Java: Convert RTF to HTML, Image
Converting RTF to HTML helps improve accessibility as HTML documents can be easily displayed in web browsers, making them accessible to a global audience. While converting RTF to images can help preserve document layout as images can accurately represent the original document, including fonts, colors, and graphics. In this article, you will learn how to convert RTF to HTML or images in Java using Spire.Doc for Java.
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.11.0</version>
</dependency>
</dependencies>
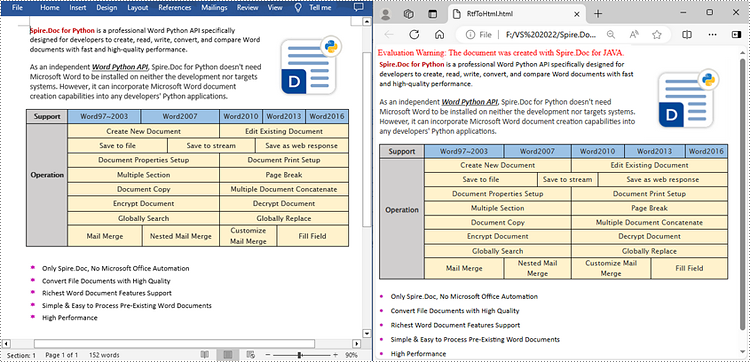
Convert RTF to HTML in Java
Converting RTF to HTML ensures that the document can be easily viewed and edited in any modern web browser without requiring any additional software.
With Spire.Doc for Java, you can achieve RTF to HTML conversion through the Document.saveToFile(String fileName, FileFormat.Html) method. The following are the detailed steps.
- Create a Document instance.
- Load an RTF document using Document.loadFromFile() method.
- Save the RTF document in HTML format using Document.saveToFile(String fileName, FileFormat.Html) method.
- Java
import com.spire.doc.*;
public class RTFToHTML {
public static void main(String[] args) {
// Create a Document instance
Document document = new Document();
// Load an RTF document
document.loadFromFile("input.rtf", FileFormat.Rtf);
// Save as HTML format
document.saveToFile("RtfToHtml.html", FileFormat.Html);
document.dispose();
}
}
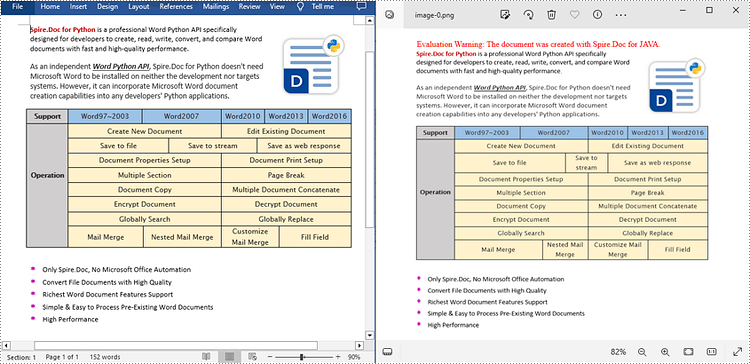
Convert RTF to Image in Java
To convert RTF to images, you can use the Document.saveToImages() method to convert an RTF file into individual Bitmap or Metafile images. Then, the Bitmap or Metafile images can be saved as a BMP, EMF, JPEG, PNG, GIF, or WMF format files. The following are the detailed steps.
- Create a Document object.
- Load an RTF document using Document.loadFromFile() method.
- Convert the document to images using Document.saveToImages() method.
- Iterate through the converted image, and then save each as a PNG file.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
public class RTFtoImage {
public static void main(String[] args) throws Exception{
// Create a Document instance
Document document = new Document();
// Load an RTF document
document.loadFromFile("input.rtf", FileFormat.Rtf);
// Convert the RTF document to images
BufferedImage[] images = document.saveToImages(ImageType.Bitmap);
// Iterate through the image collection
for (int i = 0; i < images.length; i++) {
// Get the specific image
BufferedImage image = images[i];
// Save the image as png format
File file = new File("Images\\" + String.format(("Image-%d.png"), i));
ImageIO.write(image, "PNG", file);
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Convert Markdown to Word and PDF
Markdown is a popular format among writers and developers for its simplicity and readability, allowing content to be formatted using easy-to-write plain text syntax. However, converting Markdown files to universally accessible formats like Word documents and PDF files is essential for sharing documents with readers, enabling complex formatting, and ensuring capability and consistency across devices and platforms. This article demonstrates how to convert Markdown files to Word and PDF files with the powerful library Spire.Doc for Java, enhancing the versatility and distribution potential of your written content.
- Convert a Markdown File to a Word Document with Java
- Convert a Markdown File to a PDF Document with Java
- Customizing Page Settings of the Result Document
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.11.0</version>
</dependency>
</dependencies>
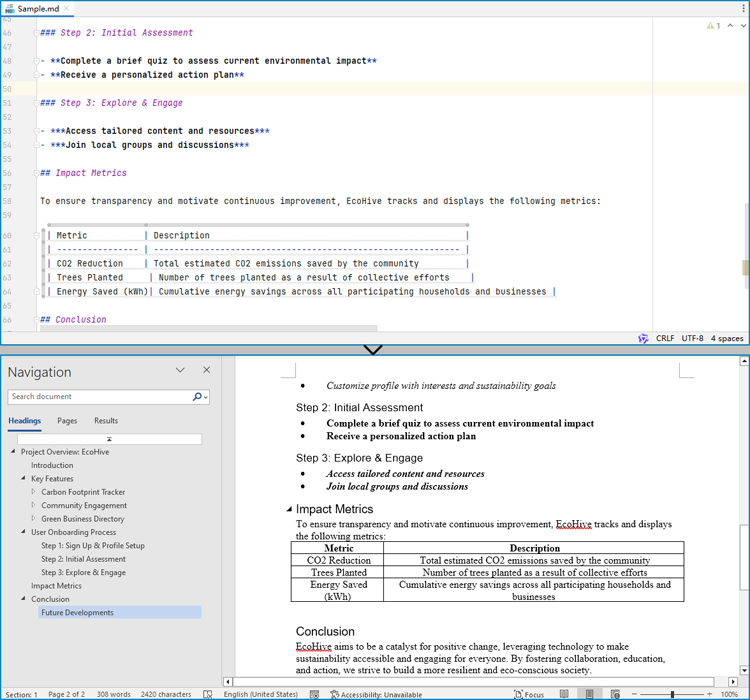
Convert a Markdown File to a Word Document with Java
Spire.Doc for Java provides a simple way to convert Markdown format to Word and PDF document formats by using the Document.loadFromFile(String: fileName, FileFormat.Markdown) method to load the Markdown file and the Document.saveToFile(String: fileName, FileFormat: fileFormat) method to save the file as a Word or PDF document.
It should be noted that since images are stored as links in Markdown files, they need to be further processed after conversion if they are to be retained.
The detailed steps for converting a Markdown file to a Word document are as follows:
- Create an instance of Document class.
- Load a Markdown file using Document.loadFromFile(String: fileName, FileFormat.Markdown) method.
- Save the Markdown file as Word document using Document.saveToFile(String: fileName, FileFormat.Docx) method.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class MarkdownToWord {
public static void main(String[] args) {
// Create an instance of Document
Document doc = new Document();
// Load a Markdown file
doc.loadFromFile("Sample.md", FileFormat.Markdown);
// Save the Markdown file as Word document
doc.saveToFile("output/MarkdownToWord.docx", FileFormat.Docx);
doc.dispose();
}
}
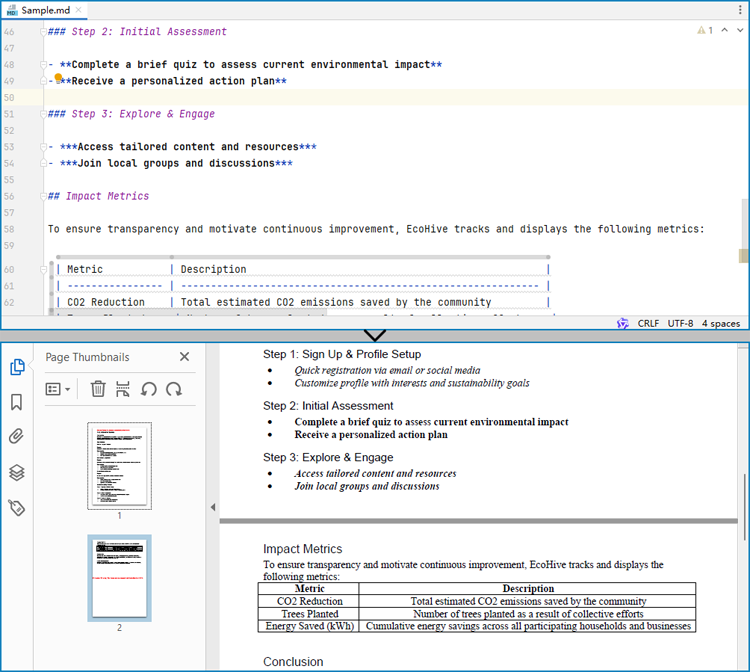
Convert a Markdown File to a PDF Document with Java
By using the FileFormat.PDF Enum as the format parameter of the Document.saveToFile() method, the Markdown file can be directly converted to a PDF document.
The detailed steps for converting a Markdown file to a PDF document are as follows:
- Create an instance of Document class.
- Load a Markdown file using Document.loadFromFile(String: fileName, FileFormat.Markdown) method.
- Save the Markdown file as PDF document using Document.saveToFile(String: fileName, FileFormat.PDF) method.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class MarkdownToPDF {
public static void main(String[] args) {
// Create an instance of the Document class
Document doc = new Document();
// Load a Markdown file
doc.loadFromFile("Sample.md");
// Save the Markdown file as a PDF file
doc.saveToFile("output/MarkdownToPDF.pdf", FileFormat.PDF);
doc.dispose();
}
}
Customizing Page Settings of the Result Document
Spire.Doc for Java also provides methods under PageSetup class to do page setup before the conversion, allowing control over page settings such as page margins and page size of the resulting document.
The following are the steps to customize the page settings of the resulting document:
- Create an instance of Document class.
- Load a Markdown file using Document.loadFromFile(String: fileName, FileFormat.Markdown) method.
- Get the first section using Document.getSections().get() method.
- Set the page size, page orientation, and page margins using methods under PageSetup class.
- Save the Markdown file as PDF document using Document.saveToFile(String: fileName, FileFormat.PDF) method.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import com.spire.doc.PageSetup;
import com.spire.doc.Section;
import com.spire.doc.documents.MarginsF;
import com.spire.doc.documents.PageOrientation;
import com.spire.doc.documents.PageSize;
public class PageSettingMarkdown {
public static void main(String[] args) {
// Create an instance of the Document class
Document doc = new Document();
// Load a Markdown file
doc.loadFromFile("Sample.md");
// Get the first section
Section section = doc.getSections().get(0);
// Set the page size, orientation, and margins
PageSetup pageSetup = section.getPageSetup();
pageSetup.setPageSize(PageSize.Letter);
pageSetup.setOrientation(PageOrientation.Landscape);
pageSetup.setMargins(new MarginsF(100, 100, 100, 100));
// Save the Markdown file as a PDF file
doc.saveToFile("output/MarkdownToPDF.pdf", FileFormat.PDF);
doc.dispose();
}
}

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Extract Text from HTML
HTML (Hypertext Markup Language) has become one of the most commonly used text markup languages on the Internet, and nearly all web pages are created using HTML. While HTML contains numerous tags and formatting information, the most valuable content is typically the visible text. It is important to know how to extract the text content from an HTML file when users intend to utilize it for tasks such as editing, AI training, or storing in databases. This article will demonstrate how to extract text from HTML using Spire.Doc for Java within Java programs.
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.11.0</version>
</dependency>
</dependencies>
Extract Text from HTML File
Spire.Doc for Java supports loading HTML files using the Document.loadFromFile(fileName, FileFormat.Html) method. Then, users can use Document.getText() method to get the text that is visible in browsers and write it to a TXT file. The detailed steps are as follows:
- Create an object of Document class.
- Load an HTML file using Document.loadFromFile(fileName, FileFormat.Html) method.
- Get the text of the HTML file using Document.getText() method.
- Write the text to a TXT file.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import java.io.FileWriter;
import java.io.IOException;
public class ExtractTextFromHTML {
public static void main(String[] args) throws IOException {
//Create an object of Document class
Document doc = new Document();
//Load an HTML file
doc.loadFromFile("Sample.html", FileFormat.Html);
//Get text from the HTML file
String text = doc.getText();
//Write the text to a TXT file
FileWriter fileWriter = new FileWriter("HTMLText.txt");
fileWriter.write(text);
fileWriter.close();
}
}
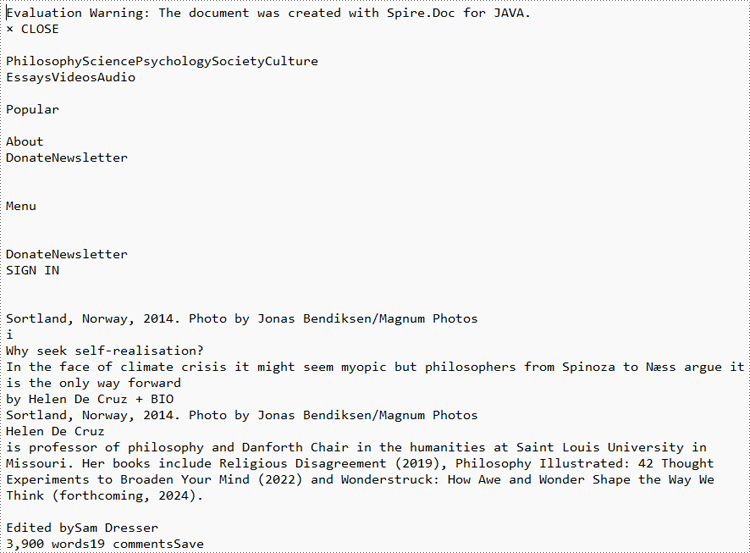
HTML Web Page:

Extracted Text:
Extract Text from URL
To extract text from a URL, users need to create a custom method to retrieve the HTML file from the URL and then extract the text from it. The detailed steps are as follows:
- Create an object of Document class.
- Use the custom method readHTML() to get the HTML file from a URL and return the file path.
- Load the HTML file using Document.loadFromFile(filename, FileFormat.Html) method.
- Get the text from the HTML file using Document.getText() method.
- Write the text to a TXT file.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
public class ExtractTextFromURL {
public static void main(String[] args) throws IOException {
//Create an object of Document
Document doc = new Document();
//Call the custom method to load the HTML file from a URL
doc.loadFromFile(readHTML("https://aeon.co/essays/how-to-face-the-climate-crisis-with-spinoza-and-self-knowledge", "output.html"), FileFormat.Html);
//Get the text from the HTML file
String urlText = doc.getText();
//Write the text to a TXT file
FileWriter fileWriter = new FileWriter("URLText.txt");
fileWriter.write(urlText);
}
public static String readHTML(String urlString, String saveHtmlFilePath) throws IOException {
//Create an object of URL class
URL url = new URL(urlString);
//Open the URL
URLConnection connection = url.openConnection();
//Save the url as an HTML file
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(saveHtmlFilePath), "UTF-8"));
String line;
while ((line = reader.readLine()) != null) {
writer.write(line);
writer.newLine();
}
reader.close();
writer.close();
//Return the file path of the saved HTML file
return saveHtmlFilePath;
}
}
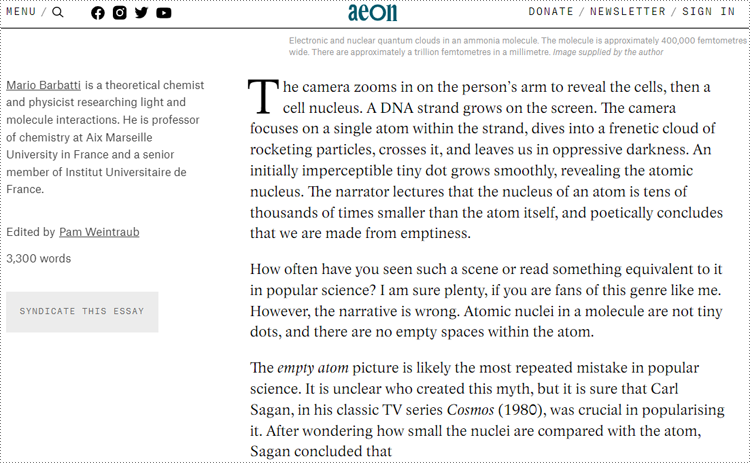
URL Web Page:
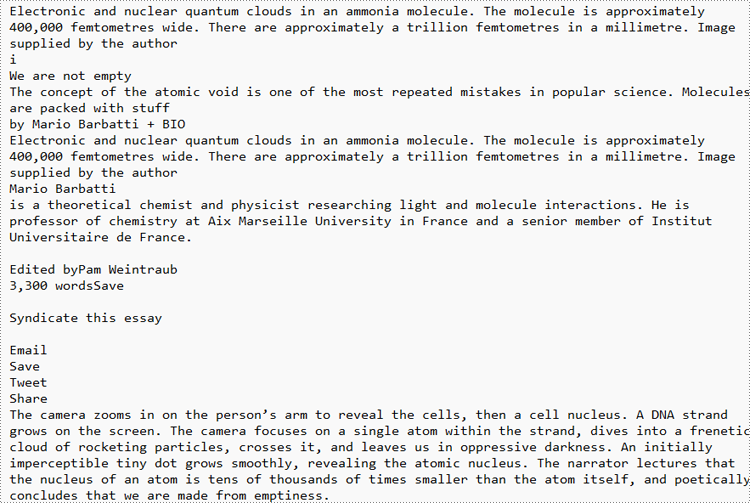
Extracted Text:
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Convert Word to Excel
Word and Excel are different from each other in terms of their uses and functioning. Word is used primarily for text documents such as essays, emails, letters, books, resumes, or academic papers where text formatting is essential. Excel is used to save data, make tables and charts and make complex calculations.
It is not recommended to convert a complex Word file to an Excel spreadsheet, because Excel can hardly render contents in the same way as Word. However, if your Word document is mainly composed of tables and you want to analyze the table data in Excel, you can use Spire.Office for Java to convert Word to Excel while maintaining good readability.
Install Spire.Office for Java
First of all, you're required to add the Spire.Office.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.office</artifactId>
<version>9.10.0</version>
</dependency>
</dependencies>
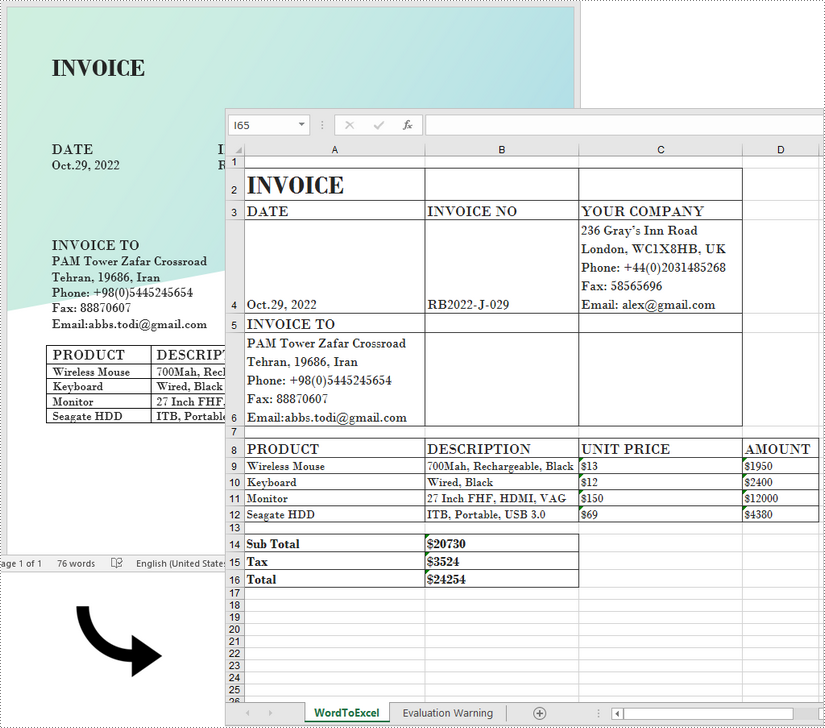
Convert Word to Excel in Java
This scenario actually uses two libraries in the Spire.Office package. They're Spire.Doc for Java and Spire.XLS for Java. The former is used to read and extract content from a Word document, and the latter is used to create an Excel document and write data in the specific cells. To make this code example easy to understand, we created the following three custom methods that preform specific functions.
- exportTableInExcel() - Export data from a Word table to specified Excel cells.
- copyContentInTable() - Copy content from a table cell in Word to an Excel cell.
- copyTextAndStyle() - Copy text with formatting from a Word paragraph to an Excel cell.
The following steps demonstrate how to export data from a Word document to a worksheet using Spire.Office for Java.
- Create a Document object to load a Word file.
- Create a Workbook object and add a worksheet named "WordToExcel" to it.
- Traverse though all the sections in the Word document, traverse through all the document objects under a certain section, and then determine if a document object is a paragraph or a table.
- If the document object is a paragraph, write the paragraph in a specified cell in Excel using coypTextAndStyle() method.
- If the document object is a table, export the table data from Word to Excel cells using exportTableInExcel() method.
- Auto fit the row height and column width in Excel so that the data within a cell will not exceed the bound of the cell.
- Save the workbook to an Excel file using Workbook.saveToFile() method.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.Paragraph;
import com.spire.doc.fields.DocPicture;
import com.spire.doc.fields.TextRange;
import com.spire.xls.*;
import java.awt.*;
public class ConvertWordToExcel {
public static void main(String[] args) {
//Create a Document object
Document doc = new Document();
//Load a Word file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Invoice.docx");
//Create a Workbook object
Workbook wb = new Workbook();
//Remove the default worksheets
wb.getWorksheets().clear();
//Create a worksheet named "WordToExcel"
Worksheet worksheet = wb.createEmptySheet("WordToExcel");
int row = 1;
int column = 1;
//Loop through the sections in the Word document
for (int i = 0; i < doc.getSections().getCount(); i++) {
//Get a specific section
Section section = doc.getSections().get(i);
//Loop through the document object under a certain section
for (int j = 0; j < section.getBody().getChildObjects().getCount(); j++) {
//Get a specific document object
DocumentObject documentObject = section.getBody().getChildObjects().get(j);
//Determine if the object is a paragraph
if (documentObject instanceof Paragraph) {
CellRange cell = worksheet.getCellRange(row, column);
Paragraph paragraph = (Paragraph) documentObject;
//Copy paragraph from Word to a specific cell
copyTextAndStyle(cell, paragraph);
row++;
}
//Determine if the object is a table
if (documentObject instanceof Table) {
Table table = (Table) documentObject;
//Export table data from Word to Excel
int currentRow = exportTableInExcel(worksheet, row, table);
row = currentRow;
}
}
}
//Wrap text in cells
worksheet.getAllocatedRange().isWrapText(true);
//Auto fit row height and column width
worksheet.getAllocatedRange().autoFitRows();
worksheet.getAllocatedRange().autoFitColumns();
//Save the workbook to an Excel file
wb.saveToFile("output/WordToExcel.xlsx", ExcelVersion.Version2013);
}
//Export data from Word table to Excel cells
private static int exportTableInExcel(Worksheet worksheet, int row, Table table) {
CellRange cell;
int column;
for (int i = 0; i < table.getRows().getCount(); i++) {
column = 1;
TableRow tbRow = table.getRows().get(i);
for (int j = 0; j < tbRow.getCells().getCount(); j++) {
TableCell tbCell = tbRow.getCells().get(j);
cell = worksheet.getCellRange(row, column);
cell.borderAround(LineStyleType.Thin, Color.BLACK);
copyContentInTable(tbCell, cell);
column++;
}
row++;
}
return row;
}
//Copy content from a Word table cell to an Excel cell
private static void copyContentInTable(TableCell tbCell, CellRange cell) {
Paragraph newPara = new Paragraph(tbCell.getDocument());
for (int i = 0; i < tbCell.getChildObjects().getCount(); i++) {
DocumentObject documentObject = tbCell.getChildObjects().get(i);
if (documentObject instanceof Paragraph) {
Paragraph paragraph = (Paragraph) documentObject;
for (int j = 0; j < paragraph.getChildObjects().getCount(); j++) {
DocumentObject cObj = paragraph.getChildObjects().get(j);
newPara.getChildObjects().add(cObj.deepClone());
}
if (i < tbCell.getChildObjects().getCount() - 1) {
newPara.appendText("\n");
}
}
}
copyTextAndStyle(cell, newPara);
}
//Copy text and style of a paragraph to a cell
private static void copyTextAndStyle(CellRange cell, Paragraph paragraph) {
RichText richText = cell.getRichText();
richText.setText(paragraph.getText());
int startIndex = 0;
for (int i = 0; i < paragraph.getChildObjects().getCount(); i++) {
DocumentObject documentObject = paragraph.getChildObjects().get(i);
if (documentObject instanceof TextRange) {
TextRange textRange = (TextRange) documentObject;
String fontName = textRange.getCharacterFormat().getFontName();
boolean isBold = textRange.getCharacterFormat().getBold();
Color textColor = textRange.getCharacterFormat().getTextColor();
float fontSize = textRange.getCharacterFormat().getFontSize();
String textRangeText = textRange.getText();
int strLength = textRangeText.length();
ExcelFont font = new ExcelFont(cell.getWorksheet().getWorkbook().createFont());
font.setColor(textColor);
font.isBold(isBold);
font.setSize(fontSize);
font.setFontName(fontName);
int endIndex = startIndex + strLength;
richText.setFont(startIndex, endIndex, font);
startIndex += strLength;
}
if (documentObject instanceof DocPicture) {
DocPicture picture = (DocPicture) documentObject;
cell.getWorksheet().getPictures().add(cell.getRow(), cell.getColumn(), picture.getImage());
cell.getWorksheet().setRowHeightInPixels(cell.getRow(), 1, picture.getImage().getHeight());
}
}
switch (paragraph.getFormat().getHorizontalAlignment()) {
case Left:
cell.setHorizontalAlignment(HorizontalAlignType.Left);
break;
case Center:
cell.setHorizontalAlignment(HorizontalAlignType.Center);
break;
case Right:
cell.setHorizontalAlignment(HorizontalAlignType.Right);
break;
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Convert ODT to PDF
Before you email or share an ODT file with others, you may want to convert the file to PDF in order to make it accessible to anyone across multiple operating systems. In this article, you will learn how to convert ODT to PDF in Java using Spire.Doc for Java.
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.11.0</version>
</dependency>
</dependencies>
Convert ODT to PDF using Java
The following are the steps to convert an ODT file to PDF:
- Create an instance of Document class.
- Load an ODT file using Document.loadFromFile() method.
- Convert the ODT file to PDF using Document.saveToFile(String fileName, FileFormat fileFormat) method.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class ConvertOdtToPdf {
public static void main(String[] args){
//Create a Document instance
Document doc = new Document();
//Load an ODT file
doc.loadFromFile("Sample.odt");
//Save the ODT file to PDF
doc.saveToFile("OdtToPDF.pdf", FileFormat.PDF);
}
}

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Convert XML to Word
An XML file is a plain text file that uses custom tags to display a document's structure and other features. In daily work, you sometimes need to convert Word to XML for storing and organizing data, or convert XML to Word for working on them more easily and efficiently. This article will demonstrate how to programmatically convert XML to Word using Spire.Doc for Java.
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.11.0</version>
</dependency>
</dependencies>
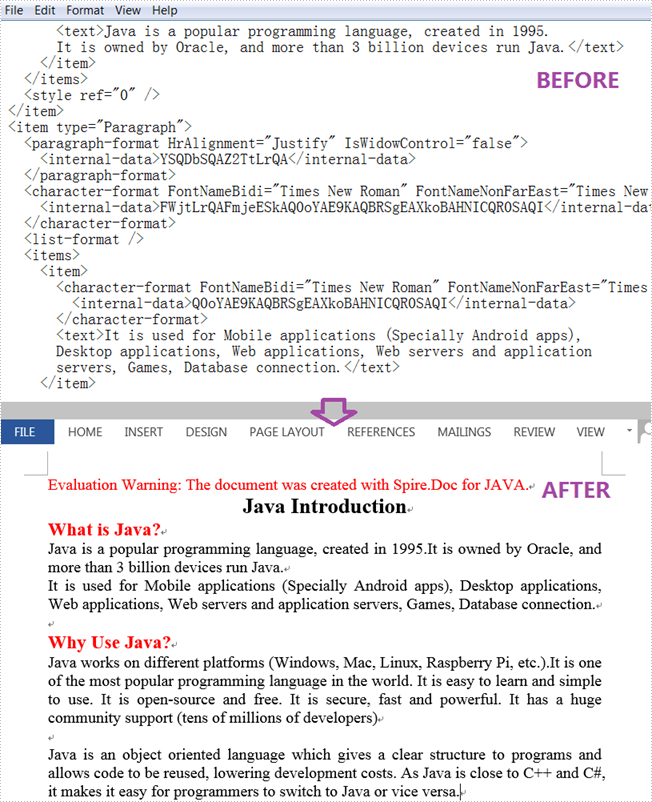
Convert XML to Word
The following are steps to convert XML to Word using Spire.Doc for Java.
- Create a Document instance.
- Load an XML sample document using Document.loadFromFile() method.
- Save the document as a Word file using Document.saveToFile() method.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class XMLToWord {
public static void main(String[] args) {
//Create a Document instance
Document document = new Document();
//Load an XML sample document
document.loadFromFile(sample.xml");
//Save the document to Word
document.saveToFile("output/XMLToWord.docx", FileFormat.Docx );
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Convert RTF to PDF
RTF (Rich Text Format) is a proprietary file format developed by Microsoft for cross-platform document interchange. RTF files have good compatibility and they can be opened by most word processors on any operating system such as Unix, Macintosh, and Windows. In some cases, you may need to convert RTF to other file formats to meet different requirements. In this article, you will learn how to convert RTF to PDF programmatically using Spire.Doc for Java.
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.11.0</version>
</dependency>
</dependencies>
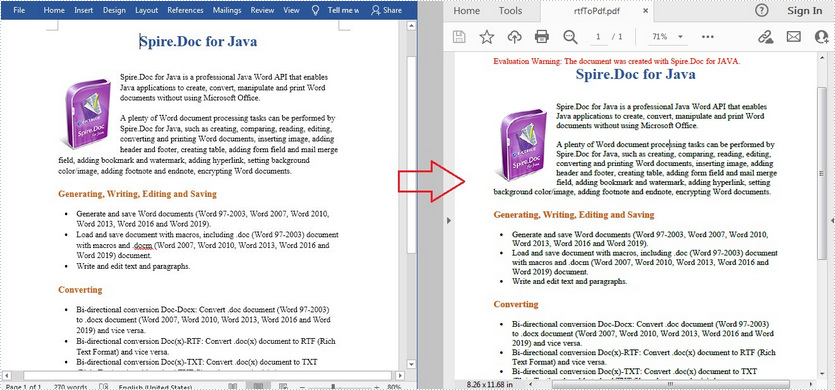
Convert RTF to PDF in Java
The detailed steps are as follows.
- Create a Document instance.
- Load a sample RTF document using Document.loadFromFile() method.
- Save the RTF to PDF using Document.saveToFile() method.
- Java
import com.spire.doc.*;
public class RTFToPDF {
public static void main(String[] args) {
//Create Document instance.
Document document = new Document();
//Load a sample RTF document
document.loadFromFile("sample.rtf", FileFormat.Rtf);
//Save the document to PDF
document.saveToFile("rtfToPdf.pdf", FileFormat.PDF);
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Convert XML to PDF
An Extensible Markup Language (XML) file is a plain text file that uses custom tags to describe the structure and other features of a document. In some cases, you may need to convert XML to PDF because the latter one is easier for others to access. This article will show you how to programmatically convert XML to PDF using Spire.Doc for Java.
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.11.0</version>
</dependency>
</dependencies>
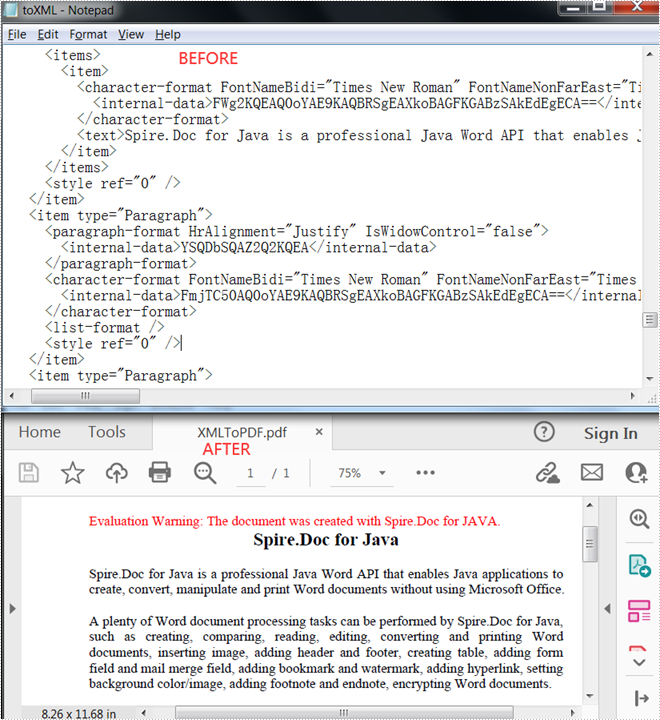
Convert XML to PDF
Spire.Doc for Java supports converting XML to PDF using the Document.saveToFile() method. The following are detailed steps.
- Create a Document instance.
- Load an XML sample document using Document.loadFromFile() method.
- Save the document as a PDF file using Document.saveToFile() method.
- Java
import com.spire.doc.Document;
import com.spire.doc.FileFormat;
public class XMLToPDF {
public static void main(String[] args) {
//Create a Document instance
Document document = new Document();
//Load a XML sample document
document.loadFromFile("toXML.xml");
//Save the document to PDF
document.saveToFile("output/XMLToPDF.pdf", FileFormat.PDF );
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Convert PDF to TIFF
The Tagged Image File Format (TIFF) is a relatively flexible image format which has the advantages of not requiring specific hardware, as well as being portable. Spire.PDF for Java supports converting TIFF to PDF and vice versa. This article will show you how to programmatically convert PDF to TIFF using it from the two aspects below.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>10.10.7</version>
</dependency>
</dependencies>
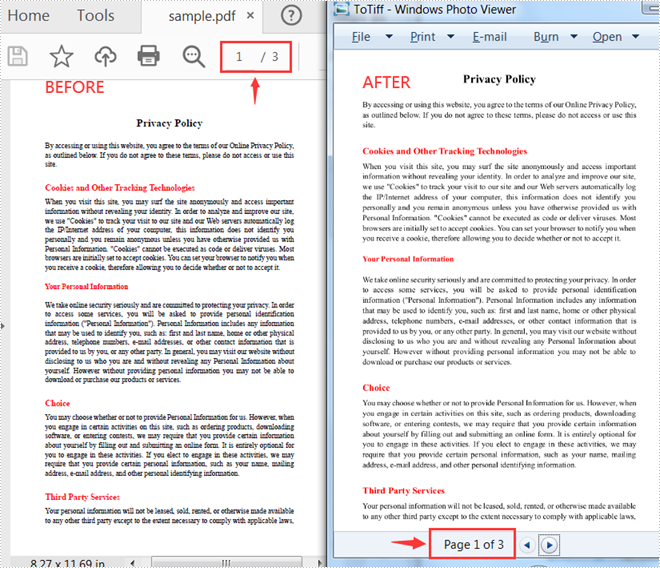
Convert All Pages of a PDF File to TIFF
The following steps show you how to convert all pages of a PDF file to a TIFF file.
- Create a PdfDocument instance.
- Load a PDF sample document using PdfDocument.loadFromFile() method.
- Save all pages of the document to a TIFF file using PdfDocument.saveToTiff(String tiffFilename) method.
- Java
import com.spire.compression.TiffCompressionTypes;
import com.spire.pdf.PdfDocument;
public class PDFToTIFF {
public static void main(String[] args) {
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF sample document
pdf.loadFromFile("sample.pdf");
//Save all pages of the document to Tiff
pdf.saveToTiff("output/PDFtoTiff.tiff");
}
}
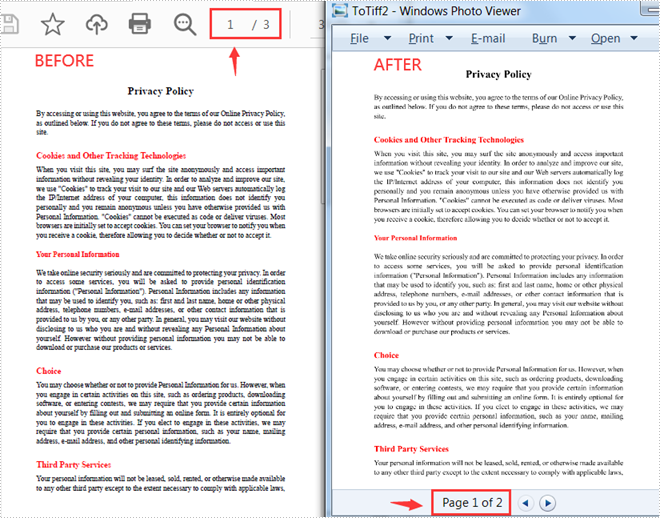
Convert Some Specified Pages of a PDF File to TIFF
The following steps are to convert specified pages of a PDF document to a TIFF file.
- Create a PdfDocument instance.
- Load a PDF sample document using PdfDocument.loadFromFile() method.
- Save specified pages of the document to a TIFF file using PdfDocument.saveToTiff(String tiffFilename, int startPage, int endPage, int dpix, int dpiy) method.
- Java
import com.spire.pdf.PdfDocument;
public class PDFToTIFF {
public static void main(String[] args) {
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF sample document
pdf.loadFromFile("sample.pdf");
//Save specified pages of the document to TIFF and set horizontal and vertical resolution
pdf.saveToTiff("output/ToTiff2.tiff",0,1,400,600);
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Convert HTML to Images
The conversion of HTML files to Image File Formats makes it easier to archive and store HTML pages because images are difficult to alter and can be viewed by virtually anyone. This article will demonstrate how to programmatically convert a HTML file to an image using Spire.Doc for Java.
Install Spire.Doc for Java
First of all, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.11.0</version>
</dependency>
</dependencies>
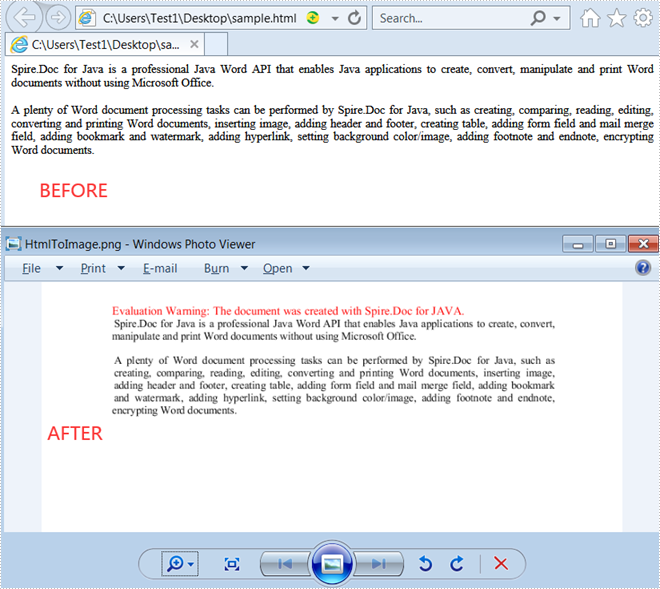
Convert HTML to Image
The following steps show you how to convert a HTML file to an image.
- Create a Document instance.
- Load a sample HTML file using Document.loadFromFile(java.lang.String fileName,FileFormat fileFormat,XHTMLValidationType validationType) method.
- Save the file to Image using Document.saveToImages() method.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class HtmlToImage {
public static void main(String[] args) throws IOException {
//Create a Document instance
Document document = new Document();
//Load a sample HTML file
document.loadFromFile("C:\\Users\\Test1\\Desktop\\sample.html", FileFormat.Html, XHTMLValidationType.None);
//Save to image. You can convert HTML to BMP, JPEG, PNG, GIF, Tiff etc.
BufferedImage image= document.saveToImages(0, ImageType.Bitmap);
String result = "output/HtmlToImage.png";
File file= new File(result);
ImageIO.write(image, "PNG", file);
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.