
Text and images are crucial elements that can enrich the content of a Word document. When users need to manipulate text or images separately of the document, programmatically extracting them from a Word document provides an optimal solution. Extracting text guarantees greater convenience and efficiency when dealing with large documents compared to manually copying text. Additionally, image extraction enables users to perform further editing on the images of the document or effortlessly share them with others. In this article, we will demonstrate how to extract text and images from Word in Java by using Spire.Doc for Java library.
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.11.0</version>
</dependency>
</dependencies>
Extract Text from Word in Java
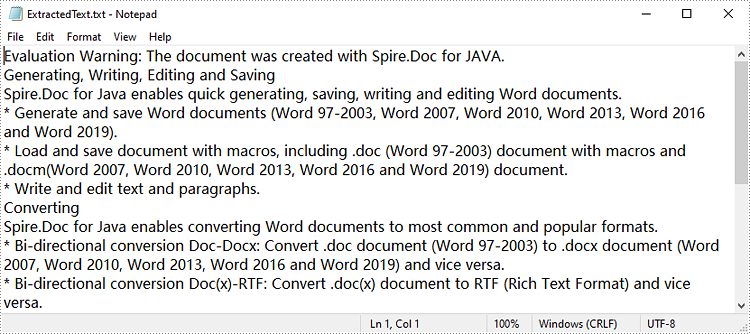
Spire.Doc for Java supports extracting text from Word documents and saving it as a text file format, which allows users to view text content without device restrictions. Below are detailed steps for extracting text from a Word document.
- Create a Document object.
- Load a word document using Document.loadFromFile method.
- Get text from document as string using Document.getText() method.
- Call writeStringToTxt() method to write string to a specified text file.
- Java
import com.spire.doc.Document;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractText {
public static void main(String[] args) throws IOException {
//Create a Document object and load a Word document
Document document = new Document();
document.loadFromFile("sample1.docx");
//Get text from document as string
String text=document.getText();
//Write string to a .txt file
writeStringToTxt(text," ExtractedText.txt");
}
public static void writeStringToTxt(String content, String txtFileName) throws IOException{
FileWriter fWriter= new FileWriter(txtFileName,true);
try {
fWriter.write(content);
}catch(IOException ex){
ex.printStackTrace();
}finally{
try{
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
Extract Images from Word in Java
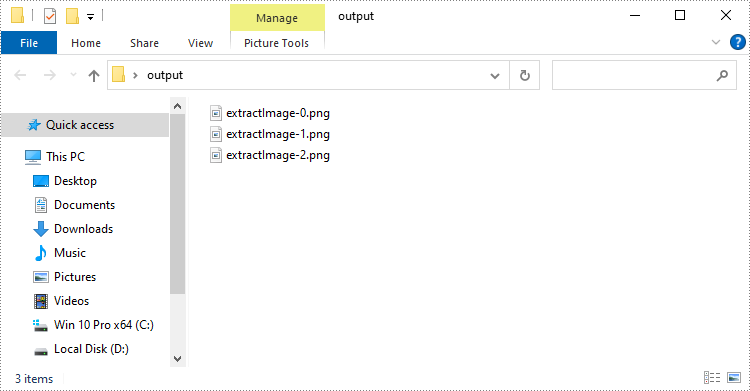
By extracting images, users are able to import image data into other applications for further processing without difficulty. Spire.Doc for Java allows users to extract images from Word documents and save them to the specified path. The following are detailed steps.
- Create a Document object.
- Load a Word document using Document.loadFromFile() method.
- Create a queue of composite objects.
- Add the root document element to the traversal queue using Queue<ICompositeObject>.add(ICompositeObject e) method.
- Create a ArrayList object to store extracted images.
- Traverse the document tree and check for composite or picture objects by iterating over the children node of each node.
- Check if the child element is a composite object. If so, add it to the queue for further processing.
- Check if the child element is a picture object. If so, extract its image data and add it to the extracted image list.
- Save images to the specific folder using ImageIO.write(RenderedImage im, String formatName, File output) method.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import com.spire.doc.fields.*;
import com.spire.doc.interfaces.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.*;
import java.util.*;
public class ExtractImage {
public static void main(String[] args) throws IOException {
//Create a Document object and load a Word document
Document document = new Document();
document.loadFromFile("sample2.docx");
//Create a queue and add the root document element to it
Queue<ICompositeObject> nodes = new LinkedList<>();
nodes.add(document);
//Create a ArrayList object to store extracted images
List<BufferedImage> images = new ArrayList<>();
//Traverse the document tree
while (nodes.size() > 0) {
ICompositeObject node = nodes.poll();
for (int i = 0; i < node.getChildObjects().getCount(); i++)
{
IDocumentObject child = node.getChildObjects().get(i);
if (child instanceof ICompositeObject)
{
nodes.add((ICompositeObject) child);
}
else if (child.getDocumentObjectType() == DocumentObjectType.Picture)
{
DocPicture picture = (DocPicture) child;
images.add(picture.getImage());
}
}
}
//Save images to the specific folder
for (int i = 0; i < images.size(); i++) {
File file = new File(String.format("output/extractImage-%d.png", i));
ImageIO.write(images.get(i), "PNG", file);
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
