Table of Contents
Install with Pip
pip install Spire.PDF
Related Links
PDF files are a popular choice for sharing and distributing documents, but it can be quite challenging to extract and repurpose PDF content. Fortunately, converting PDF files to HTML with Python offers an excellent solution for PDF information retrieval and repurposing, which enhances accessibility, searchability, and adaptability. Additionally, HTML format enables search engines to index the content, making it more likely to be discovered on the web. What’s more, with Python's flexibility and ease of use, both beginners and experienced developers can use Python to convert PDF to HTML easily and efficiently.

This article focuses on how to convert PDF to HTML in Python programs. It mainly includes the following topics:
- Overview of Converting PDF to HTML with Python
- Convert PDF to a Single HTML File with Python Code
- Convert PDF to HTML with Images Separated Using Python
- Convert PDF to Multiple HTML Files with Python
- Free License and Technical Support
Overview of Converting PDF to HTML with Python
Python's extensive APIs provide convenience for various PDF document processing operations. Spire.PDF for Python is one of the powerful APIs that can perform various operations on PDF documents, including converting, editing, and merging PDF documents. And, converting PDF to HTML with Python can be implemented effortlessly with this API.
In Spire.PDF for Python, the PdfDocument class represents a PDF document. We can load a PDF file using the LoadFromFile() method under this class and save the document in other formats, like HTML, to achieve simple conversion from PDF to HTML.
Moreover, this API also provides the SetConvertHtmlOptions() method under the PdfDocument.ConversionOptions property to set the image embedding options during the conversion. Below are the parameters that can be passed to this method to set the maximum page number, SVG embedding option, image embedding option, and SVG quality option:
- useEmbeddedSvg (bool): When set to True, it allows embedding SVG in the converted HTML file. The resulting HTML file will include all elements from the PDF document, including images, in a single HTML file.
- useEmbeddedImg (bool): When set to True, it allows embedding images in the converted HTML file. This parameter only works if useEmbeddedSvg is set to False.
- maxPageOneFile (int): Sets the maximum number of pages to include in a single HTML file. If the PDF has more pages than the specified number, multiple HTML files will be generated, each containing a subset of the pages.
- useHighQualityEmbeddedSvg (bool): When set to True, ensures the use of high-quality versions of embedded SVG images in the HTML conversion process.
Typical workflow of converting PDF to HTML in Python using Spire.PDF for Python:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile(string fileName) method.
- Set the conversion options using PdfDocument.ConversionOptions.SetConvertHtmlOptions() method.
- Convert the document to HTML format and save it using PdfDocument.SaveToFile(string fileName, FileFormat.HTML) method.
Users can download Spire.PDF for Python and import it to their projects, or install it with PyPI:
pip install Spire.PDF
Convert PDF to a Single HTML File with Python Code
This code example shows how to convert PDF to HTML with Python directly without setting any conversion options. In this case, we only need to load a PDF file with the LoadFromFile method and save it as an HTML file with the SaveToFile method. The converted HTML file will be a single HTML file with images and other elements embedded in it.
Code Example:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("G:/Documents/ARCHITECTURE.pdf")
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTML.html", FileFormat.HTML)
doc.Close()
Conversion Result:
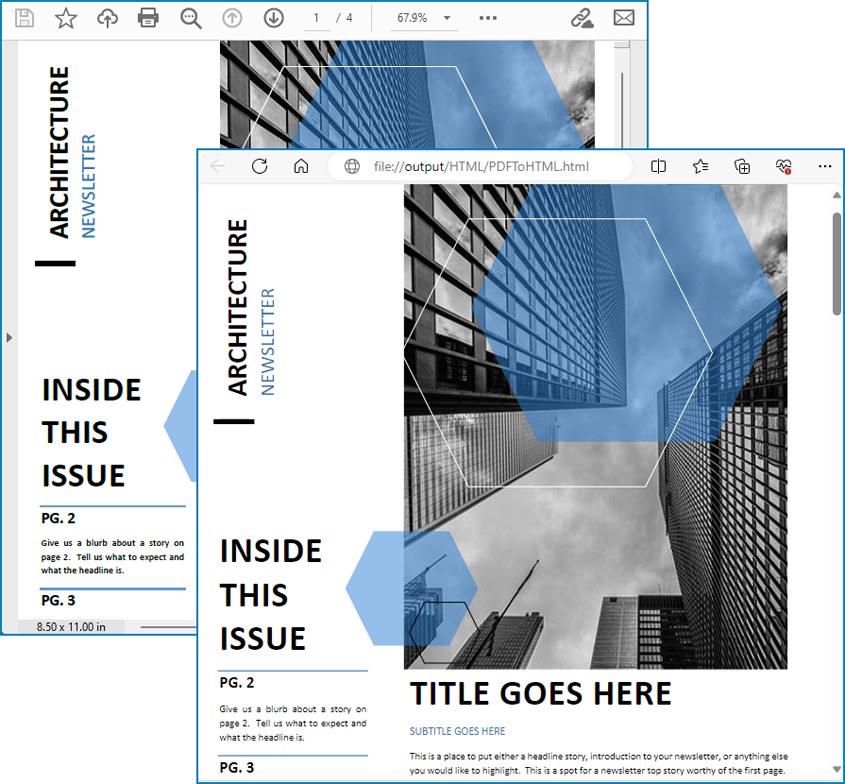
Convert PDF to HTML with Images Separated Using Python
By setting the useEmbeddedSvg parameter to False, we can convert the PDF document into an HTML file with images and CSS files separated from it and stored in a folder. This makes it convenient to further edit the converted HTML file and perform additional operations on the images.
Code Example:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLWithoutEmbeddingSVG.html", FileFormat.HTML)
doc.Close()
Conversion Result:
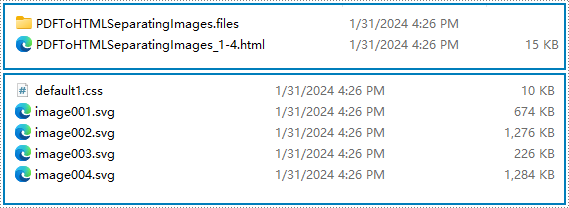
Convert PDF to Multiple HTML Files with Python
With the precondition that useEmbeddedSvg is set to False, the SetPdfToHtmlOptions method allows for the use of the maxPageOneFile (int) parameter to determine the maximum number of pages included in each converted HTML file. This feature enables PDF document splitting in the conversion process. For instance, setting the parameter to 1 will result in each page being converted into a separate HTML file.
Code Example:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False, False, 1, False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLLimitingPage.html", FileFormat.HTML)
doc.Close()
Conversion Result:
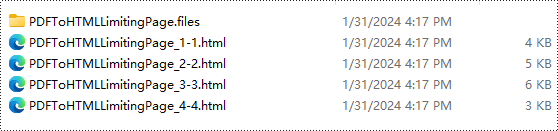
Free License and Technical Support
Spire.PDF for Python offers users a free license for trial to all users, including both enterprise and individual users. Apply for a temporary license to use this Python API for converting PDF documents to HTML files, removing any usage restrictions or watermarks.
For any issues encountered during the PDF to HTML conversion using this API, users can seek technical support on the Spire.PDF forum.
Conclusion
This article demonstrates how to convert PDF to HTML using Python and provides various conversion options, such as converting to a single HTML file, separating HTML files from images, and splitting the PDF document during conversion. With Spire.PDF for Python, users have access to a straightforward and efficient method for Python in PDF to HTML conversion, supporting flexible customization options.
