Table of Contents
Install with Pip
pip install Spire.PDF
Related Links
In today's digital age, the ability to extract information from PDF documents quickly and efficiently is crucial for various industries and professionals. Whether you're a researcher, data analyst, or simply dealing with a large volume of PDF files, being able to convert PDFs to editable text format can save you valuable time and effort. This is where Python, a versatile and powerful programming language, comes to the rescue with its extensive features for converting PDF to text in Python.

In this article, we will explore how to use Python for PDF to text conversion, unleashing the power of Python in PDF file processing. This article includes the following topics:
- Python API for PDF to Text Conversion
- Guide for Converting PDF to Text in Python
- Python to Convert PDF to Text Without Keeping Layout
- Python to Convert PDF to Text and Keep Layout
- Python to Convert a Specified PDF Page Area to Text
- Get a Free License for the API to Convert PDF to Text in Python
- Learn More About PDF Processing with Python
Python API for PDF to Text Conversion
To use Python for PDF to text conversion, a PDF processing API – Spire.PDF for Python is needed. This Python library is designed for PDF document manipulation in Python programs, which empowers Python programs with various PDF processing abilities.
We can download Spire.PDF for Python and add it to our project, or simply install it through PyPI with the following code:
pip install Spire.PDF
Guide for Converting PDF to Text in Python
Before we proceed with converting PDF to text using Python, let's take a look at the main advantages it can offer us:
- Editability: Converting PDF to text enables you to edit the document more easily, as text files can be opened and edited on most devices.
- Accessibility: Text files are generally more accessible than PDFs. Whether it's a desktop or mobile phone, text files can be viewed on devices with ease.
- Integration with other applications: Text files can be seamlessly integrated into various applications and workflows.
Steps for converting PDF documents to text files in Python:
- Install Spire.PDF for Python.
- Import modules.
- Create an object of PdfDocument class and load a PDF file using LoadFromFile() method.
- Create an object of PdfTextExtractOptions class and set the text extracting options, including extracting all text, showing hidden text, only extracting text in a specified area, and simple extraction.
- Get a page in the document using PdfDocument.Pages.get_Item() method and create PdfTextExtractor objects based on each page to extract the text from the page using Extract() method with specified options.
- Save the extracted text as a text file and close the PdfDocument object.
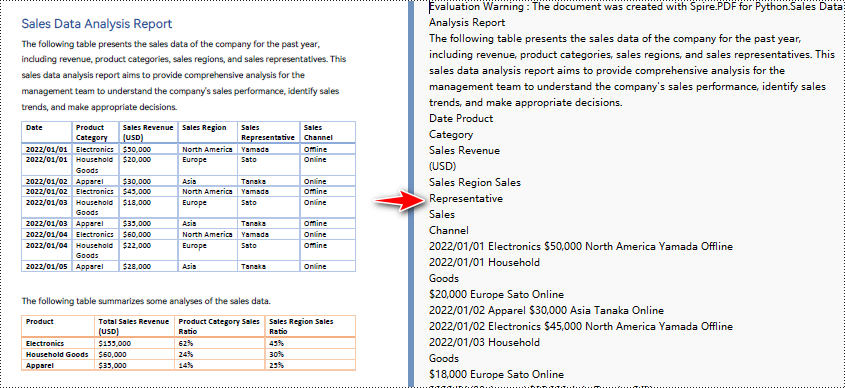
Python to Convert PDF to Text Without Keeping Layout
When using the simple extraction method to extract text from PDF, the program will not retain the blank areas and keep track of the current Y position of each string and insert a line break into the output if the Y position has changed.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
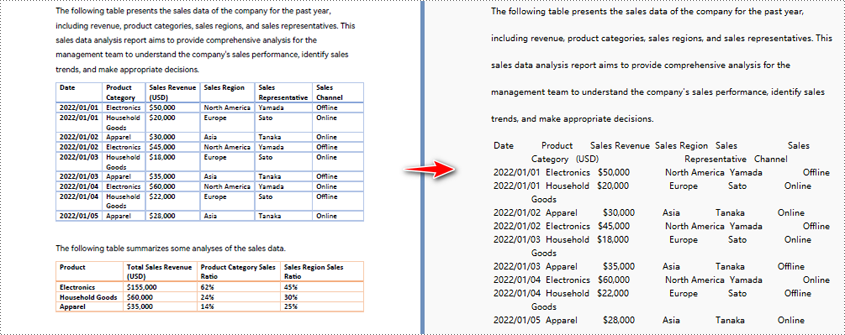
Python to Convert PDF to Text and Keep Layout
When using the default extraction method to extract text from PDF, the program will extract text line by line including blanks.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
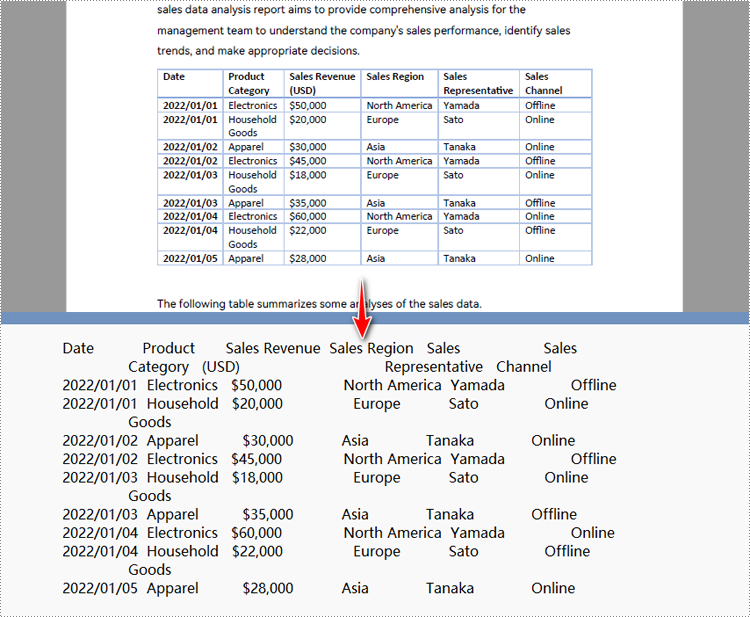
Python to Convert a Specified PDF Page Area to Text
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Get a Free License for the API to Convert PDF to Text in Python
Users can apply for a free temporary license to try Spire.PDF for Python and evaluate the Python PDF to Text Conversion features without any limitations.
Learn More About PDF Processing with Python
Apart from converting PDF to text with Python, we can also explore more PDF processing features of this API through the following sources:
- How to Extract Text from PDF Documents with Python
- Tutorials for PDF Processing with Python
- Converting Image-Based PDF Documents to Text (OCR)
Conclusion
In this blog post, we have explored Python in PDF to text conversion. By following the operational steps and referring to the code examples in the article, we can achieve fast PDF to text conversion in Python programs. Additionally, the article provides insights into the benefits of converting PDF documents to text files. More importantly, we can gain further knowledge on handling PDF documents with Python and methods to convert image-based PDF documents to text through OCR tools from the references in the article. If any issues arise during the usage of Spire.PDF for Python, technical support can be obtained by reaching out to our team via the Spire.PDF forum or email.
