
Extracting text and images from PDF files enables you to quickly reuse these contents in other types of files, such as Word documents, web pages, or presentations. This approach can help you save a significant amount of time and effort, as it eliminates the tedious and time-consuming process of re-typing information from scratch. In this article, you will learn how to extract text and images from a PDF file in C++ using Spire.PDF for C++.
- Extract Text from a PDF File in C++
- Extract Text from a Specific Page Area in a PDF File in C++
- Extract Images from a PDF File in C++
Install Spire.PDF for C++
There are two ways to integrate Spire.PDF for C++ into your application. One way is to install it through NuGet, and the other way is to download the package from our website and copy the libraries into your program. Installation via NuGet is simpler and more recommended. You can find more details by visiting the following link.
Integrate Spire.PDF for C++ in a C++ Application
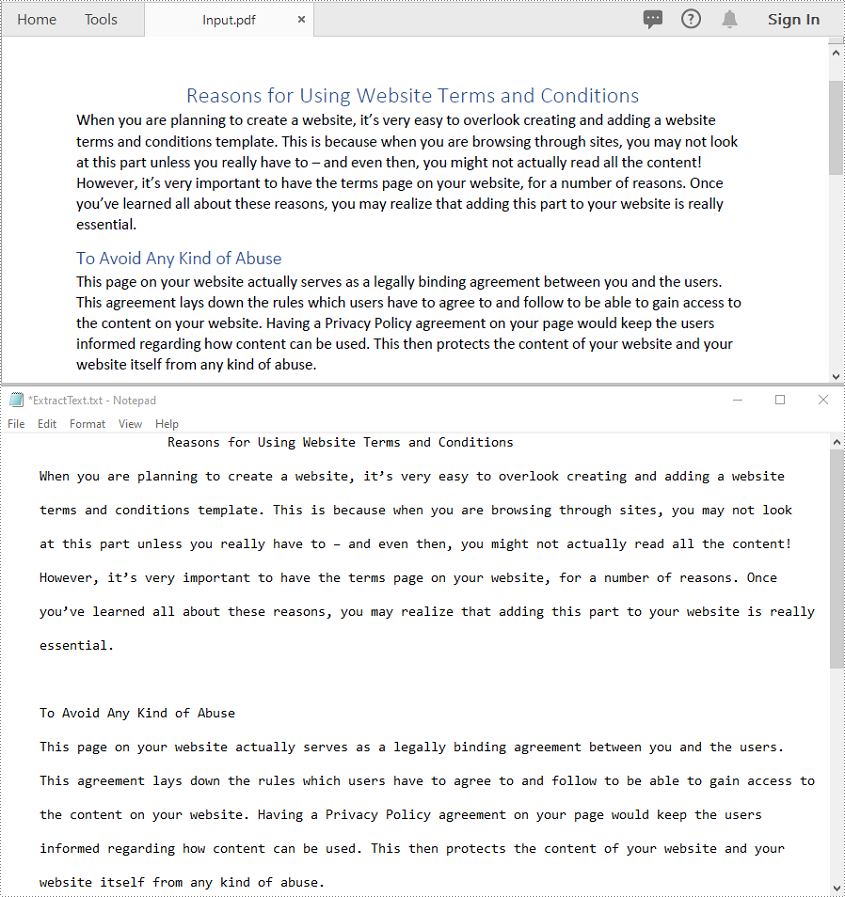
Extract Text from a PDF File in C++
Spire.PDF for C++ offers the PdfPageBase->ExtractText() method which enables you to extract text from the pages in a PDF file. The detailed steps are as follows:
- Initialize an instance of the PdfDocument class.
- Load a PDF file using PdfDocument->LoadFromFile() method.
- Iterate through all pages in the file.
- Extract text from the pages using PdfPageBase->ExtractText() method.
- Save the extracted text to a .txt file.
- C++
#include "Spire.Pdf.o.h"
#include <locale>
#include <codecvt>
using namespace Spire::Pdf;
using namespace std;
int main()
{
//Initialize an instance of the PdfDocument class
PdfDocument* doc = new PdfDocument();
//Load a PDF file
doc->LoadFromFile(L"Input.pdf");
wstring buffer = L"";
//Iterate through all pages in the file
for (int i = 0; i < doc->GetPages()->GetCount(); i++)
{
PdfPageBase* page = doc->GetPages()->GetItem(i);
//Extract text from the pages
buffer += (page->ExtractText());
}
//Save the extracted text to a .txt file
wofstream write(L"ExtractText.txt");
auto LocUtf8 = locale(locale(""), new std::codecvt_utf8<wchar_t>);
write.imbue(LocUtf8);
write << buffer;
write.close();
doc->Close();
delete doc;
}
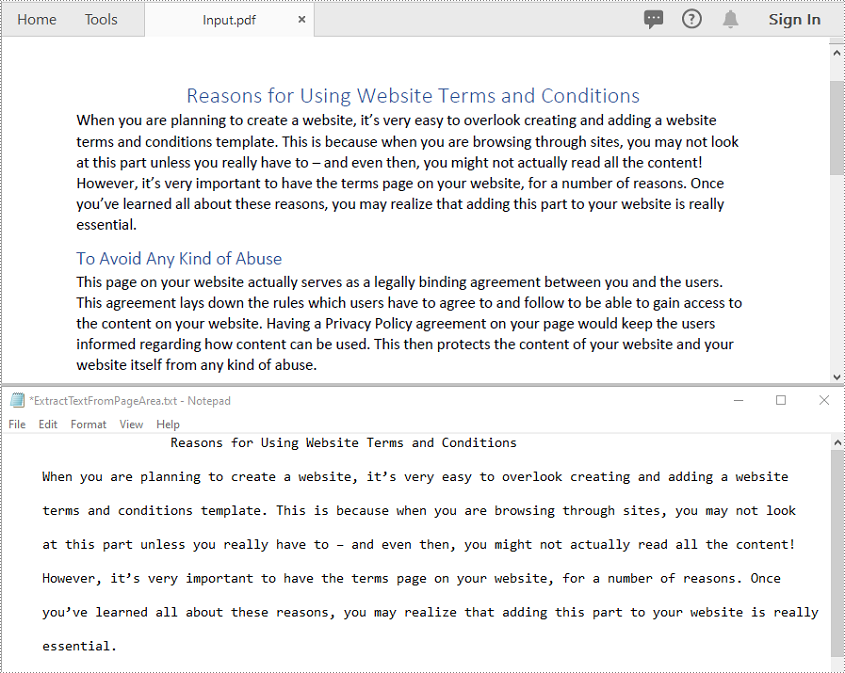
Extract Text from a Specific Page Area in a PDF File in C++
You can extract text from a specific rectangular area of a PDF page using Page->ExtractText(RectangleF* rectangleF) method. The detailed steps are as follows:
- Initialize an instance of the PdfDocument class.
- Load a PDF file using PdfDocument->LoadFromFile() method.
- Get a specific page by its index using PdfDocument->GetPages()->GetItem(int index) method.
- Extract text from a specific rectangular area of the page using Page->ExtractText(RectangleF* rectangleF) method.
- Save the extracted text to a .txt file.
- C++
#include "Spire.Pdf.o.h"
#include <locale>
#include <codecvt>
using namespace Spire::Pdf;
using namespace std;
int main()
{
//Initialize an instance of the PdfDocument class
PdfDocument* doc = new PdfDocument();
//Load a PDF file
doc->LoadFromFile(L"Input.pdf");
//Get the first page
PdfPageBase* page = doc->GetPages()->GetItem(0);
//Extract text from a specific rectangular area in the page
wstring text = page->ExtractText(new RectangleF(0, 0, 600, 200));
//Save the extracted text to a .txt file
wofstream write(L"ExtractTextFromPageArea.txt");
auto LocUtf8 = locale(locale(""), new std::codecvt_utf8<wchar_t>);
write.imbue(LocUtf8);
write << text;
write.close();
doc->Close();
delete doc;
}
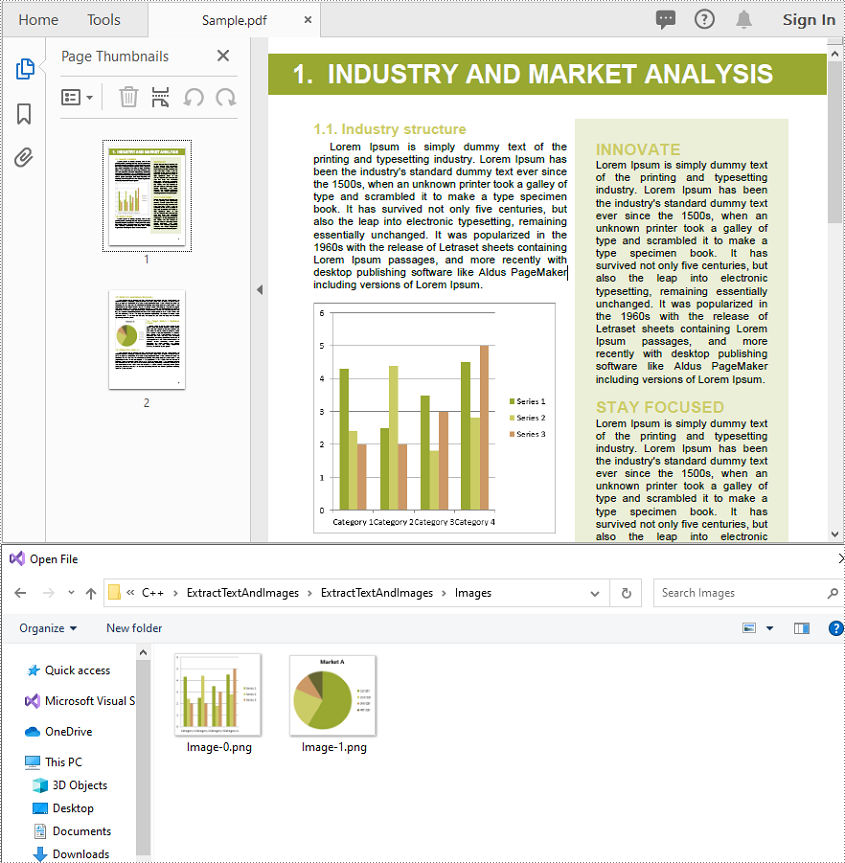
Extract Images from a PDF File in C++
You can use the PdfPageBase->ExtractImages() method to extract images from the pages in a PDF file. The detailed steps are as follows:
- Initialize an instance of the PdfDocument class.
- Load a PDF file using PdfDocument->LoadFromFile() method.
- Iterate through all pages in the file.
- Extract images from the pages using PdfPageBase->ExtractImages() method.
- Save the extracted images to PNG files.
- C++
#include "Spire.Pdf.o.h"
#include <locale>
#include <codecvt>
using namespace Spire::Pdf;
using namespace std;
int main()
{
//Initialize an instance of the PdfDocument class
PdfDocument* doc = new PdfDocument();
//Load a PDF file
doc->LoadFromFile(L"Sample.pdf");
int index = 0;
//Iterate through all pages in the file
for (int i = 0; i < doc->GetPages()->GetCount(); i++)
{
PdfPageBase* page = doc->GetPages()->GetItem(i);
//Extract images from the pages
for (auto image : page->ExtractImages())
{
std::wstring imageFileName = L"Images\\Image-" + to_wstring(index) + L".png";
image->Save(imageFileName.c_str(), ImageFormat::GetPng());
index++;
}
}
doc->Close();
delete doc;
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
