
Extracting images from PDFs is a common task for many users, whether it's for repurposing visuals in a presentation, archiving important graphics, or facilitating easier analysis. By mastering image extraction using C#, developers can enhance resource management and streamline their workflow.
In this article, you will learn how to extract images from individual PDF pages as well as from entire documents using C# and Spire.PDF for .NET.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
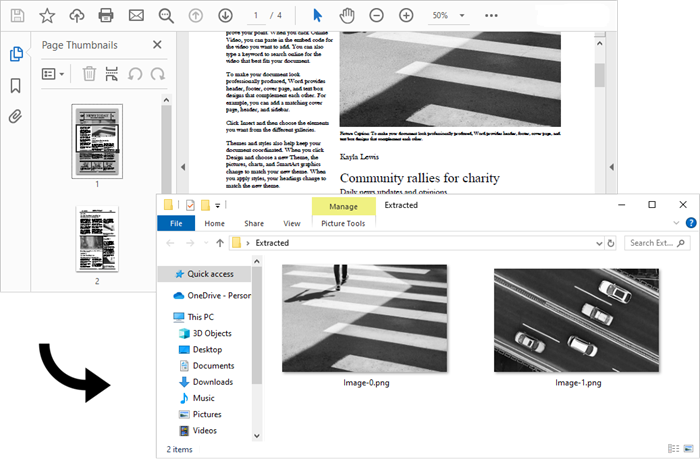
Extract Images from a Specific PDF Page
The PdfImageHelper class in Spire.PDF for .NET is designed to help users manage images within PDF documents. It allows for various operations, such as deleting, replacing, and retrieving images.
To obtain information about the images on a specific PDF page, developers can utilize the PdfImageHelper.GetImagesInfo(PdfPageBase page) method. Once they have the image information, they can save the images to files using the PdfImageInfo.Image.Save() method.
The steps to extract images from a specific PDF page are as follows:
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specific page using PdfDocument.Pages[index] property.
- Create a PdfImageHelper object.
- Get the image information collection from the page using PdfImageHelper.GetImagesInfo() method.
- Iterate through the image information collection and save each instance as a PNG file using PdfImageInfo.Image.Save() method.
- C#
using Spire.Pdf;
using Spire.Pdf.Utilities;
using System.Drawing;
namespace ExtractImagesFromSpecificPage
{
class Program
{
static void Main(string[] args)
{
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Get a specific page
PdfPageBase page = doc.Pages[0];
// Create a PdfImageHelper object
PdfImageHelper imageHelper = new PdfImageHelper();
// Get all image information from the page
PdfImageInfo[] imageInfos = imageHelper.GetImagesInfo(page);
// Iterate through the image information
for (int i = 0; i < imageInfos.Length; i++)
{
// Get a specific image information
PdfImageInfo imageInfo = imageInfos[i];
// Get the image
Image image = imageInfo.Image;
// Save the image to a png file
image.Save("C:\\Users\\Administrator\\Desktop\\Extracted\\Image-" + i + ".png");
}
// Dispose resources
doc.Dispose();
}
}
}
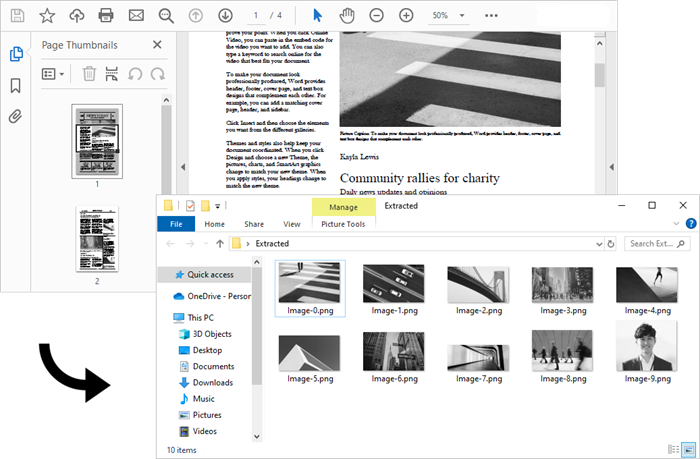
Extract All Images from an Entire PDF Document
Now that you know how to extract images from a specific page, you can iterate through the pages in a PDF document and extract images from each page. This allows you to collect all the images contained in the document.
The steps to extract all images throughout an entire PDF document are as follows:
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Create a PdfImageHelper object.
- Iterate through the pages in the document.
- Get a specific page using PdfDocument.Pages[index] property.
- Get the image information collection from the page using PdfImageHelper.GetImagesInfo() method.
- Iterate through the image information collection and save each instance as a PNG file using PdfImageInfo.Image.Save() method.
- C#
using Spire.Pdf;
using Spire.Pdf.Utilities;
using System.Drawing;
namespace ExtractAllImages
{
class Program
{
static void Main(string[] args)
{
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Create a PdfImageHelper object
PdfImageHelper imageHelper = new PdfImageHelper();
// Declare an int variable
int m = 0;
// Iterate through the pages
for (int i = 0; i < doc.Pages.Count; i++)
{
// Get a specific page
PdfPageBase page = doc.Pages[i];
// Get all image information from the page
PdfImageInfo[] imageInfos = imageHelper.GetImagesInfo(page);
// Iterate through the image information
for (int j = 0; j < imageInfos.Length; j++)
{
// Get a specific image information
PdfImageInfo imageInfo = imageInfos[j];
// Get the image
Image image = imageInfo.Image;
// Save the image to a png file
image.Save("C:\\Users\\Administrator\\Desktop\\Extracted\\Image-" + m + ".png");
m++;
}
}
// Dispose resources
doc.Dispose();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.

