to store the extracted comment data.
- Iterate through the comments in the document.
- For each comment, iterate through the paragraphs of the comment body.
- For each paragraph, get the text using the Comment.Body.Paragraphs[index].Text property.
- Get the author of the comment using the Comment.Format.Author property.
- Add the text and author of the comment to the list.
- Save the content of the list to a text file.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of the Document class
document = Document()
# Load a Word document containing comments
document.LoadFromFile("Comments.docx")
# Create a list to store the extracted comment data
comments = []
# Iterate through the comments in the document
for i in range(document.Comments.Count):
comment = document.Comments[i]
comment_text = ""
# Iterate through the paragraphs in the comment body
for j in range(comment.Body.Paragraphs.Count):
paragraph = comment.Body.Paragraphs[j]
comment_text += paragraph.Text + "\n"
# Get the comment author
comment_author = comment.Format.Author
# Append the comment data to the list
comments.append({
"author": comment_author,
"text": comment_text
})
# Write the comment data to a file
with open("comment_data.txt", "w", encoding="utf-8") as file:
for comment in comments:
file.write(f"Author: {comment['author']}\nText: {comment['text']}\n\n")
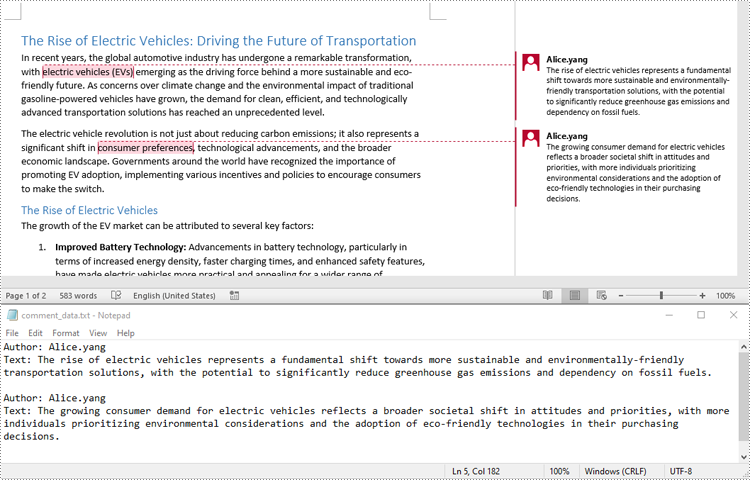
Extract Images from Word Comments in Python
To extract images from Word comments, you need to iterate through the child objects in the paragraphs of the comments to find the DocPicture objects, then get the image data using DocPicture.ImageBytes property, finally save the image data to image files.
- Create an object of the Document class.
- Load a Word document using the Document.LoadFromFile() method.
- Create a list to store the extracted image data.
- Iterate through the comments in the document.
- For each comment, iterate through the paragraphs of the comment body.
- For each paragraph, iterate through the child objects of the paragraph.
- Check if the object is a DocPicture object.
- If the object is a DocPicture, get the image data using the DocPicture.ImageBytes property and add it to the list.
- Save the image data in the list to individual image files.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of the Document class
document = Document()
# Load a Word document containing comments
document.LoadFromFile("Comments.docx")
# Create a list to store the extracted image data
images = []
# Iterate through the comments in the document
for i in range(document.Comments.Count):
comment = document.Comments[i]
# Iterate through the paragraphs in the comment body
for j in range(comment.Body.Paragraphs.Count):
paragraph = comment.Body.Paragraphs[j]
# Iterate through the child objects in the paragraph
for o in range(paragraph.ChildObjects.Count):
obj = paragraph.ChildObjects[o]
# Find the images
if isinstance(obj, DocPicture):
picture = obj
# Get the image data and add it to the list
data_bytes = picture.ImageBytes
images.append(data_bytes)
# Save the image data to image files
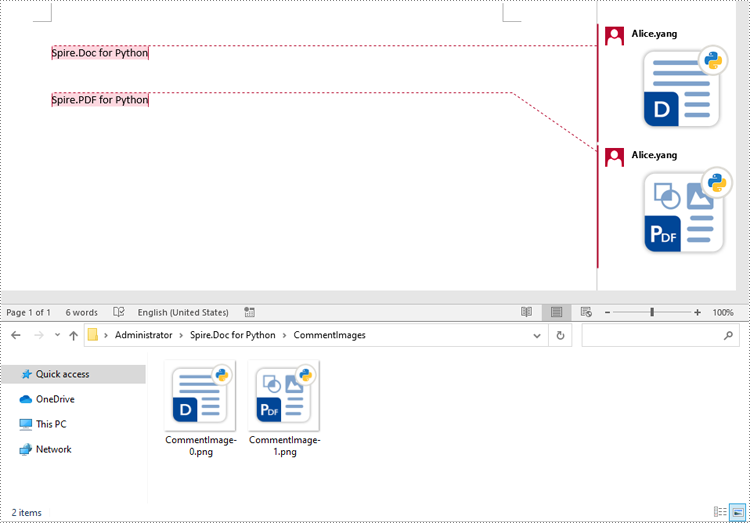
for i, image_data in enumerate(images):
file_name = f"CommentImage-{i}.png"
with open(os.path.join("CommentImages/", file_name), 'wb') as image_file:
image_file.write(image_data)
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
